






朴素贝叶斯(Navie Bayes):
朴素贝叶斯是贝叶斯决策理论的一部分,之所以称之为“朴素”,其原因在于该算法以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提。
贝叶斯决策理论

假设数据集由两类数据组成,数据分布如上图,现在用表示数据点
属于类别1(图中红色圆点表示的类别)的概率,用
表示数据点
属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点
,可以用下面的规则来判断它的类别:
如果>
,那么类别为1
如果<
,那么类别为2
贝叶斯决策理论的核心思想为选择具有最高概率的决策。接下来就是考虑如何计算p1和p2概率。
条件概率:
在学习计算p1 和p2概率之前,需要了解什么是条件概率(Conditional probability),来表示在事件B发生的情况下,事件A发生的概率。
朴素贝叶斯基于以下假设:
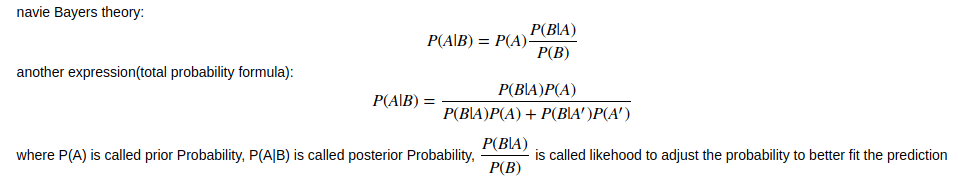
对于n个特征的贝叶斯理论,存在如下公式:
通常概率容易求得且分母相同,因此为简单计算故省略。
值得注意的是,如果,则
= 0与实际不符合,需要进行修正调整。即假设初始条件下的
,为避免下溢现象(小数越乘越小而接近0)需要进行对数化运算,进而避免舍入误差(著名的极大似然估计原理就采用了对数化求最值同时化简运算的目的)。
由此,可设计基于贝叶斯理论的分类器模型编程实现。这里以简单的词性检测为例,检测语句中是否含有敏感单词。
import numpy as np
from functools import reduce
'''
Function : createData()
Description : to create train dataSet
Args : None
Rets : postingList, labelVector
'''
def createData():
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
labelVector = [0, 1, 0, 1, 0, 1]
return postingList, labelVector
'''
Function : createWordList(postingList)
Description : to convert postingList to word list
Args : postingList
Rets : wordList
'''
def createWordList(postingList):
wordSet = set([])
for doc in postingList:
wordSet = wordSet | set(doc)
return list(wordSet)
'''
Function : words2Vector(wordList, subSet)
Description : to convert words to vector
Args : wordList
subSet
Rets : wordVector
'''
def words2Vector(wordList, subSet):
wordVector = [0] * len(wordList)
for word in subSet:
if word in wordList:
wordVector[wordList.index(word)] = 1
else:
print('the word %s is not in wordList'%(word))
return wordVector
'''
Function : navieBayes(trainMatrix, labelVector)
Description : to adapt navieBayes method
Args : trainMatrix
labelVector
Rets : cp_0, cp_1, p_abusive
'''
def navieBayes(trainMatrix, labelVector):
numTrains = len(trainMatrix)
numWords = len(trainMatrix[0])
#pre probility
p_abusive = sum(labelVector) / float(numTrains)
'''
nump_0 = np.zeros(numWords)
nump_1 = np.zeros(numWords)
'''
nump_0 = np.ones(numWords)
nump_1 = np.ones(numWords)
'''
demo_0 = 0.0
demo_1 = 0.0
'''
demo_0 = 2.0
demo_1 = 2.0
for i in range(numTrains):
if labelVector[i] == 1:
nump_1 += trainMatrix[i]
demo_1 += sum(trainMatrix[i])
else:
nump_0 += trainMatrix[i]
demo_0 += sum(trainMatrix[i])
'''
cp_1 = nump_1 / demo_1
cp_0 = nump_0 / demo_0
'''
cp_1 = np.log(nump_1 / demo_1)
cp_0 = np.log(nump_0 / demo_0)
return cp_0, cp_1, p_abusive
'''
Function : train(testVector, cp_0, cp_1, p_abusive)
Args : testVector
cp_0
cp_1
p_abusive
Rets : True or False (whether the testVector belongs to abusive words)
'''
def train(testVetctor, cp_0, cp_1, p_abusive):
'''
p_0 = reduce(lambda x, y: x * y, testVetctor * cp_0) * (1 - p_abusive)
p_1 = reduce(lambda x, y: x * y, testVetctor * cp_1) * p_abusive
print('p_0: \n', p_0)
print('p_1: \n', p_1)
'''
p_0 = sum(testVetctor * cp_0) + np.log(1 - p_abusive)
p_1 = sum(testVetctor * cp_1) + np.log(p_abusive)
if p_1 > p_0:
return True
else:
return False
if __name__ == '__main__':
postingList, labelVector = createData()
for each in postingList:
print(each)
print('labelVector : \n', labelVector)
wordList = createWordList(postingList)
print('wordList: \n', wordList)
trainMatrix = []
for subSet in postingList:
trainMatrix.append(words2Vector(wordList, subSet))
print('trainMatrix : \n', trainMatrix)
cp_0, cp_1, p_abusive = navieBayes(trainMatrix, labelVector)
print('cp_0: \n', cp_0)
print('cp_1: \n', cp_1)
print('p_abusive: \n', p_abusive)
#test = ['love', 'my', 'dalmation']
test = ['stupid', 'worthless', 'garbage']
testVetctor = words2Vector(wordList, test)
if train(testVetctor, cp_0, cp_1, p_abusive):
print(testVetctor, 'belongs to abusive words')
else:
print(testVetctor, 'not belongs to abusive words')实验结果:

朴素贝叶斯算法是有监督的学习算法,解决的是分类问题,如客户是否流失、是否值得投资、信用等级评定等多分类问题。该算法的优点在于简单易懂、学习效率高、在某些领域的分类问题中能够与决策树、神经网络相媲美。
朴素贝叶斯优点:
1、生成式模型,通过计算概率来进行分类,可以用来处理多分类问题;
2、对小规模的数据表现很好,适合多分类任务,适合增量式训练,算法也比较简单;
朴素贝叶斯缺点:
1、对输入数据的表达形式很敏感;
2、由于朴素贝叶斯的“朴素”特点,所以会带来一些准确率上的损失;
3、需要计算先验概率,分类决策存在错误率;















 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









