







 文章介绍了SSD寿命的主要指标TBW(TerabyteWritten)和DWPD(DriveWritesPerDay),以及影响SSD寿命的关键因素,包括NAND的P/ECycles和写放大现象。写放大是由于垃圾回收机制导致的实际写入量大于用户数据写入量的现象。此外,文章提供了查看SSD寿命状态的方法,包括使用smartctl和NVMe工具,并讨论了如何通过测试和监控来评估写放大对SSD寿命的影响。
文章介绍了SSD寿命的主要指标TBW(TerabyteWritten)和DWPD(DriveWritesPerDay),以及影响SSD寿命的关键因素,包括NAND的P/ECycles和写放大现象。写放大是由于垃圾回收机制导致的实际写入量大于用户数据写入量的现象。此外,文章提供了查看SSD寿命状态的方法,包括使用smartctl和NVMe工具,并讨论了如何通过测试和监控来评估写放大对SSD寿命的影响。
一、SSD寿命和写放大简述
SSD寿命规格,业界标准为TBW,TBW指的是Terabyte Writteb写入的兆兆字节,也有定义为Total Bytes Written,SSD使用寿命结束之前指定工作量可以写入SSD的总数据量,用来表达固态硬盘的寿命指标。
因为 SSD 使用 NAND 做为存储介质,SSD 的寿命本质上受限于 NAND 的寿命。NAND 寿命的量化指标叫 P/E Cycles,也就是写入/擦除(program / erase)次数,因为 NAND 是以页(page)为单位写入数据,以块(block)为单位擦除,对于已经写入数据的 block,必须将原有数据进行搬移,SSD 是通过“垃圾回收”(Garbage Collection,GC)的机制来回收被无效数据占用的空闲空间,GC 额外搬移的数据需要用到 SSD 的 OP(Over-provisioning)预留空间。对整个 block 的数据擦除后才能允许新数据写入。一写一擦就会消耗 NAND 一个 P/E。
在 NAND 还是 2D 平面时代,TLC NAND PE 只有 500-1000,但在 NAND 进入 3D 堆叠时代后,用于企业级 SSD 的 3D eTLC 可以达到 5000~10,000 PE。
1.1 SSD寿命单位
SSD 寿命的单位有两种,PBW(或 TBW)和 DWPD。
PBW/TBW:全称是 Petabytes/Terabytes Written,也就是在 SSD 的生命周期内允许的主机端数据写入量。1PBW = 1000TBW
TBW与业务模型强相关,因此,需要固定业务模型,并计算出在此种业务模型下,实际的TBW:
TBW=host_bytes_written差值*32*1024*1024/1024/1000/1000/1000/1000/timed_workload_media_wear
DWPD:全称是 Drive Writes Per Day。也就是在生命周期内(一般为 5 年),SSD 每天允许全盘写入的次数。DWPD 和 PBW/TBW 可以相互换算,公式如下:

DWDP意味着每天可以对SSD整体擦写几次,可以根据业务大小选定合适DWDP的SSD。
1.2 写放大
不同工作负载因为数据分布的不同触发“垃圾回收”(GC)的粒度不同。GC 在进行无效数据的搬移时会引入额外的系统数据写入,带来写放大 WA(Write Amplification),也就是实际用户写一笔数据,真正写入到 SSD 的可能需要 2-3 笔。写放大因子(Write Amplification Factor,简称 WAF)是 NAND 总写量除以用户预期的数据写入量的比率,通过 WAF 可以对 WA 引入的多余写入量进行量化。

二、查看SSD和写放大数据
2.1 查看nvme寿命
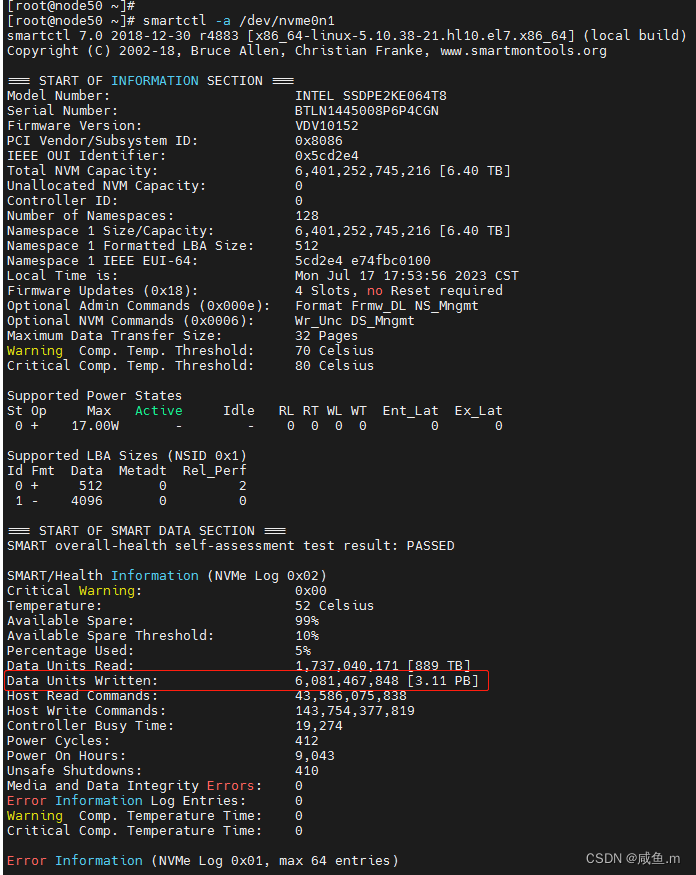
smartctl -a /dev/nvme5n1(或者smartctl -x /dev/nvme5n1)
Data Units Written是指软件写入硬盘的数据量,单位是1000 * 512bytes,换算GB为6,081,467,848*1000*512bytes /1000/1000/1000/1000/1000 = 3.11PB
2.2 查看nvme精确磨损度
计算DWPD需要得到测试期间磁盘磨损度数据以计算TBW,可以通过Solidigm盘测试方法:
1.sst工具查询NVMe盘对应的ID:sst show -ssd;
2.测试之前用sst工具先reset硬盘sst reset -ssd 3 -enduranceanalyzer;
3.测试业务结束后nvme intel smart-log-add /dev/nvme2n1查看smart信息;
timed_workload_media_wear表示从sst命令重置后,写入的数据,增加的磨损度63.999%

2.3 查看由RAID卡管理的SSD
/opt/MegaRAID/storcli/storcli64 /call show
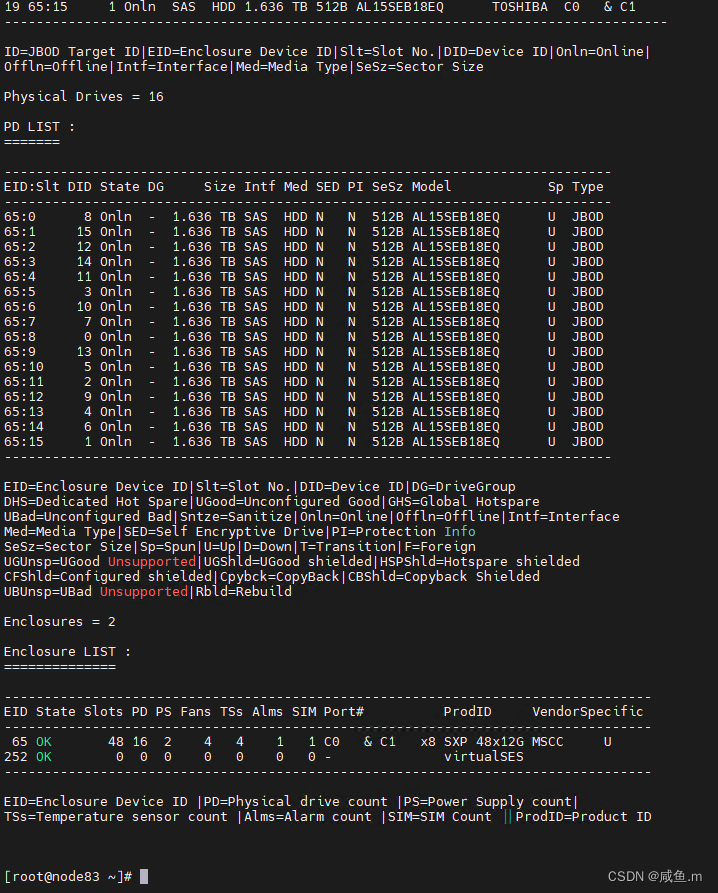
smartctl -a -d megaraid,8 /dev/sda(35是PD LIST里的DID)
DID和盘符的对应关系可以根据lsscsi中地址和/opt/MegaRAID/storcli/storcli64 /call show的JBOD LIST中的ID对应起来
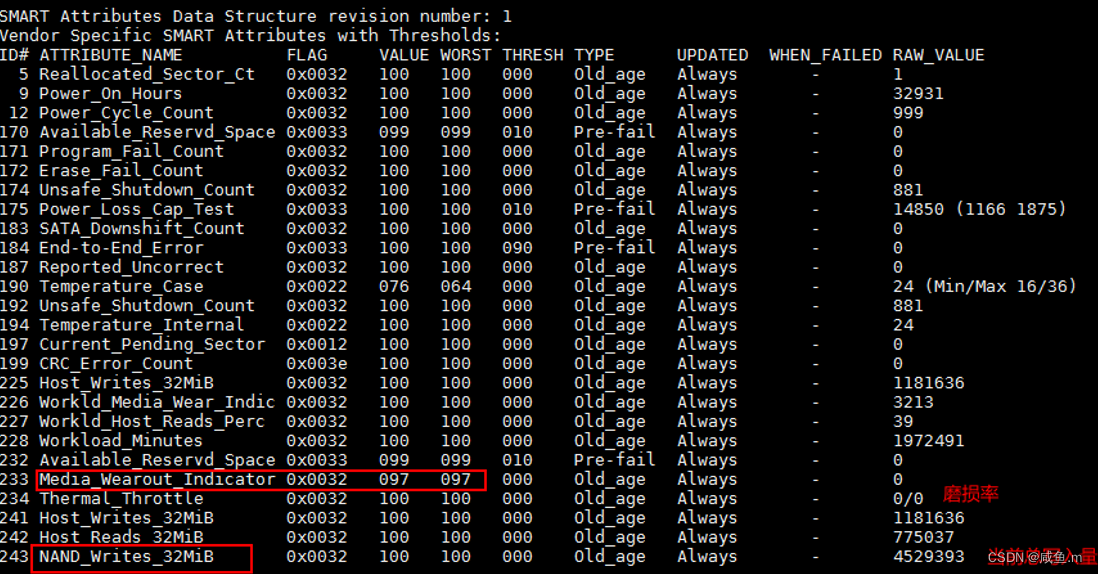
观察参数:
Host_writes_32MB(软件写入硬盘数据量)
media_wearout_indicator(磨损率)
单位换算:host_bytes_written 321024*1024/1000/1000/1000/1000 T
nand_bytes_written =盘所有的写入(包含盘自身的gc搬移等写入)
host_bytes_written = 盘接受到的软件的写入
SSD寿命是否下降过快其实就是SSD写入数据量与用户数据写入量的比值是否过大,也就是写放大是否过大,由于分布式存储或者说软件定义的存储,影响最终写放大(WAF)的因素特别多(冗余策略、GC、压缩等),且目前行业内没有一个固定标准,按照目前测试经验来说全流程写放大超过10,基本上已经可以判定存在较大问题。
2.4 获取客户端写入数据量
可以根据下发io工具的回显计算
例如:vdbench可以通过平均IO带宽*写入时间计算
三、写放大测试
3.1 写放大的测定和业务模型关联
常用的测试模型有4k,8k,1M.
一般采用读写比例3:7,全随机覆盖写,需要事先1M顺序写预埋数据,预埋比例设计触发GC力度,也会影响写放大的大小。
影响写放大测定的因素有:
1、业务模型IO大小
2、业务模型读写比例
3、业务模型顺序随机
4、预埋数据占容量比例
5、测试时长
6、冗余策略
影响因素的原因为:
1、下发写入到硬盘的块大小通常是固定的,比如4MiB,如果写4k占用一个4MiB的块,写放大就与8K,1M不通,不过通常小IO会通过cache聚合一部分,但是还会有一定差异。
2、写放大和写的关系比较大,读存在搬移读可能也有一部分但是没有写影响大
3、通常随机产生的写放大要比顺序大,和1中的原因相似,随机更容易存在小的碎片的写占用很多大的块
4、预埋数据容量和GC力度有关,GC力度越大越可能产生写放大
5、测试时长,稍微复杂一点,和GC标记垃圾,回收,以及写放大的波动有关。
6、三副本或者EC4+2容量有效率不同,写放大也不同。
3.2 写放大计算
W
A
F
总
=
Δ
N
a
n
d
W
r
i
t
e
总
Δ
H
o
s
t
W
r
i
t
e
WAF_{总}=\frac{\Delta NandWrite_{总}}{\Delta HostWrite}
WAF总=ΔHostWriteΔNandWrite总
其中
W
A
F
总
WAF_{总}
WAF总为总写放大,
Δ
N
a
n
d
W
r
i
t
e
总
\Delta NandWrite_{总}
ΔNandWrite总为所有盘写入数据量,
Δ
H
o
s
t
W
r
i
t
e
\Delta HostWrite
ΔHostWrite为软件总写入数据量。
T
B
W
=
Δ
N
a
n
d
W
r
i
t
e
总
Δ
W
e
a
r
TBW=\frac{\Delta NandWrite_{总}}{\Delta Wear}
TBW=ΔWearΔNandWrite总
其中TBW为盘总共可以擦写的数据量,
Δ
W
e
a
r
\Delta Wear
ΔWear为磨损率。
D
W
P
D
=
T
B
W
S
p
a
c
e
∗
Y
e
a
r
∗
365
DWPD=\frac{TBW}{Space*Year*365}
DWPD=Space∗Year∗365TBW
其中DWPD为盘寿命中每天可以擦写的次数,Space为盘容量,Year为寿命数。
W
A
F
盘
=
Δ
N
a
n
d
W
r
i
t
e
盘
Δ
H
o
s
t
W
r
i
t
e
/
N
u
m
盘
/
U
a
s
g
e
WAF_{盘}=\frac{\Delta NandWrite_{盘}}{\Delta HostWrite/Num_{盘}/Uasge}
WAF盘=ΔHostWrite/Num盘/UasgeΔNandWrite盘
其中
Δ
N
a
n
d
W
r
i
t
e
盘
\Delta NandWrite_{盘}
ΔNandWrite盘为盘写入数据量,
N
u
m
盘
Num_{盘}
Num盘为盘数目,
U
a
s
g
e
Uasge
Uasge为存储利用率。
四、闪存垃圾回收
1.1 为什么需要垃圾回收
SSD固态硬盘由于和HDD机械硬盘的写入方式不同,所以SDD存在颗粒擦除操作,称为trim,trim的单位为block通常为4Mib左右,擦除耗时通常在ms级别,但是SDD硬盘read和wirte的单位通常是page通常为4kb左右,读写耗时通常在10us级别。
由于上述机制的存在,在写入新数据之前需要将已删除的数据trim掉,但是又由于trim的单位大于读写的单位,而且耗时较长(频繁漫无目的trim可能影响读写性能且可能trim掉有效数据),所以需要制定一个策略,有规划的trim数据,所以延伸出来了垃圾回收的机制。
在介绍垃圾回收机制之前引入几个概念:
1、log-write 由于顺序写入的性能远高于随机写入,所以引入了日志写入的方法,随机IO被顺序追加到日志中,将随机写入转化为顺序写入。
2、SSD硬盘segment,在实际的全闪存储系统中,为了管理和实现的方便,往往对作为存储介质的
SSD 使用空间进行进一步的分组 。将若干个连续固定数目的 Block 分组成一个段(称为 Segment 或Section 或 Zone 等 )。这样一块 SSD盘就会包含若干个Segment。
1.2 垃圾回收的机制
为了解决垃圾回收问题,并最大化的减少垃圾回收对空间利用率和性能的影响,工程师们提出了很多种方法和机制。
1、数据冷热区分,存放在不同的segment
2、设置segment垃圾回收的阈值(确定何时回收)
3、设置优先回收冷数据
具体如何区分冷热数据,以什么指标区分,以什么为阈值,segment具体怎么划分,垃圾回收阈值为多少,冷数据所在的冷段应该优先到什么程度,这些有许多论文提出的许多机制,具体不在阐述,但是总体思想是围绕这些机制展开的。


















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









