







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于自监督学习的钓鱼URL检测算法系统
课题背景和意义
随着互联网规模的不断扩大,钓鱼URL的数量呈指数级增长。传统的人工或规则基础的检测方法无法满足实时性和自动化的需求。钓鱼攻击是网络安全中常见的一种攻击方式,攻击者通过伪造URL,模仿合法网站的外观,诱导用户输入敏感信息或下载恶意软件,导致用户信息泄露、账号被盗等问题。URL检测方法可以实现快速、自动化的检测,能够快速识别和过滤大量的钓鱼URL,提高网络安全的响应速度和效率。
实现技术思路
一、算法理论基础
1.1 自监督模型
自监督学习在钓鱼URL检测中的应用具有以下优势:无需人工标注数据、高效利用数据、学习丰富特征表示、提升鲁棒性和实时检测。这种方法能够有效检测钓鱼URL,适应不断变化的网络环境和新型的钓鱼攻击方式,提高网络安全防范的能力。通过自我标注数据和生成任务,模型可以学习到钓鱼URL的特征,并利用判别任务进行分类,从而提高检测准确度。同时,对抗性训练和实时更新使得模型具备对抗恶意攻击的能力。
自编码器(AE)是一种自监督的神经网络模型,由编码器和解码器两部分组成。编码器将输入数据的关键特征提取出来,将高维输入编码成低维的隐变量,表示输入的潜在空间表征。解码器将隐变量重新构建为原始输入数据,通过最小化输入和输出之间的差距来实现数据重构。通过自编码器的训练,模型可以学习到数据的紧凑表示,即提取出输入数据的关键特征并去除不相关的信息。这种紧凑表示可以用于降维、特征提取和数据压缩等任务。自编码器的训练目标是最小化重构误差,使得解码器能够生成与输入数据相似的输出数据。

自编码器在异常检测中的应用主要通过训练模型来重建输入数据,并通过重构误差判断待测数据是否为异常值。与其他应用不同,异常检测中的自编码器只需要在特定类别的数据上进行训练,而不需要标记异常样本。通过最小化目标输出数据与输入数据的差异,自编码器可以学习到正常数据的特征表示,从而能够有效地检测出异常值。

1.2 钓鱼URL检测
Seq2seq模型是一种序列到序列的神经网络模型,用于处理序列型数据的生成和转换任务。它由编码器和解码器组成,其中编码器将输入序列编码为固定长度的向量表示,解码器则根据编码器的输出生成目标序列。通过使用长短时记忆网络(LSTM)或者其他循环神经网络(RNN)作为编码器和解码器的基本单元,Seq2seq模型能够捕捉序列之间的上下文信息并实现序列的自动建模和生成。
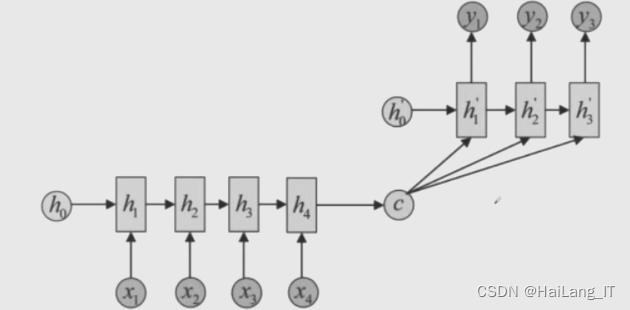
基于Seq2seq模型的钓鱼URL异常检测方法。通过对正常URL进行建模和重建,利用重建差异值进行异常度量,可以有效地识别出钓鱼URL。该方法具有较高的准确性和可靠性,可以帮助提升网络安全防范能力,并对抵御钓鱼攻击起到积极的作用。通过数据预处理、训练和测试模块的有机组合,该方法能够快速、准确地检测出异常值钓鱼URL,为用户和系统提供更好的保护。
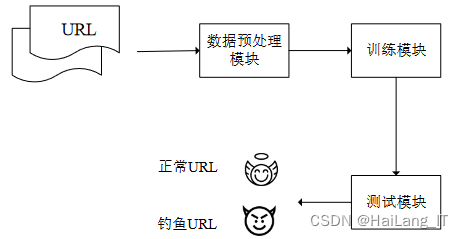
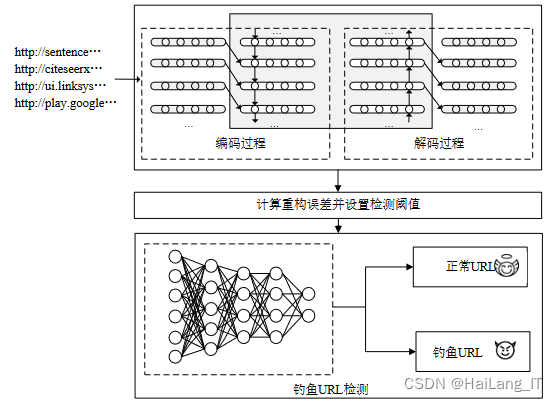
改进后的钓鱼URL检测方法,通过数据预处理、编码过程、解码过程、设置异常值阈值和钓鱼URL检测等步骤实现。首先,对正常URL进行处理,将其转化为特征向量表示。然后,利用Seq2seq模型进行编码和解码,提取正常URL的序列特征并重建原始序列。通过计算重构误差并设置阈值,建立异常度量标准。最后,将待测URL与阈值进行比较,判断其是否属于钓鱼URL。PDSS方法具有高准确性和可靠性,能够快速、精确地检测出钓鱼URL,提升网络安全防护能力,为用户和系统提供可靠保护。
二、 数据集
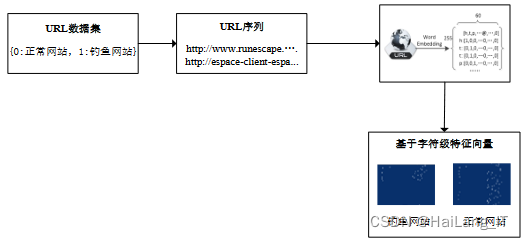
由于网络上没有现有的合适的数据集,我们决定利用网络爬虫技术自行收集数据。通过爬取多个钓鱼网站和合法网站的URL样本,我们构建了一个全新的数据集,其中包含了各种类型的URL样本,涵盖了常见的钓鱼攻击场景。我们还针对各种钓鱼技术进行了分类和标注,使得数据集具有丰富的多样性和准确的标注信息。
在初始有标签数据集中,对URL序列进行编码处理是为了将其转换为数值特征向量,以便于后续的模型训练和处理。这个过程分为建立URL字典映射关系和独热编码两个步骤。首先,建立URL字典映射关系是将URL中的字符与唯一的数值进行对应,用于后续的编码操作。然后,通过独热编码,将每个URL中的字符转换为只有一个位置为1、其余位置为0的二进制向量,从而将URL序列表示为一系列独热编码的特征向量。这样做的好处是可以将文本数据转化为计算机可处理的数值形式,方便进行机器学习算法的应用。
三、实验及结果分析
3.1 实验环境搭建
3.2 模型训练
训练模块包括编码-解码阶段和钓鱼URL检测阈值设置阶段。在编码-解码阶段,PDSS方法使用基于LSTM网络的Seq2seq模型进行URL特征向量的学习。编码器将输入的URL特征向量编码成上下文向量𝑐,代表了正常URL序列的语义信息。解码器以上下文向量𝑐作为初始状态,根据解码过程中的隐藏状态和上一个节点的输出,生成预测序列。编码-解码阶段通过学习正常URL序列的特征,生成预测序列,提高编码-解码的准确性。钓鱼URL检测阈值设置阶段根据预测序列与原始序列的重构误差,确定合适的阈值用于判定钓鱼URL。其过程如下:
- 将正常URL序列𝑋转换为独热编码表示,得到URL的向量表示𝐺。
- 经过编码器,将每个URL的独热编码向量转换为隐藏向量,得到隐藏向量序列𝐻。
- 提取最后一个隐藏状态作为URL序列的上下文向量𝑐。
- 初始化解码器的隐藏状态为上下文向量𝑐。
- 初始化解码器的输出为零向量。
- 通过解码器,依次生成每个节点的隐藏向量和预测输出。
- 利用softmax函数将预测输出映射到[0,1]的范围。
在钓鱼URL检测阈值设置阶段,计算预测序列与正常URL序列的重构误差,通过平均值和标准差来确定钓鱼URL的阈值范围。通过合理设置阈值,可以判定哪些URL属于钓鱼URL,提高网络安全性。 其过程如下:
- 计算编码-解码阶段中预测输出序列𝑌与原始数据的重建误差,得到重建误差序列𝐷。
- 计算重建误差序列𝐷的均值𝜇和标准差𝜎。
- 设置异常检测阈值𝛼1和𝛼2,其中𝛼是一个常数。
- 将𝜇与𝛼𝜎相加得到异常检测阈值1𝛼1,将𝜇与𝛼𝜎相减得到异常检测阈值2𝛼2。
相关代码示例:
# 编码-解码阶段
# 使用Seq2seq模型进行编码-解码
encoder_inputs = Input(shape=(input_length,))
encoder = LSTM(encoding_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c]
decoder_inputs = Input(shape=(output_length,))
decoder_lstm = LSTM(encoding_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = Dense(output_length, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# 钓鱼URL检测阈值设置阶段
# 计算重构误差并确定阈值范围
def calculate_reconstruction_error(normal_urls, predicted_urls):
errors = np.abs(normal_urls - predicted_urls)
mean_error = np.mean(errors)
std_error = np.std(errors)
return mean_error, std_error
def detect_phishing_urls(normal_urls, predicted_urls, alpha):
mean_error, std_error = calculate_reconstruction_error(normal_urls, predicted_urls)
lower_threshold = mean_error - alpha * std_error
upper_threshold = mean_error + alpha * std_error
return lower_threshold, upper_threshold
# 使用训练集进行编码-解码训练
model.fit([train_encoder_input, train_decoder_input], train_decoder_output, epochs=num_epochs, batch_size=batch_size)
# 使用测试集进行预测
predicted_output = model.predict([test_encoder_input, test_decoder_input])
# 根据预测序列和正常URL序列计算重构误差
mean_error, std_error = calculate_reconstruction_error(test_decoder_output, predicted_output)
# 根据重构误差和阈值范围判定钓鱼URL
lower_threshold, upper_threshold = detect_phishing_urls(test_decoder_output, predicted_output, alpha)
phishing_urls = [url for url, error in zip(test_urls, errors) if np.abs(error - mean_error) > alpha * std_error]海浪学长项目示例:





最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 2090
2090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









