






在AI的发展历程中,一直存在着两种理念的较量:一种是追求普适性的通用AI模型,另一种是针对特定领域深度优化的专业AI系统。最近,微软的研究团队在这一辩论中投下了一枚重磅炸弹——他们开发的Medprompt策略,使得通用AI模型GPT-4在医学领域的问答任务上超越了所有现有的专业模型。
Medprompt:通用模型的“专业”提示
Medprompt是一种先进的提示策略,旨在提高通用人工智能(AI)模型在专业领域,尤其是医学领域的表现。这项技术通过一系列创新的方法,使得像GPT-4这样的通用AI模型能够解决复杂的医学问题,而无需依赖于特定领域的大量训练或专家知识。Medprompt策略介绍:
1. 动态少样本选择(Dynamic Few-shot Selection)
这一技术通过选择与当前问题语义上最相似的训练样本来构建提示。它利用k-最近邻(k-NN)聚类方法,在嵌入空间中找到与测试问题最接近的训练样本。这样做的目的是为模型提供最相关的示例,帮助它更好地理解和回答问题。
2. 自生成思维链(Self-Generated Chain of Thought)
Medprompt允许GPT-4自己生成一系列推理步骤,这些步骤详细说明了如何从问题到答案的逻辑过程。这种自我生成的思维链(CoT)有助于模型进行深入的逻辑推理,从而提高答案的准确性。
3. 选择洗牌集成(Choice Shuffling Ensemble)
为了减少模型可能的偏好偏差,Medprompt采用选择洗牌技术。它通过随机打乱选项的顺序,生成多个推理路径,然后选择最一致的答案,即对选项顺序变化最不敏感的答案。
Medprompt的工作流程
Medprompt的工作流程包括两个主要阶段:预处理和推理。
预处理阶段
- 对训练集中的每个问题使用轻量级嵌入模型生成嵌入向量。
- 使用GPT-4为每个问题生成思维链和最终答案的预测。
- 如果生成的答案正确,存储相关问题、嵌入向量、思维链和答案。
推理阶段
- 对测试问题重新使用嵌入模型生成嵌入向量。
- 使用kNN算法从预处理过的训练数据池中检索最相似的示例。
- 将这些示例及其对应的GPT-4生成的推理链作为上下文提供给GPT-4。
- 将测试问题和相应的答案选择添加到上下文中,形成最终的提示。
- 模型遵循少量示例,输出思维链和候选答案。
- 通过多次重复上述步骤并打乱测试问题的答案选择来执行集成过程,增加多样性。
Medprompt通过结合上述方法,不仅在医学问答数据集上取得了前所未有的准确率,还在多个非医学领域的数据集上展现了其通用性和有效性。这项研究证明了即使是通用AI模型,只要通过精心设计的提示策略,也能够在专业领域内实现专家级别的性能。
超越专家系统:MedQA上的90%准确率
在MedQA数据集(模拟美国医学执照考试)上,Medprompt策略使GPT-4的准确率首次超过了90%,这是该领域的一个重要里程碑。这一成就不仅展示了通用AI模型的潜力,也对医学教育和临床决策支持系统的未来提出了新的可能。
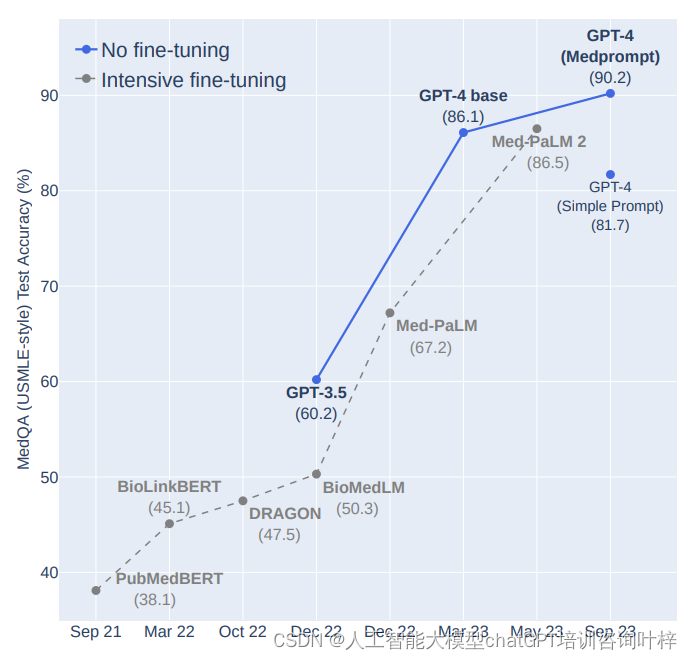
如图所示,Medprompt在MedQA数据集上的性能,并与包括Med-PaLM 2在内的其他模型进行了比较。Medprompt的准确率达到了90.2%,而专门调优的模型Med-PaLM 2的准确率为86.5%。这一结果突出了Medprompt策略在没有专家知识的情况下,通过提示工程提升通用模型性能的能力。

不同基础模型在MultiMedQA套件的多项选择部分的性能对比,GPT-4使用Medprompt在MedQA US (4-option)数据集上达到了上述的准确率,这一结果是通过选择最佳的5次少样本示例(5 shot)并结合Medprompt策略实现的。
研究者们还测试了Medprompt在医学以外领域的应用,包括电气工程、机器学习、哲学、会计、法律、护理和临床心理学等。在这些领域的测试表明,Medprompt的通用性提示策略可以推广到其他专业领域,这为AI的应用开辟了新的道路。但这些测试并不能完全代表现实世界中的医学任务。未来,AI在医疗领域的应用需要更多的研究来确保其在开放世界中的有效性和可靠性。同时,需要关注AI输出的偏见问题,并在追求整体准确性的同时,确保不同子群体间的公平性。
论文链接:https://arxiv.org/pdf/2311.16452.pdf
















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











