







 本文详细介绍了ROC曲线和AUC值的概念及应用,包括混淆矩阵的解读、ROC曲线的绘制方法及其背后的概率解释。
本文详细介绍了ROC曲线和AUC值的概念及应用,包括混淆矩阵的解读、ROC曲线的绘制方法及其背后的概率解释。
ROC & AUC: Theory and Implementation in R
数据
我们先从数据和分类器的角度来解释ROC曲线。假设我们有一组数据
(
x
i
,
y
i
)
i
=
1
P
+
N
(x_i,y_i)_{i=1}^{P+N}
(xi,yi)i=1P+N,
y
i
y_i
yi 是二元的 true label,取值 positive 或者 negative。我们还有一个已经训练好的分类器
ϕ
:
support
(
x
)
→
[
0
,
1
]
\phi:\operatorname{support}(x)\rightarrow [0,1]
ϕ:support(x)→[0,1]。给定一个阈值
0
<
d
<
1
0<d<1
0<d<1,通过
ϕ
\phi
ϕ 得到的预测为
y
^
i
=
{
positive
ϕ
(
x
i
)
≥
d
negative
o.w.
\hat{y}_i=\left\{\begin{array}{ll}\text{positive} &\phi(x_i)\geq d\\ \text{negative}& \text{o.w.}\end{array}\right.
y^i={positivenegativeϕ(xi)≥do.w.通过比较预测
y
^
i
\hat{y}_i
y^i 和真实 label
y
i
y_i
yi,我们可以创建下面的 contingency table,常被称为 confusion matrix:
confusion matrix
| Prediction | Total | Measure | |||
|---|---|---|---|---|---|
| positive | negative | ||||
| True Label | positive | TP | FN | P | TPR=TP/P |
| negative | FP | TN | N | FPR=FP/N | |
| Total | P' | N' | N+P | ||
| Measure | FDR=FP/P' | NPV=TN/N' | |||
confusion matrix 中的所有值都取决于三个要素:真实数据,分类器 ϕ \phi ϕ,还有阈值 d d d。
通俗解释
我们以去医院检测癌症的病人为例。这时候,医院的诊断工具即为分类器:
- TP:有病而且被证实。
- FN:有病没检测出来。
- FP:好好的被误诊了。
- TN:认定没病,确实也没病。
- TPR:真阳率,反映的是检测能力,即敏感性。TPR 越高说明检测越敏感,天网恢恢疏而不漏,有病的都别想逃。
- FPR:假阳率,FPR 越高说明误诊率越高。即宁可错杀一千不可放过一个,没病的也别想走。
- FDR:伪阳率,FDR 高说明检测很不准确。抓了很多,实际上真正有病的并不多。
- NPV:真阴率,绝不冤枉一个好人。
Remark:
- FDR 的准确定义是一类错误率的期望,即 E [ FP P’ ] \mathrm{E}[\frac{\text{FP}}{\text{P'}}] E[P’FP],它对统计上特别是 multiple testing 方面非常重要。
- TPR 和 FPR 这两个指标结合起来可以判断诊断的好坏。一个好的诊断,应该要能将所有的病例揪出来,同时不误诊,不给健康的人造成心理上的伤害。如果能做到这两点,那我们有 TPR = 1,FPR = 0。但现实中要平衡这两点不是那么容易。因为揪出病例需要对病毒非常敏感,然而太敏感的话则容易误诊。
ROC 曲线和 AUC 值
我们已经说明,confusion matrix 是由分类器,数据以及阈值
d
d
d 决定的。给定数据和分类器
ϕ
\phi
ϕ 后,TP,TPR,FDR 这些数值仅仅由
d
d
d 决定。每给定一个
d
d
d,我们可以得到对应的
(
TPR(d),FPR(d)
)
(\text{TPR(d),FPR(d)})
(TPR(d),FPR(d))。遍历
d
∈
[
0
,
1
]
d\in[0,1]
d∈[0,1],把
(
TPR(d),FPR(d)
)
(\text{TPR(d),FPR(d)})
(TPR(d),FPR(d)) 画出来得到的即是 ROC 曲线,横轴为 FPR,纵轴为 TPR:
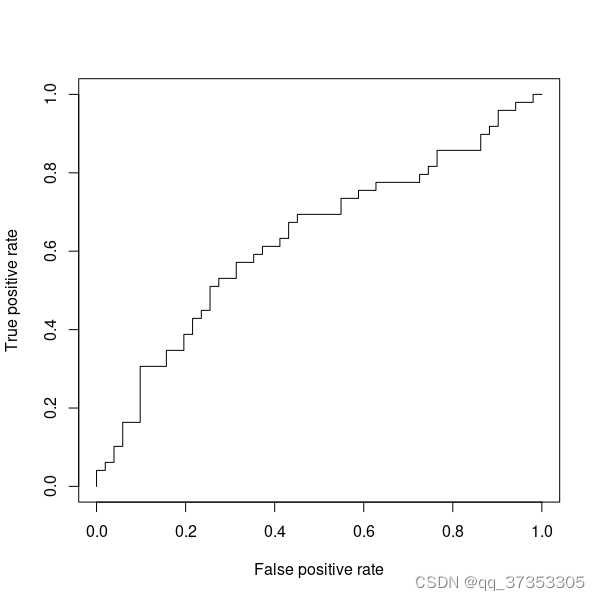
具体画法可以参考这个动图:

(gif 来源于https://github.com/dariyasydykova/open_projects/blob/master/ROC_animation/animations/cutoff.gif)
当然还有另外一种画法:把数据按
ϕ
(
x
i
)
\phi(x_i)
ϕ(xi) 由大到小排序。然后遍历排好序的数据,如果该样本真实标签为 positive,垂直向上走
1
/
P
1/P
1/P,反之水平向右走
1
/
N
1/N
1/N。如此遍历完样本后也可以得到ROC曲线:

(gif 来源于 http://mlwiki.org/index.php/ROC_Analysis)
而我们常说的 AUC,即是 ROC 曲线围成的右下部分的面积。
ROC 曲线越接近左上角 ( 0 , 1 ) (0,1) (0,1) 这个点,或者说 AUC越大,说明分类器效果越好。
试想,一个完美的 (Oracle) 分类器
ϕ
\phi
ϕ 应该能把所有阳性病人都映射到
1
1
1 上 (即认为这个人得病的概率为100%),同时把所有健康者映射到
0
0
0 上,i.e.,
ϕ
(
x
i
)
=
{
1
if
y
i
is positive
0
if
y
i
is negative
\phi(x_i)=\left\{\begin{array}{ll}1&\text{if } y_i \text{ is positive}\\0&\text{if } y_i \text{ is negative}\end{array}\right.
ϕ(xi)={10if yi is positiveif yi is negative这个时候,对于任意阈值
d
∈
(
0
,
1
)
d\in(0,1)
d∈(0,1),显然 TPR 总是 1,而 FPR 总是 0,对应的 ROC曲线即是连接左上角地正方形,AUC = 1,即下图的 perfect classifier:

(图片来源于 wiki: https://en.wikipedia.org/wiki/Receiver_operating_characteristic#Basic_concept)
虽然我们几乎不可能得到一个测试集上的完美分类器,但我们却可以轻而易举地得到训练集上的完美分类器,不是吗?
ROC Plot with R
我们使用 R 中的 package: ROCR 来画图。ROCR 是 R 中用来画 ROC curve 最常用的包。我们先生成一组随机数据, x x x 高斯, y y y 是线性 logistic model 来的:
# packages
library(ROCR) # ROC analysis
library(magrittr) # pipe operator
# seed
set.seed(1000)
# DGP
n <- 200
x <- n %>%
'*'(50) %>%
rnorm(mean = 0, sd = 1) %>%
matrix(data = ., nrow = 200)
w <- x[,1:3] %*% c(0.5,0.3,-0.4) - 0.1
prob <- 1/(1+exp(-w))
y <- rbinom(n = n, size = 1, prob = drop(prob))
dat <- data.frame(y, x)
把数据分成训练和测试集:
# split data into train and test
selct <- sample(1:n, size = 0.5*n, replace = FALSE)
train <- (1:n) %in% selct
test <- !train
训练集上拟合 logistic 模型:
# fit logistic model
model <- glm(y ~ X1 + X2 + X3 + 1, data = dat, subset = train,
family = binomial(link = "logit"))
summary(model)
预测:(记住,一定要加 response。)
# predict
prdict <- predict(model, newdata = dat, type="response")
用 ROCR 包画图:
# pre
pred <- prediction(predictions = prdict[test], labels = dat$y[test])
roc <- performance(pred,"tpr","fpr")
auc <- performance(pred, measure = "auc")@y.values[[1]]
# plot
plot(roc, colorize = F)
cat('AUC of the model on test data:', auc)
auc 为 0.611,效果很一般。auc = 0.5 的话说明分类器和乱分 (random classifier) 没有区别。
ROC 的概率解释 (Theory)
我们从 two distribution test 出发。假设有两个随机变量
X
X
X 和
Y
Y
Y,他们的分布函数分别为
F
X
F_X
FX 和
F
Y
F_Y
FY。我们想知道
X
X
X 和
Y
Y
Y 的分布是不是有差异的,即
H
0
:
F
X
=
F
Y
H_0: F_X=F_Y
H0:FX=FY against 备择假设
H
a
:
F
X
≠
F
Y
H_a:F_X\neq F_Y
Ha:FX=FY。定义 ROC 函数:
φ
(
q
)
=
{
0
q
=
0
1
−
F
X
(
F
Y
−
1
(
1
−
q
)
)
q
∈
(
0
,
1
)
1
q
=
1.
\varphi(q)=\left\{\begin{array}{ll}0&q=0\\1-F_X(F_Y^{-1}(1-q))&q\in(0,1)\\1&q=1.\end{array}\right.
φ(q)=⎩⎨⎧01−FX(FY−1(1−q))1q=0q∈(0,1)q=1.其中,
F
Y
−
1
(
x
)
=
inf
{
y
:
F
(
y
)
≥
x
}
F_Y^{-1}(x)=\inf\{y:F(y)\geq x\}
FY−1(x)=inf{y:F(y)≥x} 是
Y
Y
Y 的 quantile function (generalized inverse function)。我们先陈述
F
Y
−
1
(
x
)
F_Y^{-1}(x)
FY−1(x) 的性质:
- F Y − 1 ( q ) ≤ t F_Y^{-1}(q)\leq t FY−1(q)≤t iff. q ≤ F Y ( t ) . q\leq F_Y(t). q≤FY(t).
- F Y ( F Y − 1 ( q ) ) ≥ q F_Y(F_Y^{-1}(q))\geq q FY(FY−1(q))≥q,等式不成立的一个必要条件是 F Y F_Y FY 在 F Y − 1 ( q ) F^{-1}_Y(q) FY−1(q) 不连续。
- F Y ( F Y − 1 ( q ) ) ≡ q F_Y(F_Y^{-1}(q))\equiv q FY(FY−1(q))≡q for q ∈ ( 0 , 1 ) q\in(0,1) q∈(0,1) iff. F Y F_Y FY 在 定义上连续。
- F Y − 1 ( F Y ( q ) ) ≡ q F_Y^{-1}(F_Y(q))\equiv q FY−1(FY(q))≡q for q ∈ ( 0 , 1 ) q\in(0,1) q∈(0,1) iff. F Y F_Y FY 是严格单增的。
因此,我们可以知道,如果
F
X
F_X
FX 和
F
Y
F_Y
FY 都是连续且严格单调的,那么
F
X
−
1
F_X^{-1}
FX−1 和
F
Y
−
1
F_Y^{-1}
FY−1 和
F
X
F_X
FX 和
F
Y
F_Y
FY 一一对应,且
φ
(
q
)
=
q
\varphi(q)=q
φ(q)=q iff.
F
X
=
F
Y
F_X=F_Y
FX=FY。假设
X
X
X 和
Y
Y
Y 独立,基于 ROC 函数
φ
\varphi
φ,我们可以定义一个衡量
F
X
F_X
FX 和
F
Y
F_Y
FY 差异的 AUC measure:
auc
(
φ
)
=
∫
0
1
φ
(
q
)
d
q
=
p
r
(
X
>
Y
)
+
1
2
p
r
(
X
=
Y
)
.
\text{auc}(\varphi)=\int_{0}^1\varphi(q)dq=pr(X>Y)+\frac{1}{2}pr(X=Y).
auc(φ)=∫01φ(q)dq=pr(X>Y)+21pr(X=Y).以及 Kolmogorov-Smirnov measure:
ks
(
φ
)
=
sup
q
∈
[
0
,
1
]
∣
φ
(
q
)
−
q
∣
=
sup
s
∈
(
−
∞
,
∞
)
∣
F
X
(
s
)
−
F
Y
(
s
)
∣
.
\text{ks}(\varphi)=\sup_{q\in[0,1]}|\varphi(q)-q|=\sup_{s\in(-\infty,\infty)}|F_X(s)-F_Y(s)|.
ks(φ)=q∈[0,1]sup∣φ(q)−q∣=s∈(−∞,∞)sup∣FX(s)−FY(s)∣.
如果我们有从
X
X
X 中产生的独立数据
(
X
i
)
i
=
1
n
x
(X_i)_{i=1}^{n_x}
(Xi)i=1nx 和从
Y
Y
Y 中产生的独立数据
(
Y
j
)
j
=
1
n
y
(Y_j)_{j=1}^{n_y}
(Yj)j=1ny,基于该数据,auc measure 的一个自然的估计为:
auc
^
(
φ
)
=
∑
i
=
1
n
x
∑
i
=
1
n
y
(
1
X
i
>
Y
j
+
1
2
1
X
i
=
Y
j
)
n
x
⋅
n
y
.
\widehat{\text{auc}}(\varphi)=\frac{\sum_{i=1}^{n_x}\sum_{i=1}^{n_y}(1_{X_i>Y_j}+\frac{1}{2}1_{X_i=Y_j})}{n_x\cdot n_y}.
auc
(φ)=nx⋅ny∑i=1nx∑i=1ny(1Xi>Yj+211Xi=Yj).这正是 Mann-Whitney statistic,它是一个 U 统计量。
现在,回到之前的二分类问题。我们有 train data,我们在 train data 上训练得到训练器
ϕ
\phi
ϕ。我们有 test data
(
x
i
,
y
i
)
i
=
1
P
+
N
(x_i,y_i)_{i=1}^{P+N}
(xi,yi)i=1P+N。由此,我们可以计算出
TPR
(
d
)
=
∑
y
i
=
1
1
ϕ
(
x
i
)
>
d
P
\text{TPR}(d)=\frac{\sum_{y_i=1}1_{\phi(x_i)> d}}{P}
TPR(d)=P∑yi=11ϕ(xi)>d,
FPR
(
d
)
=
∑
y
i
=
0
1
ϕ
(
x
i
)
>
d
N
\text{FPR}(d)=\frac{\sum_{y_i=0}1_{\phi(x_i)> d}}{N}
FPR(d)=N∑yi=01ϕ(xi)>d。我们注意到,
1
−
TPR
(
d
)
1-\text{TPR}(d)
1−TPR(d) 和
1
−
FPR
(
d
)
1-\text{FPR}(d)
1−FPR(d) 都是关于
d
d
d 的分布函数,满足单增右连续的性质。假设数据都是 I.I.D. 的,则由大数定律,当
P
P
P 和
N
N
N 趋于无穷的时候,我们有
TPR
(
d
)
→
TPF
(
d
)
=
p
r
[
ϕ
(
x
)
>
d
∣
y
=
1
]
\text{TPR}(d)\rightarrow \text{TPF}(d)=pr[\phi(x)> d|y=1]
TPR(d)→TPF(d)=pr[ϕ(x)>d∣y=1],
FPR
(
d
)
→
FPF
(
d
)
=
p
r
[
ϕ
(
x
)
>
d
∣
y
=
0
]
\text{FPR}(d)\rightarrow \text{FPF}(d)=pr[\phi(x)> d|y=0]
FPR(d)→FPF(d)=pr[ϕ(x)>d∣y=0]。令
z
1
=
d
ϕ
(
x
)
∣
y
=
1
z_1\overset{d}{=}\phi(x)|y=1
z1=dϕ(x)∣y=1,
z
0
=
d
ϕ
(
x
)
∣
y
=
0
z_0\overset{d}{=}\phi(x)|y=0
z0=dϕ(x)∣y=0,则
z
k
z_k
zk 的分布函数为
F
z
k
(
t
)
=
p
r
(
z
k
≤
t
)
=
p
r
(
ϕ
(
x
)
≤
t
∣
y
=
k
)
F_{z_k}(t)=pr(z_k\leq t)=pr(\phi(x)\leq t|y=k)
Fzk(t)=pr(zk≤t)=pr(ϕ(x)≤t∣y=k)。由前面的分析,为了检验
z
1
z_1
z1 和
z
0
z_0
z0 是不是同分布的,我们构造
φ
(
q
)
=
1
−
F
z
1
∘
F
z
0
−
1
(
1
−
q
)
.
{\varphi}(q)=1-F_{z_1}\circ F_{z_0}^{-1}(1-q).
φ(q)=1−Fz1∘Fz0−1(1−q).令
q
=
FPF
(
d
)
q= \text{FPF}(d)
q=FPF(d),可得
roc
ϕ
(
d
)
=
φ
(
FPF
(
d
)
)
=
1
−
p
r
(
z
1
≤
F
z
0
∘
F
z
0
−
1
(
d
)
)
=
p
r
(
z
1
>
d
)
=
TPR
(
d
)
.
\text{roc}_{\phi}(d)={\varphi}(\text{FPF}(d))=1-pr(z_1\leq F_{z_0}\circ F^{-1}_{z_0}(d))=pr(z_1>d)=\text{TPR}(d).
rocϕ(d)=φ(FPF(d))=1−pr(z1≤Fz0∘Fz0−1(d))=pr(z1>d)=TPR(d). 当然,用
TPR
(
d
)
\text{TPR}(d)
TPR(d) 和
FPR
(
d
)
\text{FPR}(d)
FPR(d) 去估计
TPF
(
d
)
\text{TPF}(d)
TPF(d) 和
FPF
(
d
)
\text{FPF}(d)
FPF(d),我们就得到了最开始所述的 ROC 曲线。所以可以看成是要检验
H
0
:
ϕ
(
x
)
∣
y
=
1
=
d
ϕ
(
x
)
∣
y
=
0
H_0: \phi(x)|y=1\overset{d}{=} \phi(x)|y=0
H0:ϕ(x)∣y=1=dϕ(x)∣y=0。右下角的 auc 面积即
auc
^
(
ϕ
)
=
∫
0
1
TPR
(
t
)
FPR
(
d
t
)
=
∑
i
=
1
N
1
N
∑
j
=
1
P
(
1
z
1
j
>
z
0
i
P
+
1
z
1
i
=
z
0
j
2
P
)
=
1
N
P
∑
y
i
=
1
∑
y
j
=
0
(
1
ϕ
(
x
i
)
>
ϕ
(
x
j
)
+
1
2
1
ϕ
(
x
i
)
=
ϕ
(
x
j
)
)
\widehat{\text{auc}}(\phi)=\int_{0}^1 \text{TPR}(t)\text{FPR}(dt)=\sum_{i=1}^N\frac{1}{N}\sum_{j=1}^P\left(\frac{1_{z_{1j}>z_{0i}}}{P}+\frac{1_{z_{1i}=z_{0j}}}{2P}\right)=\frac{1}{NP}\sum_{y_i=1}\sum_{y_j=0}\left(1_{\phi(x_i)>\phi(x_j)}+\frac{1}{2}1_{\phi(x_i)=\phi(x_j)}\right)
auc
(ϕ)=∫01TPR(t)FPR(dt)=i=1∑NN1j=1∑P(P1z1j>z0i+2P1z1i=z0j)=NP1yi=1∑yj=0∑(1ϕ(xi)>ϕ(xj)+211ϕ(xi)=ϕ(xj))这正是 Mann-Whitney U statistics,它收敛于
p
r
(
ϕ
(
x
1
)
>
ϕ
(
x
0
)
∣
y
1
=
1
,
y
0
=
0
)
pr(\phi(x_1)>\phi(x_0)|y_1=1,y_0=0)
pr(ϕ(x1)>ϕ(x0)∣y1=1,y0=0)。

















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}