







本文涉及以下内容
1. pandas数据处理、筛选、计算
2. 复杂的表格数据计算与处理
3. 文本分析与无监督学习
4. 将计算结果输出表格
5. 数据特征对比
赛题


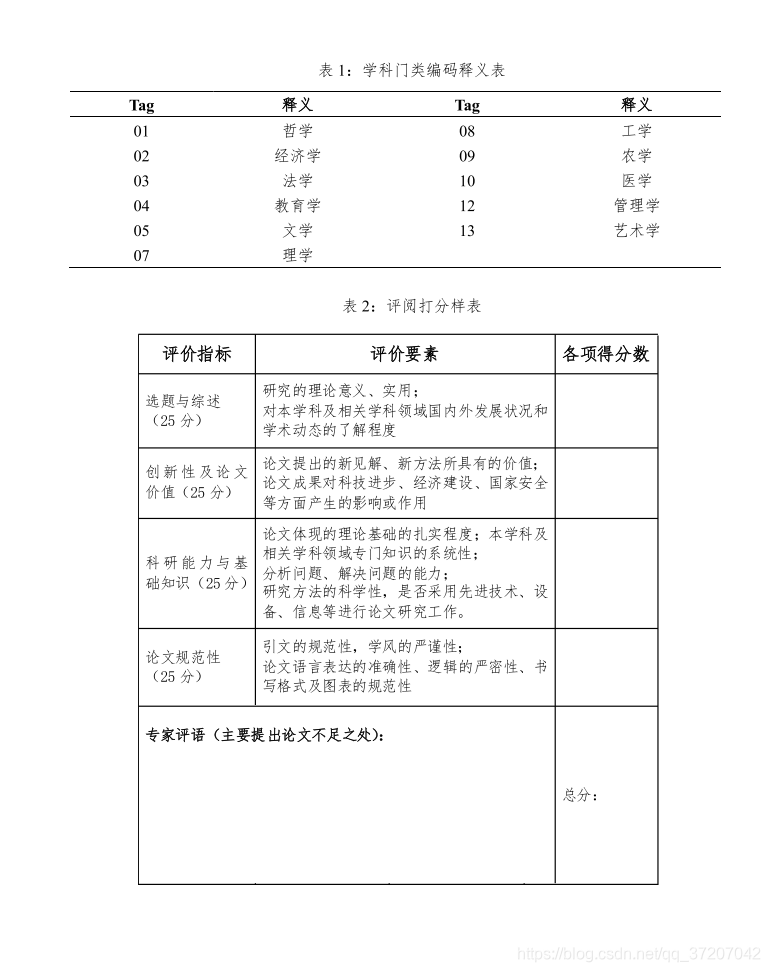
思路










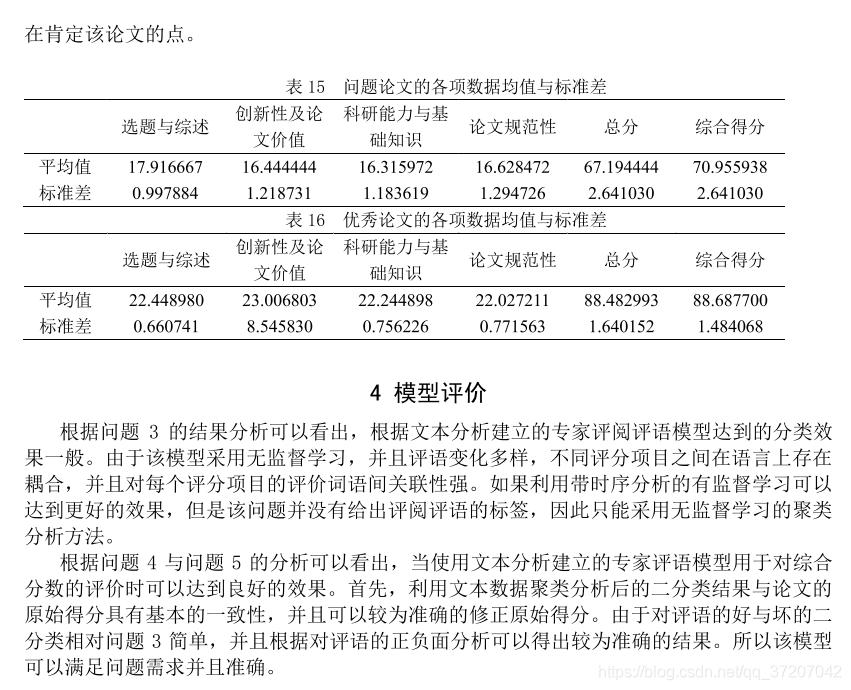
代码
将excel文件中的文本数据转入txt文件
# -*- coding: utf-8 -*-
"""
Created on Sun May 23 13:36:06 2021
@author: MYM
"""
import numpy as np
import pandas as pd
# read xlsx
data = pd.read_excel('附件1.xlsx')
text = open("C:/Users/MYM/My_python_codes/DSA/text_words.txt",'w', encoding='GB2312',errors='ignore')
text_R = data[['R1','R2','R3']]
count = 0
for s in text_R['R1']:
if pd.isnull(s) or type(s) == int:
print('nan')
count = count + 1
else:
s = s.replace("\n",',')
text.write(s)
text.write('\n')
for s in text_R['R1']:
if pd.isnull(s) or type(s) == int:
print('nan')
count = count + 1
else:
s = s.replace("\n",',')
text.write(s)
text.write('\n')
for s in text_R['R1']:
if pd.isnull(s) or type(s) == int:
print('nan')
count = count + 1
else:
s = s.replace("\n",',')
text.write(s)
text.write('\n')
text.close()
# for i in range(1246):
# s = text_R.loc[i,'R1']
# if pd.isnull(s) or type(s) == int:
# print('nan')
# else:
# s = s.replace("\n",',')
# text.write(s)
# text.write('\n')
# for i in range(1246):
# s = text_R.loc[i,'R2']
# if pd.isnull(s) or type(s) == int:
# print('nan')
# else:
# s = s.replace("\n",',')
# text.write(s)
# text.write('\n')
# for i in range(1246):
# s = text_R.loc[i,'R3']
# if pd.isnull(s) or type(s) == int:
# print('nan')
# else:
# s = s.replace("\n",',')
# text.write(s)
# text.write('\n')
# text.close()
问题1的程序
# -*- coding: utf-8 -*-
"""
Created on Sat May 22 14:48:36 2021
@author: MYM
"""
import pandas as pd
import numpy as np
def get_ave(df1, T_num):
data = df1.values
ave_data = data.sum(axis = 1) / T_num
return ave_data
# read xlsx
data = pd.read_excel('附件1.xlsx')
data_get = pd.read_excel('附件2.xlsx')
Num = len(data) # 样本数目
T_num = 3 # the number of teacher
percent = 5 # 筛选 末尾 5%
# 获取特定的列
X = data[['X1','X2','X3']]
Xk1 = data[['X11','X21','X31']]
Xk2 = data[['X12','X22','X32']]
Xk3 = data[['X13','X23','X33']]
Xk4 = data[['X14','X24','X34']]
X_ave = get_ave(X, T_num)
Xk1_ave = get_ave(Xk1, T_num)
Xk2_ave = get_ave(Xk2, T_num)
Xk3_ave = get_ave(Xk3, T_num)
Xk4_ave = get_ave(Xk4, T_num)
data_get['选题与综述平均分'] = Xk1_ave
data_get['创新性及论文价值平均分'] = Xk2_ave
data_get['科研能力与基础知识平均分'] = Xk3_ave
data_get['论文规范性平均分'] = Xk4_ave
data_get['论文总分平均分'] = X_ave
X['ave'] = X_ave
X['Tag'] = data['Tag']
lose = []
for i in range(1,14):
if i == 6 or i == 11:
print('empty')
else:
Tag = X.loc[X['Tag'] == i]
percent_val = np.percentile(Tag['ave'], percent)
lose += list(Tag['ave'] < percent_val)
data_get['是否淘汰'] = lose
data_get.to_excel('Pro_附件2.xlsx', index=None)
问题2的程序
# -*- coding: utf-8 -*-
"""
Created on Sat May 22 16:37:22 2021
@author: MYM
"""
import pandas as pd
import numpy as np
def get_ave(df1, T_num):
data = df1.values
ave_data = data.sum(axis = 1) / T_num
return ave_data
# read xlsx
data = pd.read_excel('附件1.xlsx')
data_get = pd.read_excel('附件2.xlsx')
Num = len(data) # 样本数目
T_num = 3 # the number of teacher
# 获取总分的列
X = data[['Tag','X1','X2','X3']]
X_ave = get_ave(X, T_num)
X['X_ave'] = X_ave
Sub_dict = dict()
for i in range(1,14):
Tag = X.loc[X['Tag'] == i]
Sub_dict.update({'Tag' + str(i):Tag})
Tag_std_dict = dict()
# 每个学科的三个总分的方差均值,与方差方差
Tag_std_mean = pd.DataFrame(index = ['mean','std'], columns = ['Tag1','Tag2','Tag3','Tag4','Tag5','Tag6','Tag7','Tag8','Tag9','Tag10','Tag11','Tag12','Tag13'])
for i in range(1,14):
Tag_val = Sub_dict.get('Tag' + str(i))[['X1','X2','X3']]
Tag_std = Tag_val.values.std(axis = 1)
Tag_std_dict.update({'Tag' + str(i):Tag_std})
Tag_std_mean.loc['mean','Tag'+str(i)] = Tag_std.mean()
Tag_std_mean.loc['std','Tag'+str(i)] = Tag_std.std()
Tag_std_mean.to_csv('Total scores.csv')
# 计算每个学科的各个项目的得分,与总分平均分水平
# 获取非评语列
Tag_all = data.drop(columns = ['R1','R2','R3'])
Tag_all_dict = dict()
for i in range(1,14):
Tag_temp = Tag_all.loc[Tag_all['Tag'] == i]
Tag_all_dict.update({'Tag' + str(i):Tag_temp})
Tag_all_mean_dict = dict()
for i in range(1,14):
Tag_xk1 = Tag_all_dict.get('Tag' + str(i))[['X11','X21','X31']]
Tag_xk2 = Tag_all_dict.get('Tag' + str(i))[['X12','X22','X32']]
Tag_xk3 = Tag_all_dict.get('Tag' + str(i))[['X13','X23','X33']]
Tag_xk4 = Tag_all_dict.get('Tag' + str(i))[['X14','X24','X34']]
Tag_x = Tag_all_dict.get('Tag' + str(i))[['X1','X2','X3']]
df1 = pd.DataFrame(index = ['mean','std'], columns = ['Xk1','Xk2','Xk3','Xk4','X'])
df1['Xk1'] = [Tag_xk1.values.mean(), Tag_xk1.values.std()]
df1['Xk2'] = [Tag_xk2.values.mean(), Tag_xk2.values.std()]
df1['Xk3'] = [Tag_xk3.values.mean(), Tag_xk3.values.std()]
df1['Xk4'] = [Tag_xk4.values.mean(), Tag_xk4.values.std()]
df1['X'] = [Tag_x.values.mean(), Tag_x.values.std()]
Tag_all_mean_dict.update({'Tag'+str(i):df1}) # 每个学科的分项与总项的均值与方差(不区分打分老师)
for i in range(1,14):
if i == 6 or i == 11:
print('skip')
else:
ex = Tag_all_mean_dict.get('Tag' + str(i))
ex.to_csv('Tag' +str(i)+'.csv')
问题3的程序
# -*- coding: utf-8 -*-
"""
Created on Sun May 23 10:47:17 2021
@author: MYM
"""
import numpy as np
import pandas as pd
import jieba
import sklearn
from sklearn.feature_extraction.text import CountVectorizer
def get_custom_stopwords(stop_words_file):
with open(stop_words_file, encoding='utf-8')as f:
stopwords=f.read()
stopwords_list=stopwords.split('\n')
custom_stopwords_list=[i for i in stopwords_list]
return custom_stopwords_list
#加载自定义词语
jieba.load_userdict("C:/Users/MYM/My_python_codes/DSA/user_dict.txt")
#打开文件,文件在桌面上,可以自行修改路径
f1 = open("C:/Users/MYM/My_python_codes/DSA/text_words.txt","r",encoding='GB2312',errors='ignore')
f2 = open("C:/Users/MYM/My_python_codes/DSA/text_words_token.txt",'w',encoding='GB2312',errors='ignore')
for line in f1:
seg_list = jieba.cut(line, cut_all = False)
f2.write((" ".join(seg_list)).replace("\t\t\t","\t"))
#print(w)
f1.close()
f2.close()
# 取需要分词的内容
titles = open("C:/Users/MYM/My_python_codes/DSA/text_words_token.txt", encoding='GB2312', errors='ignore').read().split('\n')
#查看内容,这里是一个list, list里面每个原素是分好的标题,查看下长度看有没有错误
#停用词函数调用
stop_words_file= "C:/Users/MYM/My_python_codes/DSA/CNstopwords.txt"
stopwords = get_custom_stopwords(stop_words_file)
#构建词向量,也就是把分好的次去除停词转化成kmeans可以接受的形式
from sklearn.feature_extraction.text import CountVectorizer
count_vec=CountVectorizer(stop_words = stopwords)
km_matrix= count_vec.fit_transform(titles)
print(km_matrix.shape)
#查看词向量
# print(km_matrix.toarray())
#开始聚类啦
from sklearn.cluster import KMeans
num_clusters = 8 #聚为八类,可根据需要修改
km = KMeans(n_clusters=num_clusters)
km.fit(km_matrix)
clusters = km.labels_.tolist()
#查看聚类的结果,是list,这里省略,看看长度是不是和title一样就行啦
#len(clusters)
#最后把聚类结果写在一个新的txt里面
f3 =open("C:/Users/MYM/My_python_codes/DSA/cluster.txt", 'w',encoding='GB2312',errors='ignore')
for i in clusters:
f3.write(str(i))
f3.write("\n")
f3.close()
# f1 = open("C:/Users/MYM/My_python_codes/DSA/text_words.txt","r",encoding='GB2312',errors='ignore')
# f2 = open("C:/Users/MYM/My_python_codes/DSA/text_words_label.txt",'w',encoding='GB2312',errors='ignore')
# counts = 0
# for line in f1:
# f2.write(str(clusters[counts]))
# f2.write(' ')
# counts = counts + 1
# f2.write(line)
# f1.close()
# f2.close()
问题3的补充程序
# -*- coding: utf-8 -*-
"""
Created on Wed May 26 10:07:12 2021
@author: MYM
"""
import numpy as np
import pandas as pd
data = pd.read_excel('附件1.xlsx')
# 读取聚类结果
clusters = []
f1 = open("C:/Users/MYM/My_python_codes/DSA/cluster.txt", 'r',encoding='GB2312',errors='ignore')
for line in f1:
clusters.append(eval(line))
tag_dict = dict()
tag = (1,2,3,4,5,7,8,9,10,12,13)
for i in tag:
temp = pd.read_csv('Tag'+str(i)+'.csv')
tag_dict.update({'Tag'+str(i):temp})
num = list()
for i in range(8):
clusters_temp = [s == i for s in clusters]
num.append(sum(clusters_temp))
right = 0
for i in range(1246):
Tag = data.loc[i,'Tag']
mean = tag_dict.get('Tag'+ str(Tag))
mean_x1 = mean.loc[0,'Xk1']
mean_x23 = (mean.loc[0,'Xk2'] + mean.loc[0,'Xk3'])/2
mean_x4 = mean.loc[0,'Xk4']
s = data.loc[i,'R1']
if pd.isnull(s) or type(s) == int:
print('nan')
else:
if data.loc[i,'X11'] >= mean_x1:
if (data.loc[i,'X12'] + data.loc[i,'X13'])/2 >= mean_x23 :
if data.loc[i,'X14'] >= mean_x4:
if clusters[i] == 7: # 111
right+=1
else:
if clusters[i] == 6: # 110
right+=1
else:
if data.loc[i,'X14'] >= mean_x4:
if clusters[i] == 5:# 101
right+=1
else:
if clusters[i] == 0: # 100
right+=1
else:
if (data.loc[i,'X12'] + data.loc[i,'X13'])/2 >= mean_x23 :
if data.loc[i,'X14'] >= mean_x4:
if clusters[i] == 4: # 011
right+=1
else:
if clusters[i] == 3: # 010
right+=1
else:
if data.loc[i,'X14'] >= mean_x4:
if clusters[i] == 2:# 001
right+=1
else:
if clusters[i] == 1: # 000
right+=1
问题4的程序
# -*- coding: utf-8 -*-
"""
Created on Wed May 26 12:20:33 2021
@author: MYM
"""
import numpy as np
import pandas as pd
# 每个学科的平均分与标准差
tag_dict = dict()
tag = (1,2,3,4,5,7,8,9,10,12,13)
for i in tag:
temp = pd.read_csv('Tag' + str(i) + '.csv')
tag_dict.update({'Tag'+ str(i) : temp})
# 读取聚类结果
clusters = []
f1 = open("C:/Users/MYM/My_python_codes/DSA/cluster_q4.txt", 'r',encoding='GB2312',errors='ignore')
for line in f1:
clusters.append(eval(line))
# 读取附件1
data = pd.read_excel('附件1.xlsx')
all_score = data[['X1','X2','X3']]
count = 0
for i in range(1246):
Tag = data.loc[i,'Tag']
mean = tag_dict.get('Tag'+ str(Tag))
mean_x = mean.loc[0,'X']
std_x = mean.loc[1,'X']
s = data.loc[i,'R1']
if pd.isnull(s) or type(s) == int:
print('nan')
else:
if clusters[count] == 0:
if all_score.loc[i,'X1'] <= mean_x:
all_score.loc[i,'X1'] = all_score.loc[i,'X1'] + std_x/2
else:
if all_score.loc[i,'X1'] >= mean_x:
all_score.loc[i,'X1'] = all_score.loc[i,'X1'] - std_x/2
for i in range(1246):
Tag = data.loc[i,'Tag']
mean = tag_dict.get('Tag'+ str(Tag))
mean_x = mean.loc[0,'X']
std_x = mean.loc[1,'X']
s = data.loc[i,'R2']
if pd.isnull(s) or type(s) == int:
print('nan')
else:
if clusters[count] == 0:
if all_score.loc[i,'X2'] <= mean_x:
all_score.loc[i,'X2'] = all_score.loc[i,'X2'] + std_x/2
else:
if all_score.loc[i,'X2'] >= mean_x:
all_score.loc[i,'X2'] = all_score.loc[i,'X2'] - std_x/2
for i in range(1246):
Tag = data.loc[i,'Tag']
mean = tag_dict.get('Tag'+ str(Tag))
mean_x = mean.loc[0,'X']
std_x = mean.loc[1,'X']
s = data.loc[i,'R3']
if pd.isnull(s) or type(s) == int:
print('nan')
else:
if clusters[count] == 0:
if all_score.loc[i,'X3'] <= mean_x:
all_score.loc[i,'X3'] = all_score.loc[i,'X3'] + std_x/2
else:
if all_score.loc[i,'X3'] >= mean_x:
all_score.loc[i,'X3'] = all_score.loc[i,'X3'] - std_x/2
f_score = all_score.sum(axis = 1)/3
f_data = pd.read_excel('Pro_附件2.xlsx')
f_data['综合得分'] = f_score
f_data.to_excel('Pro_附件2.xlsx')
问题5的程序
# -*- coding: utf-8 -*-
"""
Created on Wed May 26 14:31:00 2021
@author: MYM
"""
import numpy as np
import pandas as pd
# 读取附件2数据
data_get = pd.read_excel('Pro_附件2.xlsx')
# 提取淘汰论文
lose_paper = data_get.loc[data_get['是否淘汰'] == True]
#提取优秀论文
percent = 90
percent_val = np.percentile(data_get['综合得分'], percent)
win_paper = data_get.loc[data_get['综合得分'] > percent_val]
lose_paper = lose_paper[lose_paper['Tag'] == 8]
win_paper = win_paper[win_paper['Tag'] == 8]
lose_paper_val = lose_paper[['选题与综述平均分','创新性及论文价值平均分','科研能力与基础知识平均分','论文规范性平均分','论文总分平均分','综合得分']]
win_paper_val = win_paper[['选题与综述平均分','创新性及论文价值平均分','科研能力与基础知识平均分','论文规范性平均分','论文总分平均分','综合得分']]
lose_mean = lose_paper_val.sum(axis = 0)/len(lose_paper_val)
lose_std = lose_paper_val.std(axis = 0)
win_mean = win_paper_val.sum(axis = 0)/len(win_paper_val)
win_std = win_paper_val.std(axis = 0)
print(lose_paper_val.sum(axis = 0)/len(lose_paper_val))
print(lose_paper_val.std(axis = 0))
print(win_paper_val.sum(axis = 0)/len(win_paper_val))
print(win_paper_val.std(axis = 0))
代码与论文地址:https://github.com/xiaolingwei/DSA
欢迎关注我的github与csdn。
本文原创,转载请注明出处。

















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









