






一、研究背景
1、目前缺乏对二分类分类器在跨数据集检测时性能不佳的全面分析。
2、基于二元分类器的方法泛化性差,因此,一些工作通过提取手工特征(如,伪影)来提升泛化性,但在伪造图片不包含此类特征时, 判断结果并不准确。
二、研究动机
伪造过程会导致ID信息的丢失。
当目标图像与伪造图像进行面部互换,目标图像的身份仍会发生改变。
因此,伪造结果的身份不能被认为与其目标图像或源图像相同。
伪造检测任务与身份无关,因此分类器不该依据身份做判断,会带来过拟合问题。
三、研究目标
验证分类器的泛化障碍是因为其错误地学习了图像上的身份表示。
1、在训练阶段,分类器倾向将某些身份组视为真实身份,而将其他身份组视为假身份。显然,将身份纳入参考会提升训练集上的性能。
2、跨数据集进行测试时,上述与身份相关的有偏表示会被分类器错误利用,导致错误判断。
四、技术路线
提出ID-unaware Deep-fake Detection Model,以减少隐式身份泄漏的影响。
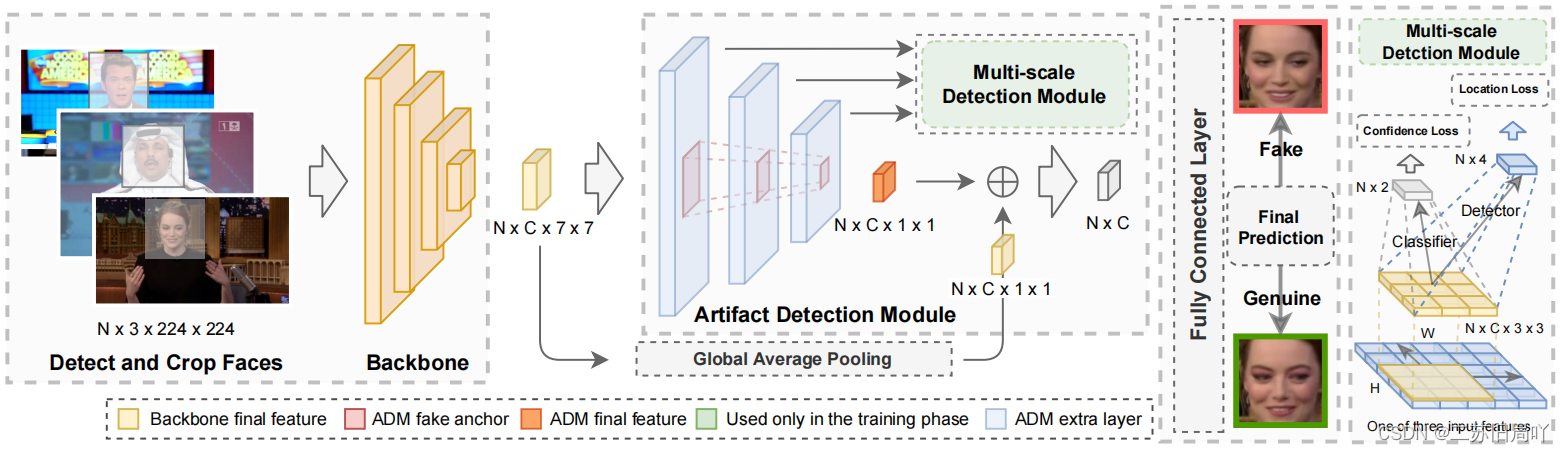
(1)为使模型只关注图像的局部区域,较少地关注全局身份信息,提出Artifact Detection Module,以指导模型关注局部伪影区域。
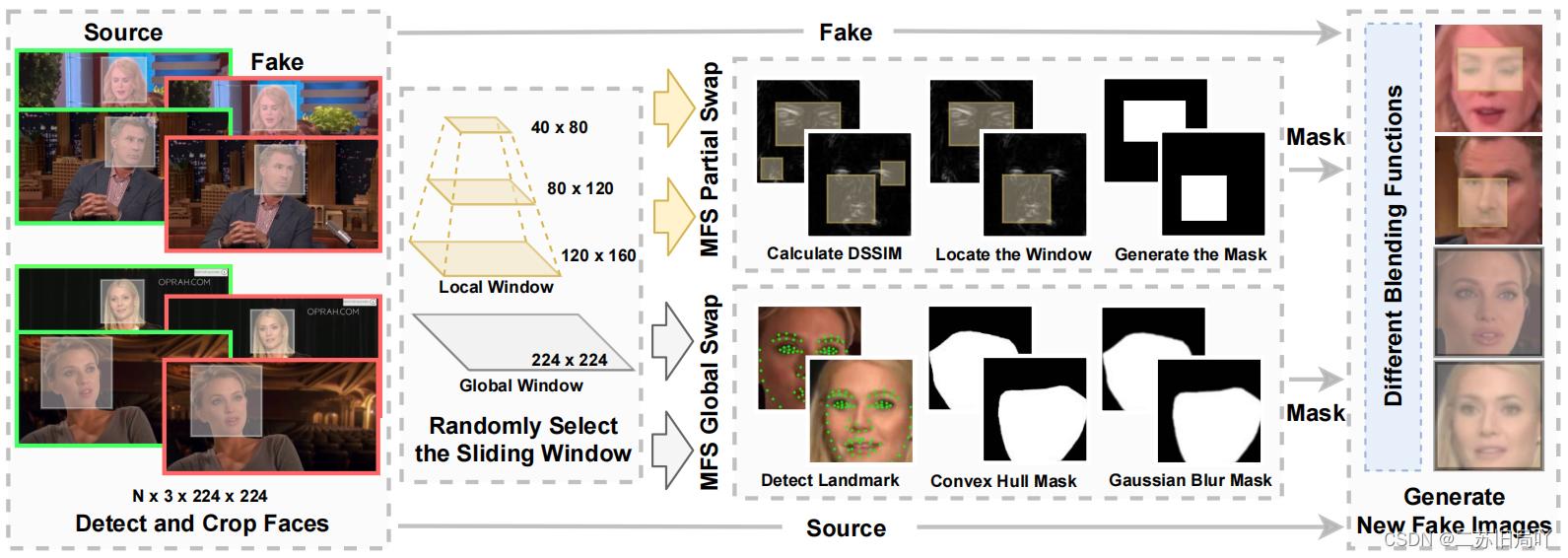
(2)为解决数据集无伪造部位标注的问题,提出Multi-scale Facial Swap方法,在伪影最可能出现的位置重新进行生成。
- 确定伪影位置
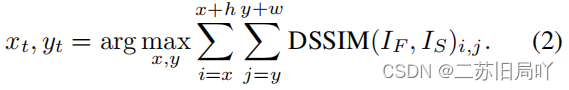
- 新伪影生成
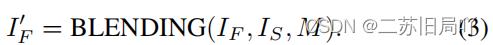
3、损失函数
![]()
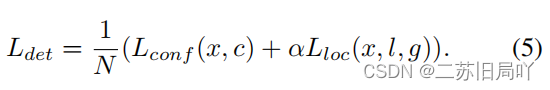
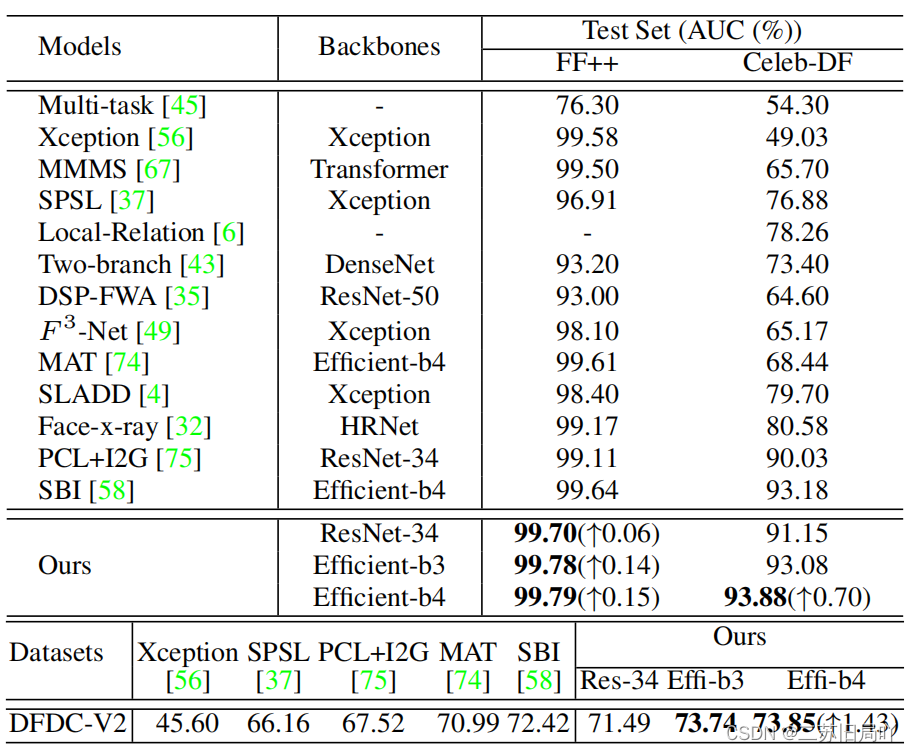
五、实验结果

















 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











