







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
本次分享的课题是
🎯利用机器学习算法构建电商平台的个性化商品推荐系统
背景和意义
随着电子商务的迅速发展,海量商品和用户信息的产生使得个性化推荐系统成为提升用户体验和销售转化率的重要工具。传统的推荐方法多依赖于简单的协同过滤或基于内容的推荐,难以适应用户需求的动态变化和商品多样性。机器学习算法的引入为个性化商品推荐提供了新的解决方案,通过对用户行为数据和商品特征的深入分析,可以构建更为精准的推荐模型,实时捕捉用户偏好,从而提供个性化的购物体验。
利用机器学习算法构建电商平台的个性化商品推荐系统,具有重要的理论与实践意义。首先,深入研究机器学习在推荐系统中的应用,可以丰富电子商务领域的理论基础,推动智能推荐技术的发展。其次,通过构建高效的个性化推荐模型,能够显著提升用户的购物体验和满意度,进而提高平台的用户粘性和销售额。此外,该研究将为电商平台提供科学的数据驱动决策支持,帮助商家精准定位用户需求。
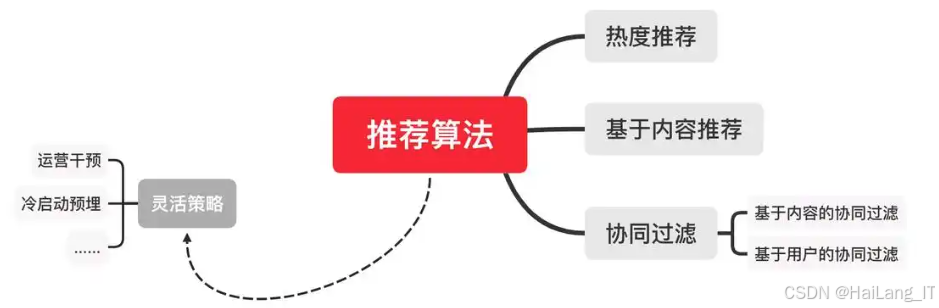
技术思路
基于内容的推荐算法主要依据物品的特征信息来推荐相似物品。它会先分析物品的各种属性,如在音乐推荐中,歌曲的风格、歌手、时长、歌词等都属于特征。通过计算这些特征之间的相似度,例如使用余弦相似度等方法,当用户对某一物品表现出偏好时,就向其推荐具有相似特征的其他物品。比如用户喜欢一首摇滚风格的歌曲,系统就会推荐其他摇滚风格的歌曲。这种算法的优点是能很好地推荐符合用户特定兴趣的物品,推荐结果易于解释;缺点是难以发现用户新的兴趣点,且对于特征提取和相似度计算的要求较高,如果特征选取不当,可能导致推荐效果不佳。
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 假设电影数据存储在一个 DataFrame 中,包含'title'(电影名)、'genres'(类型)、'director'(导演)、'actors'(主演)等列
movies = pd.read_csv('movies.csv')
# 将电影的特征合并为一个文本列,用于后续的特征提取
movies['features'] = movies['genres'] +'' + movies['director'] +'' + movies['actors']
# 使用 TF-IDF 向量器将文本特征转换为向量
vectorizer = TfidfVectorizer()
features_matrix = vectorizer.fit_transform(movies['features'])
# 计算电影之间的余弦相似度
similarity_matrix = cosine_similarity(features_matrix)
# 假设用户喜欢的电影索引为 user_liked_movie_index
user_liked_movie_index = 0
# 获取该电影与其他电影的相似度得分
similarity_scores = list(enumerate(similarity_matrix[user_liked_movie_index]))
# 按照相似度得分从高到低排序
similarity_scores = sorted(similarity_scores, key=lambda x: x[1], reverse=True)
# 推荐除了用户喜欢的电影之外的前 5 部相似电影
recommended_movies = []
for i in range(1, 6):
recommended_movies.append(movies.iloc[similarity_scores[i][0]]['title'])
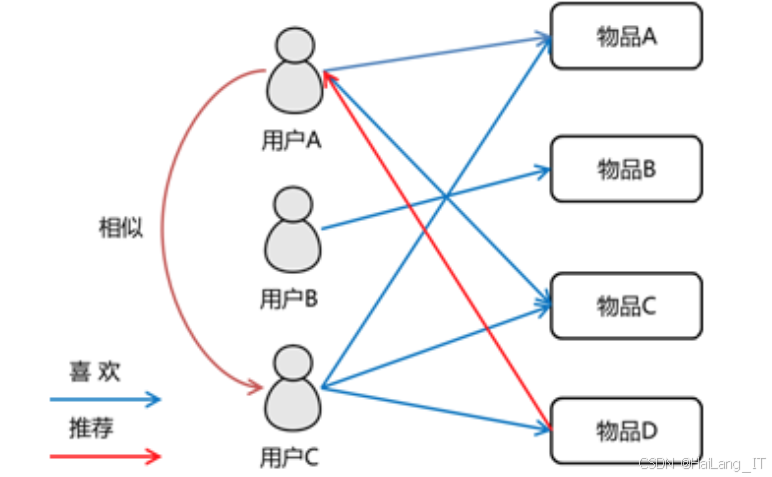
print(recommended_movies)基于用户的协同过滤算法基于这样的假设:如果用户 A 和用户 B 有相似的历史行为(例如都喜欢某些电影或歌曲),那么用户 A 喜欢但用户 B 尚未体验的物品可能也会被用户 B 喜欢。其实现过程首先是计算用户之间的相似度,常用的相似度计算方法有皮尔逊相关系数等。然后根据用户相似度和用户的历史行为,为目标用户推荐其他相似用户喜欢过而目标用户未接触过的物品。这种算法的优势在于能够发现用户潜在的兴趣,推荐一些新颖的物品;但缺点是计算复杂度较高,尤其是在用户数量庞大时,计算用户相似度会消耗大量的计算资源。而且当数据较为稀疏时,很难找到足够相似的用户,导致推荐效果大打折扣。
import numpy as np
# 假设用户评分数据为 user_ratings,行是用户,列是图书,未评分处为 0
user_ratings = np.array([[5, 3, 0, 1],
[4, 0, 0, 1],
[1, 1, 0, 5],
[1, 0, 0, 4],
[0, 1, 5, 4]])
# 计算用户之间的皮尔逊相关系数相似度
def pearson_similarity(user1, user2):
common_books = np.where((user1!= 0) & (user2!= 0))[0]
if len(common_books) == 0:
return 0
user1_ratings = user1[common_books]
user2_ratings = user2[common_books]
mean_user1 = np.mean(user1_ratings)
mean_user2 = np.mean(user2_ratings)
numerator = np.sum((user1_ratings - mean_user1) * (user2_ratings - mean_user2))
denominator = np.sqrt(np.sum((user1_ratings - mean_user1) ** 2) * np.sum((user2_ratings - mean_user2) ** 2))
if denominator == 0:
return 0
return numerator / denominator
# 计算所有用户之间的相似度矩阵
num_users = user_ratings.shape[0]
similarity_matrix = np.zeros((num_users, num_users))
for i in range(num_users):
for j in range(num_users):
similarity_matrix[i][j] = pearson_similarity(user_ratings[i], user_ratings[j])
# 假设目标用户索引为 target_user_index,为其推荐图书
target_user_index = 0
# 找到与目标用户最相似的用户(排除自身)
similar_users = np.argsort(similarity_matrix[target_user_index])[::-1][1:]
recommended_books = []
for similar_user in similar_users:
# 找到相似用户喜欢而目标用户未评分的图书
for book_index in range(user_ratings.shape[1]):
if user_ratings[similar_user][book_index] > 0 and user_ratings[target_user_index][book_index] == 0:
recommended_books.append(book_index)
# 简单打印推荐图书的索引(实际应用中可根据索引获取图书详细信息)
print(recommended_books)基于物品的协同过滤算法则是从物品的角度出发。它先分析用户对不同物品的行为数据,计算物品之间的相似度。例如,如果很多用户都同时喜欢物品 A 和物品 B,那么就认为物品 A 和物品 B 是相似的。然后根据用户的历史偏好信息,将与用户喜欢过的物品相似的其他物品推荐给用户。这种算法的优点是物品相似度相对稳定,一旦计算出来可以在一定时间内离线使用,而且推荐结果的准确性通常较高;缺点是推荐的物品可能缺乏多样性,容易局限于用户已经熟悉的物品类型,并且对于新物品或冷启动物品,由于缺乏足够的用户行为数据,难以准确计算其与其他物品的相似度,从而影响推荐效果。
import numpy as np
# 假设用户购买商品数据为 purchase_data,行是用户,列是商品,购买为 1,未购买为 0
purchase_data = np.array([[1, 0, 1, 0, 1],
[0, 1, 1, 0, 0],
[1, 1, 0, 1, 0],
[0, 1, 0, 1, 1],
[1, 0, 0, 1, 0]])
# 计算物品之间的相似度(这里使用一种简单的共同购买比例作为相似度度量)
def item_similarity(item1, item2):
common_users = np.where((item1!= 0) & (item2!= 0))[0]
if len(common_users) == 0:
return 0
similarity = len(common_users) / (np.sum(item1!= 0) + np.sum(item2!= 0) - len(common_users))
return similarity
# 计算所有物品之间的相似度矩阵
num_items = purchase_data.shape[1]
similarity_matrix = np.zeros((num_items, num_items))
for i in range(num_items):
for j in range(num_items):
similarity_matrix[i][j] = item_similarity(purchase_data[:, i], purchase_data[:, j])
# 假设目标用户索引为 target_user_index,为其推荐商品
target_user_index = 0
# 获取目标用户购买过的商品
purchased_items = np.where(purchase_data[target_user_index] == 1)[0]
recommended_items = []
for purchased_item in purchased_items:
# 找到与购买商品相似的商品(排除已购买的)
similar_items = np.argsort(similarity_matrix[purchased_item])[::-1][1:]
for similar_item in similar_items:
if similar_item not in purchased_items:
recommended_items.append(similar_item)
# 简单打印推荐商品的索引(实际应用中可根据索引获取商品详细信息)
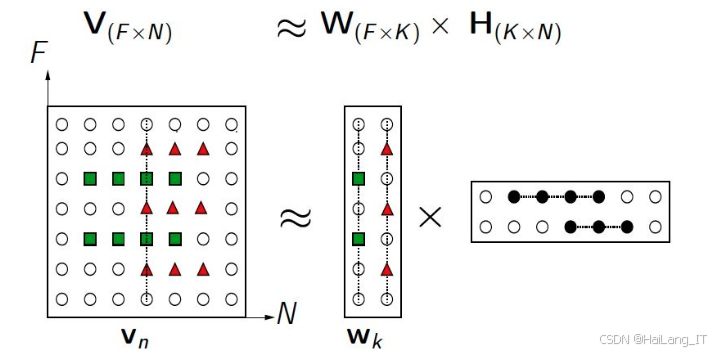
print(recommended_items)矩阵分解是将用户 - 物品评分矩阵分解为两个低维矩阵(用户特征矩阵和物品特征矩阵)的过程。通过分解,将高维稀疏的评分矩阵转化为低维稠密的特征矩阵,从而降低计算复杂度并挖掘用户和物品的潜在特征。例如,在电影推荐中,每个用户和每部电影都可以用一些潜在特征表示,如用户的喜好风格倾向、电影的类型特征等。基于这些潜在特征,可以预测用户对未评分电影的评分,进而进行推荐。这种算法的优点是能够有效处理大规模稀疏数据,并且可以将用户和物品映射到同一个潜在特征空间,方便计算两者之间的相似度;缺点是模型训练时间可能较长,且对于一些复杂的用户行为模式可能捕捉不够准确,容易出现过拟合现象。
import numpy as np
# 假设用户评分矩阵为 R,行是用户,列是物品
R = np.array([[5, 3, 0, 1],
[4, 0, 0, 1],
[1, 1, 0, 5],
[1, 0, 0, 4],
[0, 1, 5, 4]])
# 初始化用户特征矩阵 U 和物品特征矩阵 V
num_users, num_items = R.shape
k = 2 # 设定潜在特征维度
U = np.random.rand(num_users, k)
V = np.random.rand(num_items, k)
# 定义学习率和正则化参数
learning_rate = 0.001
lambda_reg = 0.01
# 训练模型
for _ in range(1000):
for i in range(num_users):
for j in range(num_items):
if R[i][j] > 0:
# 计算预测评分
prediction = np.dot(U[i], V[j])
# 计算误差
error = R[i][j] - prediction
# 更新用户特征矩阵和物品特征矩阵
U[i] += learning_rate * (error * V[j] - lambda_reg * U[i])
V[j] += learning_rate * (error * U[i] - lambda_reg * V[j])
# 预测用户对未评分物品的评分并推荐
target_user_index = 0
predicted_ratings = np.dot(U[target_user_index], V.T)
recommended_items = np.argsort(predicted_ratings)[::-1]
print(recommended_items)LightGBM 是一种基于决策树算法的分布式梯度提升框架。在推荐系统中,它可以处理各种类型的特征,包括离散和连续特征,无需对特征进行归一化处理,还能自动处理缺失值。其采用了 Histogram 决策树算法,将连续的浮点特征值离散化,降低了内存消耗和计算成本;使用更高效的 Leaf - wise 策略,在相同分裂次数下能降低更多误差,获得更高精度,同时可通过最大深度限制防止过拟合。它的优势还包括训练效率快、内存使用低、准确率高、支持并行化学习,能够处理大规模数据,适用于排序、分类等多种机器学习任务,在推荐系统中可以利用其强大的学习能力挖掘用户行为数据与推荐物品之间的复杂关系,从而提供精准的推荐。
import lightgbm as lgb
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_csv('music_data.csv')
# 划分特征和标签
X = data.drop('rating', axis=1)
y = data['rating']
# 创建数据集对象
lgb_data = lgb.Dataset(X, label=y)
# 设置参数
params = {
'boosting_type': 'gbdt',
'objective':'regression',
'metric': 'rmse',
}
# 训练模型
model = lgb.train(params, lgb_data)
# 预测
new_data = pd.read_csv('new_music_data.csv')
predictions = model.predict(new_data)最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!

















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









