




 本文提出DARTSformer,一种针对Transformer的可微架构搜索方法,通过多分割可逆网络降低内存消耗。在保持高性能的同时,DARTSformer能搜索更大隐藏层维度和更多候选操作,实验结果显示其在多种seq2seq任务中超越标准Transformer并减少计算量。
本文提出DARTSformer,一种针对Transformer的可微架构搜索方法,通过多分割可逆网络降低内存消耗。在保持高性能的同时,DARTSformer能搜索更大隐藏层维度和更多候选操作,实验结果显示其在多种seq2seq任务中超越标准Transformer并减少计算量。
DARTSformer:内存高效的Transformer可微架构搜索
Abstract
DARTS可微架构搜索已成功用于诸多计算机视觉任务,由于Transformer的计算十分消耗内存,限制了NAS的搜索过程,因此本文提出一种多分割可逆网络,可以使用DARTS进行架构搜索。
具体来说,本文设计了一个反向传播-重建算法,只需要存储最糊一层的输出即可;这样减轻了DARTS的内存需求,从而可以在更大的隐藏层维度、更多的候选操作中搜索。
本文在三种seq2seq数据集上进行了测试,实验结果显示本文网络在整个任务中始终优于标准的Transformer,并且将计算量减少了一个量级。
Section I Introduction
NAS搜索的模型在许多方面优于人工设计的结构。对于序列处理任务,有通过强化学习、进化学习等方法进行搜索,但十分消耗计算资源;而基于梯度的方法由于计算量小、易于实现,受到了许多研究人员的青睐。
基于梯度的NAS主要思路是训练一个涵盖所有候选操作的超网,然后超网下的不同子网络构成了整个搜索空间。
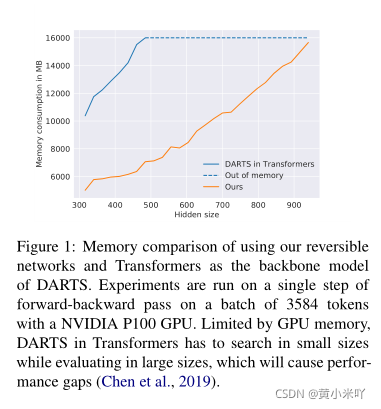
为了找到性能优异的子网络,DARTS通过引入搜索参数将离散的优化问题连续化,搜索后,每个中间节点会保留最大搜索参数 对应的操作。DARTS的一大限制条件就是其内存效率低下,因为需要存储大量的候选操作。当将DARTS应用到Transformer时这一问题更加突出,从Fig 1可以看出随着hidden size的增大,内存增长十分迅速,很快就耗尽了,因此只能使用较小的hidden size,这样会影响模型性能。
为了解决DARTS的内存消耗问题,本文提出一种可逆网络的变体,每一个可逆网络层的输入可以从输出中重构得到,这样就无须存储所有中间层的输出,而只需要存储最后一层的即可。
受RevNets的启发,本文提出了一个多划分可逆网络,每一次split都会进行一次节点的操作搜索,而重建的时候只需要对BP做少量修改就可进行梯度计算。Fig 1展示了本文方法的内存消耗,可以看到是DARTS的一半,即在相同的内存约束下,可以搜索具有更多候选操作、更丰富的网络。
本文的方法可以通用处理各种网络结构,本文则聚焦于seq2seq模型,会在WMT14数据集上进行搜索然后在WMT14三类其他语言翻译数据集上进行重训练。实验结果显示DARTSformer在所有任务中都比Transformer有所提升,并且达到同等精度时参数量少了69%;与Evolved Transformer相比计算量则是降了一个数量级。
Section II Methodology
Part 1 DARTS in Transformer
操作集合O中包含了所有的候选操作,如self-attention,FFN,Zero,DARTS的核心是使用混合操作搜索节点f(X)来驰预对候选操作的离散选择,即通过softmax将离散问题连续化:
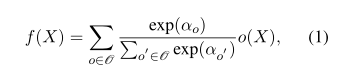
其中α就是要训练的参数,决定了混合权重。
搜索过程中每一层block都包含多个搜索节点,搜索任务就是寻找每一个节点最佳的α,搜索结束后每个节点的操作由下式决定:
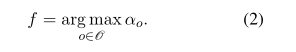
本文通过梯度下降同时优化网络权重θ和α,损失函数为:
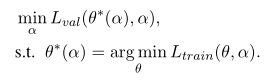
通过将Transformer中的全部或部分节点替换为混合操作搜索节点就可以直接应用DARTS,比如将transformer decoder block中的self-attention,FFN替换为Search Node即可,而搜索结算的输出是不同操作的加权和;为了反向传播就需要存储每个操作的输出,也是因为这个原因导致在搜索过程中内存急剧上升。
Part 2 Multi-Split Reversible Networks
为了减少Transforemer进行DARTS搜索时对内存的需求,本文使用了可逆网络。可逆网络每层的输入可以根据输出重建,假设一个网络包含多层可逆层,我们并不需要保存中间层的输出,只需要保存最后一层的输出即可,其他层的可以在BP过程中重建。
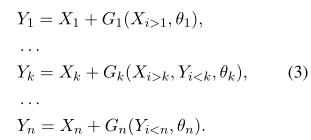
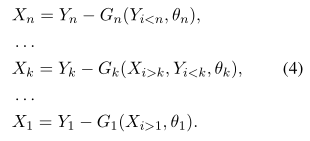
假设X和f(X)分别是某一层的输入和输出,X首先会沿着嵌入或轴(embedding/channel)的方向被等分成n份,然后对每一份进行类似RevNet中的操作,输出f(X)则是{Y1,…,Yn}的级联。
Gk就是训练阶段的混合操作节点,训练结束后Gk取argmax的最大值。
而Eq3的逆操作需要严格的证明,从而根据F(X)重建输入X。
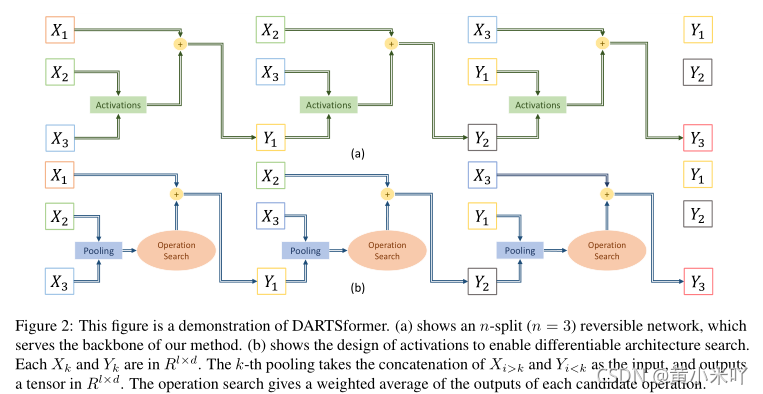
Fig 2展示了n=3时可逆网络的计算流程。每一次pooling会将Xi>k和Yi<k级联的结果作为输入,输出一个向量,最终输出的是每个候选操作的加权和。
Part 3 Backpropagation with Reconstruction
接下来考虑如何实现可逆层的反向传播,由于每一层的输出f(X)是各个xi输出的级联,梯度表示为:
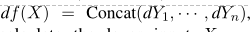
因此总的X的梯度表示为:
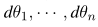
根据Algorithm 1的伪代码,可以看到dθk包含一个偏置项,grad k则会累加每个梯度,通过重复算法1就可以获得所有输入的梯度,而只需要存储最后一层的输出,因此是内存高效的。
简单地说,对于有N个连接的网络,前向和反向传播大概分别需要N到2N次乘加操作,在进行重建时有需要进行N次操作;而借助算法1在反向传播过程中就能重建输入,收敛的也会更快,计算开销也不再是瓶颈。

Part 4 DARTS with Multi-split Reversible Networks
为了进行DARTS需要计算Eq3中每个Gk的值,Gk的维度首先要确定。
其次Gk被分解成两部分,第一部分是pooling,输入ldn(n-1)维度的向量作为输入,输出维度ldn1;第二部分执行混合节点操作:
将Gk用Eq5的结果替换,这样就可以按照logrithm 1执行DARTS。
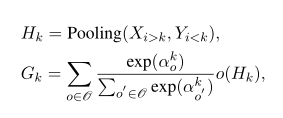
DARTSformer的性能严重依赖于搜索空间,本文实验聚焦于seq2seq任务因此decoder和encoder是同时搜索的,主要搜索的是每一个模块内的层数s以及encoder/decoder被分成几份。在搜索空间足够大的前提下,即使m,n,s很小也有足够的搜索空间。
Part 5 Instantiation
’
操作集合:
标准卷积{3,5,7,11}
可变卷积{3,7,11,15}
self-attention
Cross Attention(只在decoder使用)
GLU
FFN
Zero
Identity
虽然LN和残差连接有助于Transformer的收敛,但是无法直接应用在本文,因此本文替换为Zero操作和Identity操作。
搜索设置
整个网络架构的搜索在WMT14 En-De上进行,DARTS是一个两阶段的过程,在一个数据集上权重更新,在另一个数据集上搜索alpha参数
损失函数为交叉熵损失函数,encoder分割数位2,decoder分割数为3.
由于DARTSformer中还用到了池化操作,本文对最大池化和均值池化均进行了测试。
Section III Experiment Setup
数据集:
WMT18 En-De
WMT14 En-Fr
WMT18 En-Cs
搜索设置
整个网络架构的搜索在WMT14 En-De上进行,DARTS是一个两阶段的过程,在一个数据集上权重更新,在另一个数据集上搜索alpha参数
损失函数为交叉熵损失函数,encoder分割数位2,decoder分割数为3.
由于DARTSformer中还用到了池化操作,本文对最大池化和均值池化均进行了测试。
训练细节
所有网络会在WMT14 En-De上重训练,然后在三个数据集上测试搜索网路的泛化性能。并且设置了三种不同规模的网络(base,big),使用8块V100进行训练。
Section IV Results
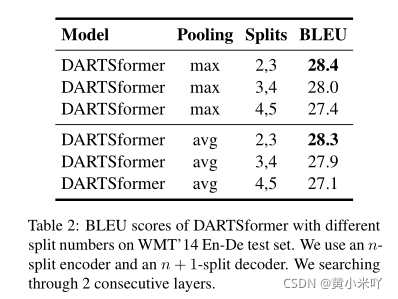
Table 1展示了不同池化方法下的性能对比,ET代表Evolved Transformer,可以看到DARTSformer比所有标准Transformer的性能都要好,最佳设定是使用max-pooling,连续2层的设定。
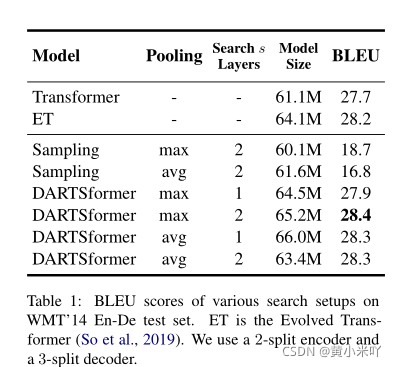

此外本文还对比了DARTSformer和ET的搜索成本,DARTSformer耗时40小时,单次搜索成本为1.25k,8块V100就够了’而ET单次搜索成本则是150k,需要200块TPU。
ET搜索成本高的原因在于需要对每一个候选子网络进行训练。
Table 3显示的是两种方法参数更新次数的对比。
本文还发现通过采样的方法更适合于卷积核较大的情形,这样产生的框架容易产生重复的句子。
Table 2还罗列了分割数n对性能的影响。可以看到分割数越大性能下降的越厉害,由于搜索空间变大也更加难以收敛,重训练和推理的速度也会变慢。
接下来的实验则是测试搜索出来的框架(DARTSformer+search 2layers+2 split+max pooling)在不同任务上的性能。
Part 1 DARTSformer
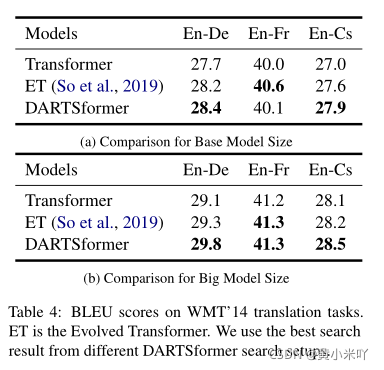
首先本文将搜索得到的网络架构测试在不同数据集上的性能来测试搜索结果的泛化性;其次探究网络大小以及batch size大小对网络性能的影响,Table 4展示了不同model sizex下(base,big)与其他网络的性能对比。 可以看到DARTSformer的性能均优于原始Transformer和ET。
Part 2 Performance vs Parameter Size
本文还探究了在模型尺寸较小时DARTSformer的性能是否还能提升,因此测试了不同的embedding size[small:128,medium:256,base:512,big:1024]
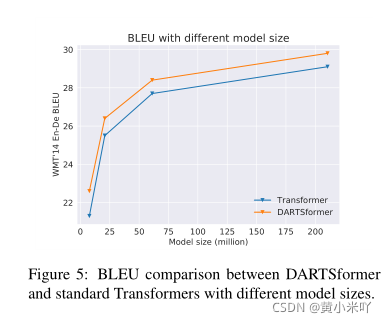
Fig 5展示了不同size下DARTSformer和Transformer的对比结果,可以看到size越大两种模型之间的性能差距越小。
基于这一实验结果,DARTSformer更适合于资源受限的应用场景,如手机;大尺寸差距变小的一个可能原因是过拟合造成的影响。本文认为通过一些数据增强的手段可以帮助改善这一现象。
Part 3 Hidden Size的影响
本文的主要目的是能够有更大的hidden size,更大的搜索空间,减少搜索和重训练之间的性能差距。但是这种gap是否存在还需严格的验证,否则在搜索时使用较小的d在re-train时增加d就足够了。
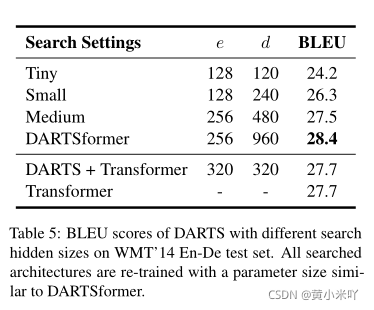
本文测试了4种不同的hidden size,Table 5是对比结果,可以看到随着hidden size的增大翻译性能也获得了提升;而且使用Tiny,Small,Medium尺寸的网络时性能低于标准的Transformer,说明如果想要在大型模型中搜索网路,需要使用较大的hidden size此外,本文还直接在标准Transformer上使用DARTS搜索,由于较大的隐藏层设置一般会导致内存溢出,从Table 5也可以看出,在标准Transformer使用较小的hidden size并不能带来性能上的提升。
Section V Related Work
NAS
早期的神经架构搜索主要基于强化学习和进化算法,这样搜索出的网络结构往往优于手工设计的网络;但是由于需要验证每一个子网络的性能,会消耗巨大的计算资源。借助权重共享一份解决了这一问题;而DARts的提出则将离散的搜索问题连续化,从而可以借助梯度下降进行优化,因为基于梯度的算法消耗的计算量更小使得这一系列方法吸引了大量研究热情。
本文则在DARTS的基础上进一步减少了对内存的需求;另一主流的研究趋势是one-stage NAS,因为目前主要的NAS都是两阶段,即第一阶段搜索到候选网络;第二阶段再重训练候选网络。One-stage NAS可以同时搜索和优化网络权重。
Reversible networks
RevNet最初提出的可逆残差网络,随后诸多学者进一步探究了可逆网络的其他变体,如可逆RNN,结合local attention等;可逆网络的一个重要应用是基于流的模型,如将其用于序列处理任务-非-自回归机器翻译。
Section VI Conclusion
本文提出了计算更高效的DARTSformer,将DARTS用于Transformer的搜索,来处理seq2seq任务。具体,本文提出了多分割可逆网络,其中间层的输出可以根据最后一层的输出重建,将这种方法与DARTS结合,提出了BP-with-reconstruction算法,有效的降低了DARTS搜索过程中对内存的需求。并且在三种数据集上验证了DARTSformer的有效性。
本文提出的方法始终优于标砖Transformer,或者在达到相同精度下参数量减少69%。在大尺寸模型中,DARTSformer性能超过了Evolved Transformer并且计算量减少了一个量级。本文致力于提出一个适用各种框架的通用搜索方法,因此会在未来继续探索更多的任务。

















 2528
2528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









