







嘤嘤嘤,SPG还没搞懂但是实验效果不错,KCNet,Pointwise都是从类似于卷积核提取特征的切入点入手的。
CVPR2018 SPG
Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs
(论文链接)(pytorch源码链接)
不同于此前的工作,SPG不是去逐点进行分类,而是将多个点组成的点集看作一个完整的整体,对每个点集再进行分类,并且可以描述相邻物体之间的关系,非常适用于上下文分类。SPG的大小是由场景中简单结构的数量来确定的,而不是点的总数。
(啊。好复杂啊。里边好多东西都不太懂,之前没了解过,提到的一些论文也需要看一下。以后慢慢填吧这个坑。但是从最后实验的结果来看,效果确实不错。)
Problem & Solution

Geometrically homogeneous partition 将点云划分为简单的几何图形,suprerpoint
Superpoint embedding 降采样
Contextual segmentation 基于图卷积的深度学习算法
Geometric Partition with a Global Energy

进行划分的目标不是把整个物体划分出来,而是划分成多个简单的几何形体。
对于含有
n
n
n个点的三维点云
C
\mathcal{C}
C,每个点包括位置信息
p
i
p_i
pi、观测信息
o
i
o_i
oi(如颜色、强度等)
对于每个点,计算一组
d
g
d_g
dg几何特征
f
i
∈
R
d
g
f_i\in \mathbb{R}^{d_g}
fi∈Rdg来刻画其局部邻域的形状。使用的特征包括[1]提出的线性度、平面度和散射度,垂直度特征,此外还计算了每个点的绝对高度作为点
p
i
p_i
pi的
z
z
z坐标。
[1]提出的全局能量是根据点云的10个最近邻邻接图
G
n
n
=
(
C
,
E
n
n
)
G_{nn}=(C,E_{nn})
Gnn=(C,Enn)来定义的。几何形体划分可以被定义为下列连通分量的优化问题:
arg
min
g
∈
R
d
g
∑
i
∈
C
∣
∣
g
i
−
f
i
∣
∣
2
+
μ
∑
(
i
,
j
)
∈
E
n
n
w
i
,
j
[
g
i
−
g
j
≠
0
]
\arg \min _{g\in \mathbb{R}^{d_g}} \sum _{i\in \mathcal{C}} ||g_i-f_i||^2+\mu \sum _{(i,j)\in E_{nn}}w_{i,j}[g_i-g_j\ne0]
argg∈Rdgmini∈C∑∣∣gi−fi∣∣2+μ(i,j)∈Enn∑wi,j[gi−gj=0]
其中
[
⋅
]
[·]
[⋅]为艾佛森括号,边的权值
w
∈
R
+
∣
E
∣
w\in R^{| E |}_+
w∈R+∣E∣与边缘长度成线性递减关系,
μ
\mu
μ是正则化强度。
使用[2]所提出的
l
0
−
c
u
t
l_0-cut
l0−cut算法快速迭代求得近似解。从上式解得的连通分量
S
=
S
1
,
⋅
⋅
⋅
,
S
k
S={S_1,···,S_k}
S=S1,⋅⋅⋅,Sk称为superpoints。
Superpoint Graph Construction
SPG是点云的结构化表示,是一个有向图
G
=
(
S
,
E
,
F
)
\mathcal{G=(S,E},F)
G=(S,E,F),节点
S
\mathcal{S}
S是superpoints集,边
E
\mathcal{E}
E是superpoint之间的边superedges,superedges有由特征
d
f
d_f
df表示的邻接关系
F
∈
R
E
×
d
f
F\in\mathbb{R}^{\mathcal{E}\times d_f}
F∈RE×df。
定义一个[3]提出的对称Voronoi邻接图
G
v
o
r
=
(
C
,
E
v
o
r
)
G_vor=(C,E_{vor})
Gvor=(C,Evor)。如果superpoints
S
S
S和
T
T
T之间至少有一条边在
E
v
o
r
E_{vor}
Evor中,那么
S
S
S和
T
T
T就是邻接的:
E
=
{
(
S
,
T
)
∈
S
2
∣
∃
(
i
,
j
)
∈
E
v
o
r
∩
(
S
×
T
)
}
\mathcal{E}=\{(S,T)\in \mathcal{S}^2 | \exists(i,j) \in E_{vor}\cap (S\times T)\}
E={(S,T)∈S2∣∃(i,j)∈Evor∩(S×T)}
与superpoints
(
S
,
T
)
(S,T)
(S,T)相关的重要空间特征是从
E
v
o
r
E_{vor}
Evor中的边的偏移
δ
(
S
,
T
)
\delta(S,T)
δ(S,T)获得的:
δ
(
S
,
T
)
=
{
(
p
i
,
p
j
)
∣
(
i
,
j
)
∈
E
v
o
r
∩
(
S
×
T
)
}
\delta (S,T)=\{(p_i,p_j)|(i,j)\in E_{vor}\cap (S\times T)\}
δ(S,T)={(pi,pj)∣(i,j)∈Evor∩(S×T)}
superedgs的特征也可以通过比较相邻superpoints的形状和大小来得到。其他的一些superedgs特征↓:

Superpoint Embedding
这一步的目的是将每一个superpoint S i S_i Siembedding得到一个 d z d_z dz维的向量 z i z_i zi。论文中选用了pointnet来实现。
Contextual Segmentation
受到GatedGNN和ECC的启发,首先用上一步中得到的
z
i
z_i
zi来初始化GRU的隐藏单元,然后迭代更新
t
=
1
,
.
.
.
T
t=1,...T
t=1,...T。对于每一次迭代,一个GRU的隐藏状态用
h
i
(
t
)
h_i^{(t)}
hi(t)表示,传来的输入信息为
m
i
(
t
)
m_i^{(t)}
mi(t),计算得到的新的状态为
h
i
(
t
+
1
)
h_i^{(t+1)}
hi(t+1)。输入
m
i
(
t
)
m_i^{(t)}
mi(t)是相邻superpoints
j
j
j的隐藏状态
h
j
(
t
)
h_j^{(t)}
hj(t)的加权和,权重由 superedge
(
j
,
i
)
(j,i)
(j,i)的特征
F
j
,
i
F_{j,i}
Fj,i决定。上述计算是通过多层感知机实现,计算过程如下:
h
i
(
t
+
1
)
=
(
1
−
u
i
(
t
)
)
⊙
q
i
(
t
)
+
u
i
(
t
)
⊙
h
i
(
t
)
q
i
(
t
)
=
tanh
(
x
1
,
i
(
t
)
+
r
i
(
t
)
⊙
h
1
,
i
(
t
)
)
u
i
(
t
)
=
σ
(
x
2
,
i
(
t
)
+
h
2
,
i
(
t
)
)
,
r
i
(
t
)
=
σ
(
x
3
,
i
(
t
)
+
h
3
,
i
(
t
)
)
(
h
1
,
i
(
t
)
,
h
2
,
i
(
t
)
,
h
3
,
i
(
t
)
)
T
=
ρ
(
W
h
h
i
(
t
)
+
b
h
)
(
x
1
,
i
(
t
)
,
x
2
,
i
(
t
)
,
x
3
,
i
(
t
)
)
T
=
ρ
(
W
x
x
i
(
t
)
+
b
x
)
x
1
,
i
(
t
)
=
σ
(
W
g
h
i
(
t
)
+
b
g
)
⊙
m
i
(
t
)
m
i
(
t
)
=
m
e
a
n
j
∣
(
j
,
i
)
∈
E
(
F
j
i
,
.
;
W
e
)
⊙
h
j
(
t
)
h
i
(
1
)
=
z
i
,
y
i
=
W
o
(
h
i
(
1
)
,
…
,
h
i
(
T
+
1
)
)
T
\begin{aligned} \mathbf{h}_{i}^{(t+1)} =\left(1-\mathbf{u}_{i}^{(t)}\right) \odot \mathbf{q}_{i}^{(t)}+\mathbf{u}_{i}^{(t)} \odot \mathbf{h}_{i}^{(t)} \\ \mathbf{q}_{i}^{(t)} =\tanh \left(\mathbf{x}_{1, i}^{(t)}+\mathbf{r}_{i}^{(t)} \odot \mathbf{h}_{1, i}^{(t)}\right) \\ \mathbf{u}_{i}^{(t)}=\sigma\left(\mathbf{x}_{2, i}^{(t)}+\mathbf{h}_{2, i}^{(t)}\right), \mathbf{r}_{i}^{(t)}=\sigma\left(\mathbf{x}_{3, i}^{(t)}+\mathbf{h}_{3, i}^{(t)}\right) \\ \left(\mathbf{h}_{1,i}^{(t)}, \mathbf{h}_{2, i}^{(t)}, \mathbf{h}_{3, i}^{(t)}\right)^{T} =\rho\left(W_{h} \mathbf{h}_{i}^{(t)}+b_{h}\right) \\ \left(\mathbf{x}_{1,i}^{(t)}, \mathbf{x}_{2, i}^{(t)}, \mathbf{x}_{3, i}^{(t)}\right)^{T} =\rho\left(W_{x} \mathbf{x}_{i}^{(t)}+b_{x}\right) \\ \mathbf{x}_{1, i}^{(t)}=\sigma\left(W_{g} \mathbf{h}_{i}^{(t)}+b_{g}\right) \odot m_i^{(t)}\\ m_i^{(t)}=mean_{j|(j,i)\in \mathcal{E}}\left(F_{j i,.} ; W_{e}\right) \odot \mathbf{h}_{j}^{(t)} \\ \mathbf{h}_{i}^{(1)}=\mathbf{z}_{i}, \mathbf{y}_{i}=W_{o}\left(\mathbf{h}_{i}^{(1)}, \ldots, \mathbf{h}_{i}^{(T+1)}\right)^{T} \end{aligned}
hi(t+1)=(1−ui(t))⊙qi(t)+ui(t)⊙hi(t)qi(t)=tanh(x1,i(t)+ri(t)⊙h1,i(t))ui(t)=σ(x2,i(t)+h2,i(t)),ri(t)=σ(x3,i(t)+h3,i(t))(h1,i(t),h2,i(t),h3,i(t))T=ρ(Whhi(t)+bh)(x1,i(t),x2,i(t),x3,i(t))T=ρ(Wxxi(t)+bx)x1,i(t)=σ(Wghi(t)+bg)⊙mi(t)mi(t)=meanj∣(j,i)∈E(Fji,.;We)⊙hj(t)hi(1)=zi,yi=Wo(hi(1),…,hi(T+1))T
Input Gating
Edge-Conditioned Convolution
State Concatenation
Relation to CRFs


[1] S. Guinard and L. Landrieu. Weakly supervised segmentation-aided classification of urban scenes from 3d LiDAR point clouds. In ISPRS 2017, 2017. 2, 3, 8
[2] L. Landrieu and G. Obozinski. Cut pursuit: Fast algorithms to learn piecewise constant functions on general weighted graphs. SIAM Journal on Imaging Sciences, 10(4):1724– 1766, 2017. 3
[3] J. W. Jaromczyk and G. T. Toussaint. Relative neighborhood graphs and their relatives. Proceedings of the IEEE, 80(9):1502–1517, 1992. 4
CVPR2018 KCNet
Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling
(论文链接)(caffe源码链接)(pytorch源码链接)
PointNet++通过牺牲速度构建更加复杂的模型来更好的提取局部特征,KCNet尝试在保持网络简单结构的条件下,探寻其他有效的、可学习的、具有清晰几何解释的局部特征提取方法来改进PointNet。提出的改进主要有两个:一个是用于提取局部几何结构的kernel correlation layer,另一个是用于提高网络鲁棒性的graph-based pooling layer
最大的创新点大概在设计了kernel correlation,使得能够更好的提取点云的局部结构特征,暂时还没有看过三维卷积核直接应用到点云的网络,不知道能不能得到类似的局部特征,但是考虑到点云的数量特征,直接用三维卷积核大概是不行吧hhhh。。。。
Architecture

Learning on Local Geometric Structure
kernel points 类似于卷积核,通过反向传播来不断地调整找到一组点的参考/模板。
使用类似于Leave-one-out Kernel Correlation (LOO-KC)和 multiply-linked registration损失函数来提取局部几何结构特征。
一个可以学习
M
M
M个点的point-set kernel
κ
\boldsymbol{\kappa}
κ和含有
N
N
N个点的点云的 anchor point
x
i
\mathbf{x}_{i}
xi 之间核相关关系 kernel correlation(KC)如下:
K
C
(
κ
,
x
i
)
=
1
∣
N
(
i
)
∣
∑
m
=
1
M
∑
n
∈
N
(
i
)
K
σ
(
κ
m
,
x
n
−
x
i
)
\mathrm{KC}\left(\boldsymbol{\kappa}, \mathbf{x}_{i}\right)=\frac{1}{|\mathcal{N}(i)|} \sum_{m=1}^{M} \sum_{n \in \mathcal{N}(i)} \mathrm{K}_{\sigma}\left(\boldsymbol{\kappa}_{m}, \mathbf{x}_{n}-\mathbf{x}_{i}\right)
KC(κ,xi)=∣N(i)∣1m=1∑Mn∈N(i)∑Kσ(κm,xn−xi)
其中
κ
m
\boldsymbol{\kappa}_m
κm是核中的第
m
m
m个可学习点,
N
(
i
)
\mathcal{N}(i)
N(i)是anchor point
x
i
\mathbf{x}_{i}
xi 的邻点的集合,
x
n
\mathbf{x}_{n}
xn是
x
i
\mathbf{x}_{i}
xi的邻点之一。
K
σ
(
⋅
,
⋅
)
\mathrm{K}_{\sigma}(·,·)
Kσ(⋅,⋅):
ℜ
D
×
ℜ
D
→
ℜ
\Re^{D} \times \Re^{D} \rightarrow \Re
ℜD×ℜD→ℜ是任何有效的核函数(
D
D
D是核函数维度)。为了有效地存储点的局部邻域,我们将每个点看作一个顶点来预先计算KNNG,边只连接附近的顶点。论文中选用的是高斯核函数:
K
σ
(
k
,
δ
)
=
exp
(
−
∥
k
−
δ
∥
2
2
σ
2
)
\mathrm{K}_{\sigma}(\mathbf{k}, \boldsymbol{\delta})=\exp \left(-\frac{\|\mathbf{k}-\boldsymbol{\delta}\|^{2}}{2 \sigma^{2}}\right)
Kσ(k,δ)=exp(−2σ2∥k−δ∥2)
其中,
∣
∣
⋅
∣
∣
||·||
∣∣⋅∣∣是欧氏距离,
σ
\sigma
σ是核的宽度。
σ
\sigma
σ的大小对最后的结果的影响如下表:

在进行反向传播时:
∂
L
∂
κ
m
=
∑
i
=
1
N
α
i
d
i
[
∑
n
∈
N
(
i
)
v
m
,
i
,
n
exp
(
−
∥
v
m
,
i
,
n
∥
2
2
σ
2
)
]
\frac{\partial \mathcal{L}}{\partial \kappa_{m}}=\sum_{i=1}^{N} \alpha_{i} d_{i}\left[\sum_{n \in \mathcal{N}(i)} \mathbf{v}_{m, i, n} \exp \left(-\frac{\left\|\mathbf{v}_{m, i, n}\right\|^{2}}{2 \sigma^{2}}\right)\right]
∂κm∂L=i=1∑Nαidi⎣⎡n∈N(i)∑vm,i,nexp(−2σ2∥vm,i,n∥2)⎦⎤
其中,
L
\mathcal{L}
L是损失函数,每个点
x
i
\mathbf{x}_{i}
xi的KC反馈
d
i
=
∂
L
∂
K
C
(
κ
,
x
i
)
d_i=\frac{\partial \mathcal{L}}{\partial KC(\kappa,\mathbf{x}_i)}
di=∂KC(κ,xi)∂L,正则常数
α
i
=
−
1
∣
N
(
i
)
∣
σ
2
\alpha_i=\frac{-1}{|\mathcal{N}(i)|\sigma^2}
αi=∣N(i)∣σ2−1,局部差分向量
v
m
,
i
,
n
=
κ
m
+
x
i
−
x
n
\mathbf{v}_{m, i, n}=\kappa_{m}+\mathbf{x}_{i}-\mathbf{x}_{n}
vm,i,n=κm+xi−xn
KC与LOO-KC的不同在于:KC计算的是相邻点和核内可学习到的点的相似性,且KC允许核中的点自由移动。
通过学习得到的


Learning on Local Feature Structure
把每个点看作顶点,只与相邻的点用边连接构造了一个KNNG。 作者认为,相邻的点趋向于拥有相似的几何结构。通过neighborhood graph的学习可以更好的提取局部特征。
graph pooling layer的输入为
X
∈
ℜ
N
×
K
\mathbf{X} \in \Re^{N \times K}
X∈ℜN×K,KNNG的邻接矩阵
W
∈
R
e
N
×
N
W\in\ Re^{N \times N}
W∈ ReN×N,如果
i
i
i,
j
j
j之间有边,则
W
(
i
,
j
)
=
1
W(i,j)=1
W(i,j)=1,否则为0。通过graph pooling操作聚合其邻域内每个点的特征:
P
=
D
−
1
W
\mathbf{P}=\mathbf{D}^{-1} \mathbf{W}
P=D−1W
其中,
D
∈
ℜ
N
×
N
D\in \Re^{N \times N}
D∈ℜN×N是degree matrix:
d
i
,
j
=
{
deg
(
i
)
,
if
i
=
j
0
,
otherwise
d_{i, j}=\left\{\begin{array}{ll} {\operatorname{deg}(i),} & {\text { if } i=j} \\ {0,} & {\text { otherwise }} \end{array}\right.
di,j={deg(i),0, if i=j otherwise
得到上述局部特征后使用graph max pooling或者average pooling,然后使用与pointnet类似的网络结构来实现分类和语义分割,具体的网络结构如Figure2.
experiment on ShapeNet part segmentation

CVPR2018 PointwiseCNN
Pointwise Convolutional Neural Networks
(论文链接)(tensorflow源码链接)
与KCNet一样,PointwiseCNN也将关注点放在了卷积算子上,提出了一种新的卷积算子,PointwiseCNN的整个网络非常的简单,点云数据集也不需要特别复杂的预处理,最后也可以在S3DIS、SceneNN、ObjectNN等数据集上得到与PointNet相差不大的准确度。
Pointwise Architecture

网络的结构非常的简单,使用了四层大小一致的带有Pointwise卷积操作的Pointwise Convolution Layer,将各层的输出concat到一起,然后使用一层Pointwise Convolution Layer进行语义分割,或者使用两层全连接层进行分类。
Pointwise Convolution
Convolution Pointwise Convolution卷积核的设计非常的简单,以输入点云中的某一点为中心,卷积核中的点都会对中心点有一定的贡献(卷积核的形状可以是任意的,但有大小和半径属性),如下图:

pointwise convolution 可以用下式表示:
x
i
ℓ
=
∑
k
w
k
1
∣
Ω
i
(
k
)
∣
∑
p
j
∈
Ω
i
(
k
)
x
j
ℓ
−
1
x_{i}^{\ell}=\sum_{k} w_{k} \frac{1}{\left|\Omega_{i}(k)\right|} \sum_{p_{j} \in \Omega_{i}(k)} x_{j}^{\ell-1}
xiℓ=k∑wk∣Ωi(k)∣1pj∈Ωi(k)∑xjℓ−1
其中,
k
k
k迭代所有pointwise核的子区域,
Ω
i
(
k
)
\Omega_{i}(k)
Ωi(k)是以
i
i
i为中心的核的第
k
k
k个子区域,
p
i
p_i
pi是点
i
i
i的坐标,
∣
⋅
∣
|·|
∣⋅∣是对子区域中所有的点进行计数,
w
k
w_k
wk是核中第
k
k
k个子区域的权重,
x
i
x_i
xi和
x
j
x_j
xj是点
i
i
i和
j
j
j的值,
l
−
1
l-1
l−1和
l
l
l是输入和输出层的标号。
Gradient back propagation 要进行训练就需要计算梯度来核的优化,定义损失函数为
L
L
L,对输入的梯度可以定义为:
∂
L
∂
x
j
ℓ
−
1
=
∑
i
∈
Ω
j
∂
L
∂
x
i
ℓ
∂
x
i
ℓ
∂
x
j
ℓ
−
1
\frac{\partial L}{\partial x_{j}^{\ell-1}}=\sum_{i \in \Omega_{j}} \frac{\partial L}{\partial x_{i}^{\ell}} \frac{\partial x_{i}^{\ell}}{\partial x_{j}^{\ell-1}}
∂xjℓ−1∂L=i∈Ωj∑∂xiℓ∂L∂xjℓ−1∂xiℓ
其中,
∂
L
∂
x
j
ℓ
\frac{\partial L}{\partial x_{j}^{\ell}}
∂xjℓ∂L是在
l
l
l层的梯度,在反向传播的过程中可以计算得到,
∂
x
i
ℓ
∂
x
j
ℓ
−
1
\frac{\partial x_{i}^{\ell}}{\partial x_{j}^{\ell-1}}
∂xjℓ−1∂xiℓ如下:
∂
x
i
ℓ
∂
x
j
ℓ
−
1
=
∑
k
w
k
1
∣
Ω
i
(
k
)
∣
∑
p
j
∈
Ω
i
(
k
)
1
\frac{\partial x_{i}^{\ell}}{\partial x_{j}^{\ell-1}}=\sum_{k} w_{k} \frac{1}{\left|\Omega_{i}(k)\right|} \sum_{p_{j} \in \Omega_{i}(k)} 1
∂xjℓ−1∂xiℓ=k∑wk∣Ωi(k)∣1pj∈Ωi(k)∑1
类似的可以定义对核中权重的梯度:
∂
L
∂
w
k
=
∑
i
∂
L
∂
x
i
ℓ
∂
x
i
ℓ
∂
w
k
\frac{\partial L}{\partial w_{k}}=\sum_{i} \frac{\partial L}{\partial x_{i}^{\ell}} \frac{\partial x_{i}^{\ell}}{\partial w_{k}}
∂wk∂L=i∑∂xiℓ∂L∂wk∂xiℓ
其中,
∂
x
i
ℓ
∂
w
k
=
1
∣
Ω
i
(
k
)
∣
∑
p
j
∈
Ω
i
(
k
)
x
j
ℓ
−
1
\frac{\partial x_{i}^{\ell}}{\partial w_{k}}=\frac{1}{\left|\Omega_{i}(k)\right|} \sum_{p_{j} \in \Omega_{i}(k)} x_{j}^{\ell-1}
∂wk∂xiℓ=∣Ωi(k)∣1∑pj∈Ωi(k)xjℓ−1
论文中使用的核为
3
×
3
×
3
3\times 3\times 3
3×3×3的卷积核,卷积核中所有单元的权重都是一样的。
文的网络中没有使用池化层。
Point order 作者认为输入点云是需要进行排序的,因此在输入之前,按照特定的顺序(如XYZ、Mortoncurve)对点云进行了排序。但作者认为在进行语义分割时点序是没有影响的。
A-trous convolution 很容易实现atrous convolution
Point attributes 可以添加一些颜色什么的数据进去
Relevance to geometric deep learning
一些实验结果:


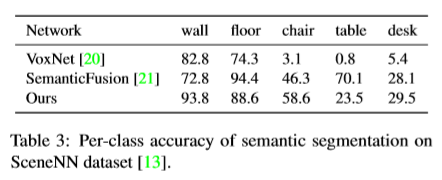
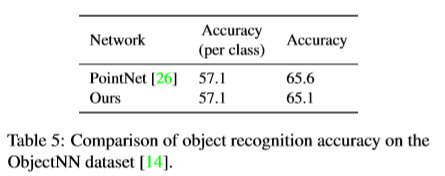
















 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









