






一、研究背景
(1)文本-视频检索工作需要额外的模块对预训练模型进行微调,这会引入更多参数并增加计算负担;
(2)用于微调的数据量过低还会造成原有模型的知识遗忘,带来过拟合风险;
(3)现有prompt工作具有局限性:
仅让文本分支学习prompt忽略了文本-视觉编码器协同微调的作用;
仅对输入层进行prompt对输出嵌入只有间接影响;
二、研究目标
引入prompt tuning,提高模型泛化性;
prompt tuning:冻结主干网络参数,只在输入前微调少量额外参数。
三、技术路线
(1)提出VoP作为baseline,仅用训练少量参数就可将CLIP用于文本-视频检索;
(2)同时为视频和文本编码器引入 prompts,即Co-operative Prompt;
证实对所有编码器的每一层准备prompt可以更好地实现微调;
(3)探索视频prompt,使VoP综合更多帧的时空信息;
视频理解需要同时汇总时空信息;
基于视频特性,建立三种视频促进机制,对帧位置(聚合同一帧内的信息)、帧内容(聚合上下文信息到帧内)、层功能进行建模(自适应地协助学习帧内或帧间的亲和关系)
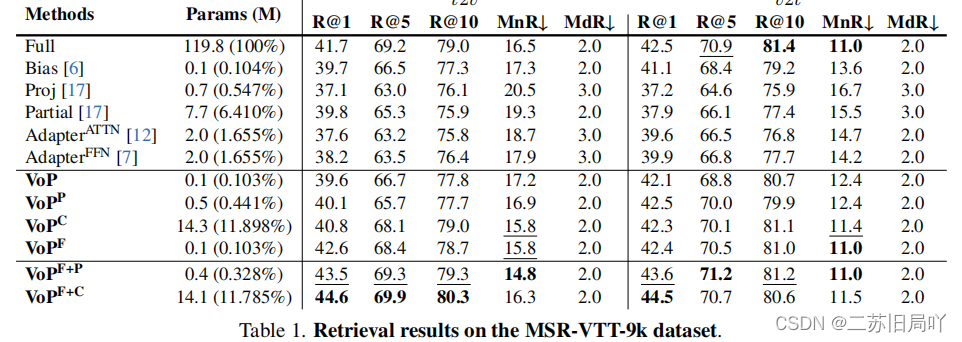
四、实验结果















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











