






一、研究背景
现有deepfake检测模型主要针对完整视频做二分类,使其难以在工业场景中应用。
现有deepfake检测模型大多只对单模态数据和人脸相关数据做检测。
temporal forgery localization (TFL)
temporal action localization (TAL)
二、研究动机
需要开发能够准确定位操纵边界的技术,促进AIGC任务的可靠应用。
基于Transformer的模型可以适应不同模态的特征输入。
三、研究目标
定位被操纵片段的开始和结束时间戳,帮助用户更好地理解检测结果。
提出针对图像修复场景的操纵定位数据集。
四、技术路线
UMMAFormer:在时间维度上对多种模态的输入进行定位。
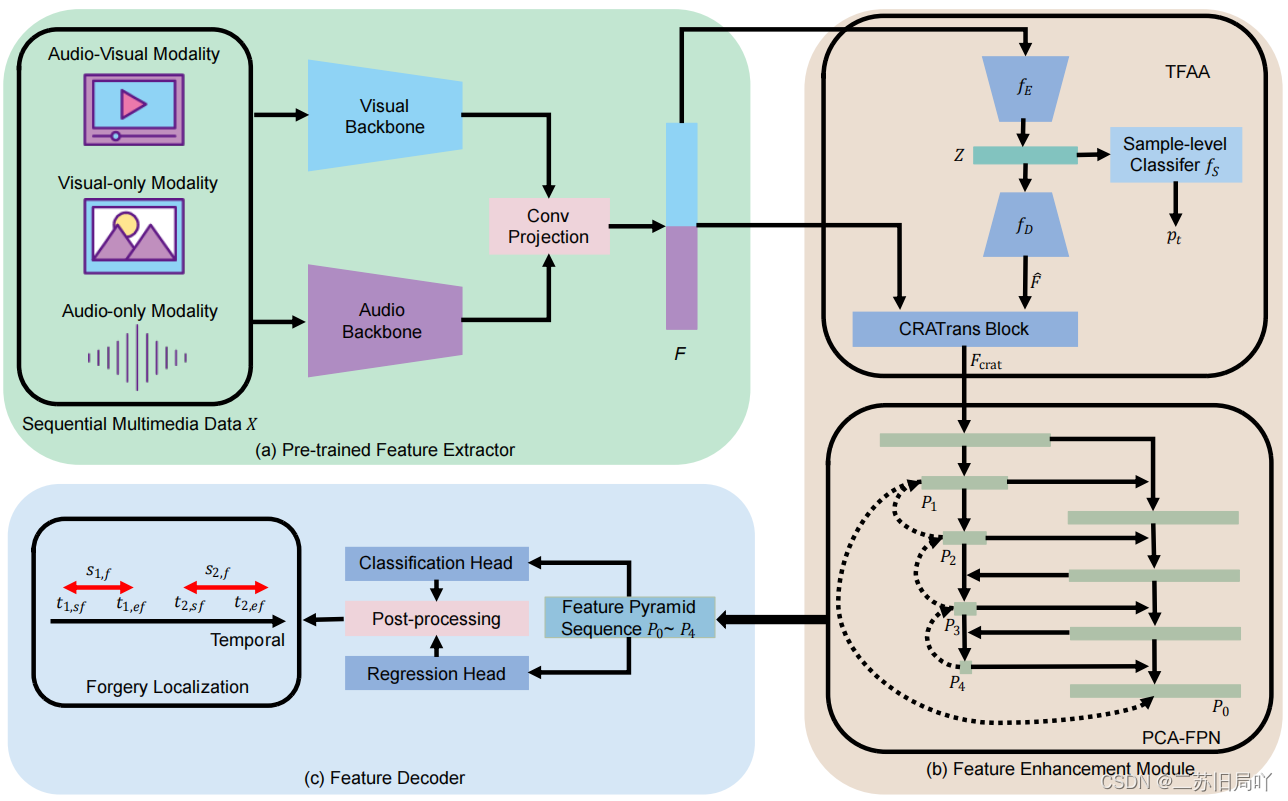
1.Temporal Feature Abnormal Attention(TFAA):关注时间维度的异常
训练阶段:学习真实数据的分布
推理阶段:利用注意力机制关注重建出的异常片段
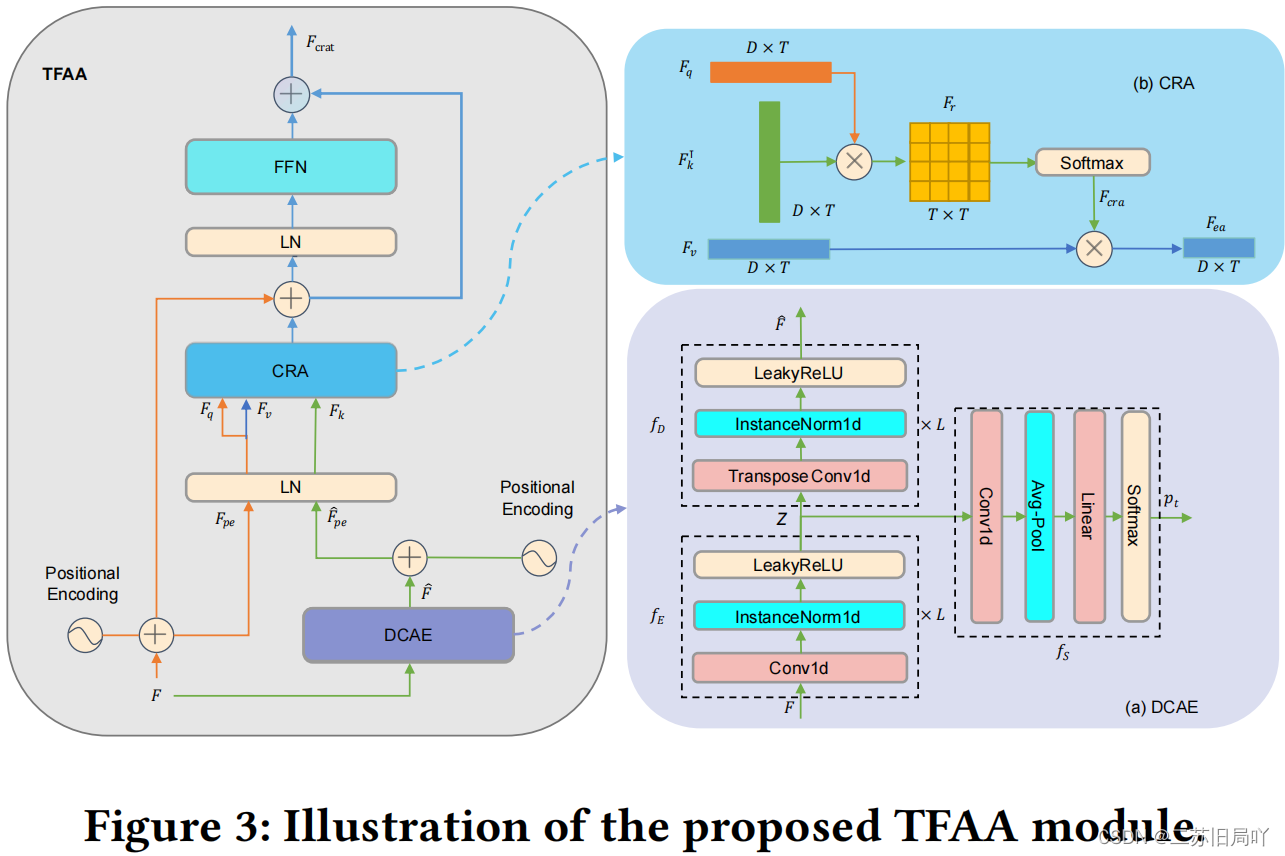
(1)Reconstruction Learning
- Deep Convolutional AutoEncoder (DCAE):只重建真实数据
- 对输入数据进行编码( f E f_E fE)解码( f D f_D fD)操作:特征降维得到 Z Z Z、特征重建得到 F ^ \hat{F} F^
- 利用
L
r
e
c
L_{rec}
Lrec约束原始数据和重建数据

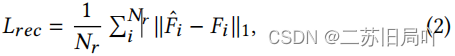
- 利用focal loss约束真实样本间的一致性:
p
t
p_t
pt为属于伪造样本的概率
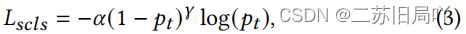
(2)Cross-Reconstruction Attention Transformer(CRA)
- 不同类型携带的信息量不同,可能导致真样本有较大重构误差
伪造片段会与真实样本极其相似,导致较小的重构误差 - 因此利用交叉重构注意力计算原始输入特征与重构特征的相似度分数,替代重构误差
- 加入位置编码,得到位置敏感特征 F p e F_{pe} Fpe、 F ^ p e \hat{F}_{pe} F^pe
- 计算相似度矩阵
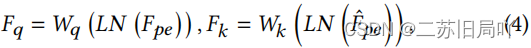

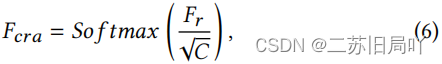
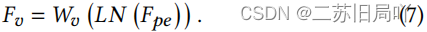

- F e a F_{ea} Fea经过LN、FFN得到 F c r a t F_{crat} Fcrat
2.Parallel Cross-Attention Feature Pyramid Network(PCA-FPN):增强网络对短片段的识别、定位能力
- 特征融合
- 解决特征融合中的噪声问题
3.Temporal Video Inpainting Localization dataset(TVIL)
五、实验结果

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











