







 本文介绍了模型评估的重要性,详细讲解了经验误差与过拟合的概念,提出降低过拟合的策略。接着阐述了评估方法,如留出法、交叉验证和自助法。重点讨论了性能度量,包括P-R曲线、F1分数和ROC曲线,这些是衡量分类任务性能的关键指标。最后,提到了比较检验,如二项检验和t检验,用于确定不同模型的性能差异。
本文介绍了模型评估的重要性,详细讲解了经验误差与过拟合的概念,提出降低过拟合的策略。接着阐述了评估方法,如留出法、交叉验证和自助法。重点讨论了性能度量,包括P-R曲线、F1分数和ROC曲线,这些是衡量分类任务性能的关键指标。最后,提到了比较检验,如二项检验和t检验,用于确定不同模型的性能差异。
经验误差与过拟合
错误率: 错分样本的占比:E = a/m
误差:样本真实输出与预测输出之间的差异
训练(经验)误差:训练集上
测试误差:测试集
泛化误差:除训练集外所有样本
由于事先并不知道新样本的特征,我们只能努力使经验误差最小化;
很多时候虽然能在训练集上做到分类错误率为零,但多数情况下这样的学习器并不好。
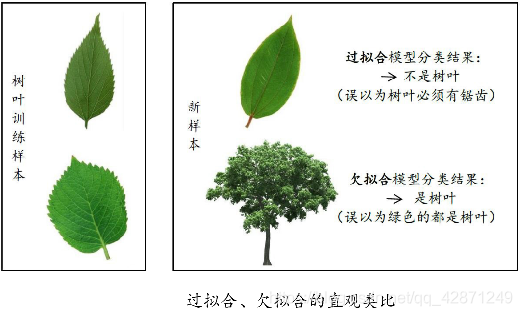
过拟合:
学习器把训练样本学习的“太好”,将训练样本本身的特点 当做所有样本的一般性质,导致泛化性能下降。从而导致在测试集上的预测效果比训练集差很多。
过拟合的解决办法:
1、优化目标加正则项https://blog.csdn.net/qq_42871249/article/details/104659074
2、early stop
欠拟合:
训练样本的一般性质尚未被学习器学好
决策树:拓展分支
神经网络:增加训练轮数
评估方法
评估原则:
现实任务中往往会对学习器的泛化性能、时间开销、存储开销、可解释性等方面的因素进行评估并做出选择
我们假设测试集是从样本真实分布中独立采样获得,将测试集上的**“测试误差”作为泛化误差的近似**,所以测试集要和训练集中的样本尽量互斥。
通常将包含个m样本的数据集D拆分成训练集S和测试集T:
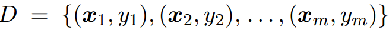
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









