







目录
Review
先复习一下寒假前的代码Brenda Parser README。这个版本的代码实现的功能是为每一个EC号维护一个酶表(库),物质表和酶-物质相互作用表。目前需要改进的方向:
- 定义反应方程式表(实际上在处理过程中也整理出来了),参考文献表,酶命名表等一系列我们可能感兴趣的文摘内容。
- 将各个EC号各自维护的内容表融合成全局的表格,主要是反应表,物质表和参考文献表。
在进行内容整理的同时也要思考,可以利用现有Brenda的全局知识,进行一些怎样的研究趋势的分析?
Target
整理Brenda的内容,希望提供一个细粒度版本的酶-反应关联。Brenda的细粒度由酶的生物来源定义,同时在反应上链接了参考文献信息。生物来源+参考文献,使得Brenda的内容相比Rhea而言要显得精确。
TODO
表格
按照Rhea的反应表述方式来整理,那么需要的表格有
reaction.tsv
表达反应-物质关联:
reaction_reactionSide.tsv
reactionSide_reactionParticipants.tsv
reactionParticipants_compound.tsv
compound.tsv
表达反应-酶关联:
reactionSide_catalysisParticipants.tsv
catalysitsParticipants_enzyme.tsv
enzyme.tsv
表达反应-文献关联:
reaction_reference.tsv
reference.tsv
它们之间的关联关系可以用【酶反应信息数字化-v3.1】中的这幅图(表达方案参考Rhea数据库)来表示:
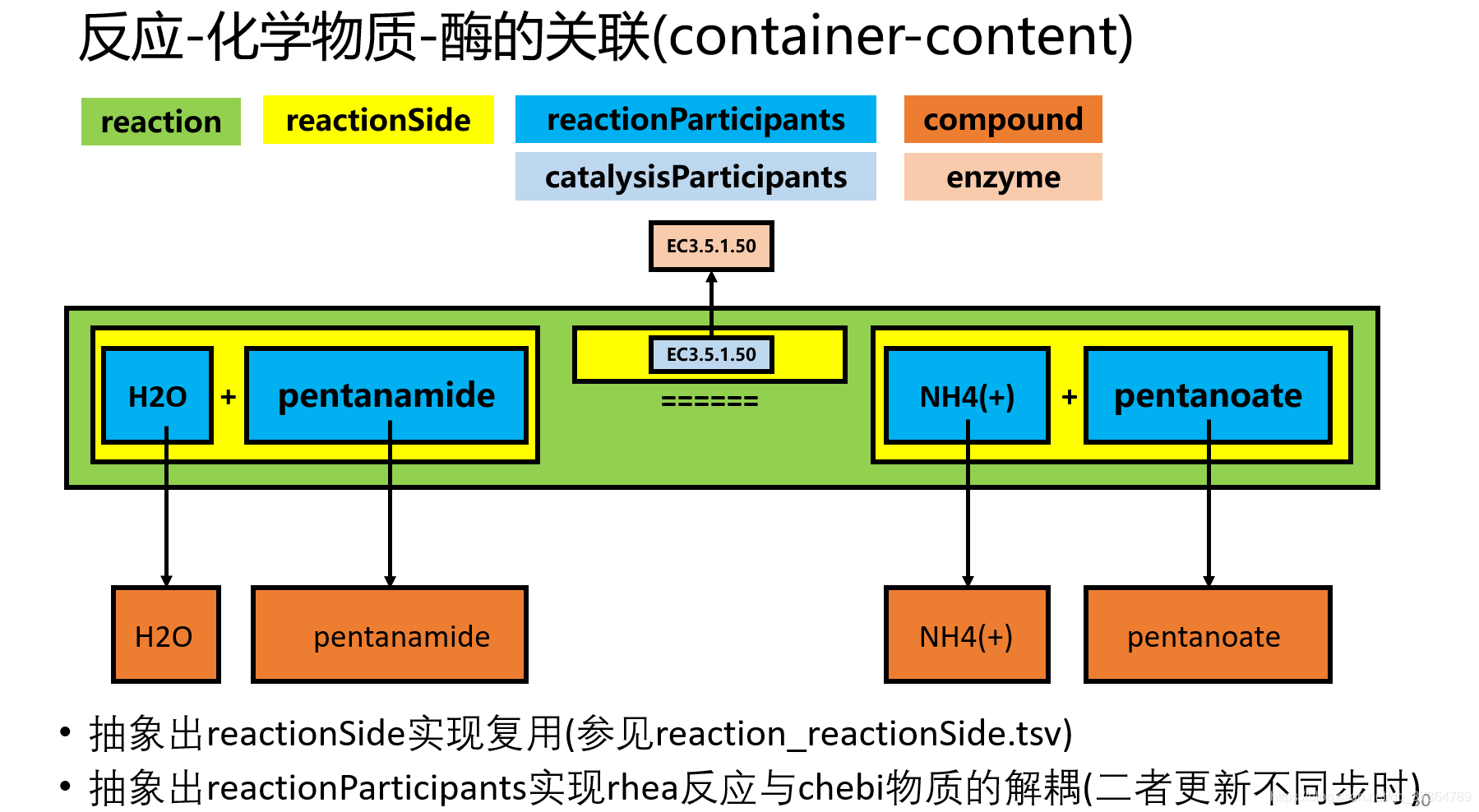
对上图的补充说明:
- container-content 这一对词形象说明了Side和Participants, Participants和compound/enzyme之间的关系。Reaction实际上是一个有三个桌子的屋子,每个桌子上又可以放许多个茶杯,而每个茶杯里倒的茶才是“真正”的实体。
表项
从构建的角度,明确每一个表的表项。我们来逐表分析一下。
- reaction.tsv
ID数字编号
name: [br:ID] (如同rh:ID在Rhea数据库中一样)
label: 反应的表示
is_complete: 记录是否完整(True/False)
is_approved: 记录是否被自动补全工具所验证(True/False)
source_page: 来源EC号页面(不同EC号之间可能有重复的反应,方便追溯和比对)
feature_code: 特征码(类似于反应的Hash码,仅对approved的反应定义,用于反应消歧)
DataSource: Brenda reaction_reactionSide.tsv (不定义反应方向的情况下,无法重用,不必要的表)
reaction_name: [br:ID]
relation_type: 枚举值(substrates, products, catalysts)
reaction_side_name: [br:ID_L|R|C]- reactionSide_reactionParticipants.tsv
reaction_name:[br:ID]
relation_type: 枚举值(substrate, product)
coefficient: 化学计量数, -1代表未定义。
reaction_participant_ID:该表的Key。
reaction_participant_name:[br:RP_ID]
label:如果compound_ID未定义,那么采用该label;否则,采用compound_ID的label。
is_complete
compound_name:[br:COM_ID] reactionParticipants_compound.tsv
reaction_participant_name
label:reaction_participant 的表示
compound_ID:[br:Compound_ID]- compound.tsv
ID
name: [br:Compound_ID]
accession: 检索号 [BRENDA: num] (仿佛还没有定义)
label
is_complete
formula: 分子式 (Brenda中不具有,需要与其它数据库交叉得到)
charge: 电荷 (Brenda中不具有)
source_page
feature_code - reactionSide_catalysisParticipants.tsv
reaction_name:[br:ID]
catalysis_participant_ID
name:[br:CP_ID]
label:如果enzyme_ID未定义,那么采用该label;否则,采用enzyme_ID的label。
is_complete
enzyme_name:[br:ENZ_ID] catalysitsParticipants_enzyme.tsv
catalysis_participant_name
label: catalysis_participant 的表示
enzyme_ID:[br:Enzyme_ID]- enzyme.tsv
ID
name:[br:Enzyme_ID]
accession
label:enzyme的表示
EC:酶的EC号
i:该EC号下的编号
source_organism:来源生物(字符串表示) - reaction_reference.tsv
reaction_name:[br:ID]
reference_name:[br:Ref_ID] - reference.tsv
ID:朴素的数字编号
name:[br:Ref_ID]
accession
label:reference的表示
is_complete
year:发表时间
source_page: 来源EC号(不同EC号之间可能有重复的文献记录,方便追溯和比对) - enzyme_atlas.tsv
略。 - organism.tsv
略。
说明一些规则:
- 具有ID号的表,ID号为Key,name由ID号生成,因此上述关系表中的name可以由ID号完全替换,在下面的图中便是这么表达的。
- source_page:由于整理总表是逐EC号进行的,为了给记录留痕,添加source_page来记录具有该记录的EC页面;但对于一些过于普适的记录,如小分子物质等,不进行记录。
- is_complete:在具有内容的几个表中均有均有is_complete来表示该条记录是否完整,其各有自己的判断标准;更新可以使不完整的记录完善。
表的主键设置及索引关系:
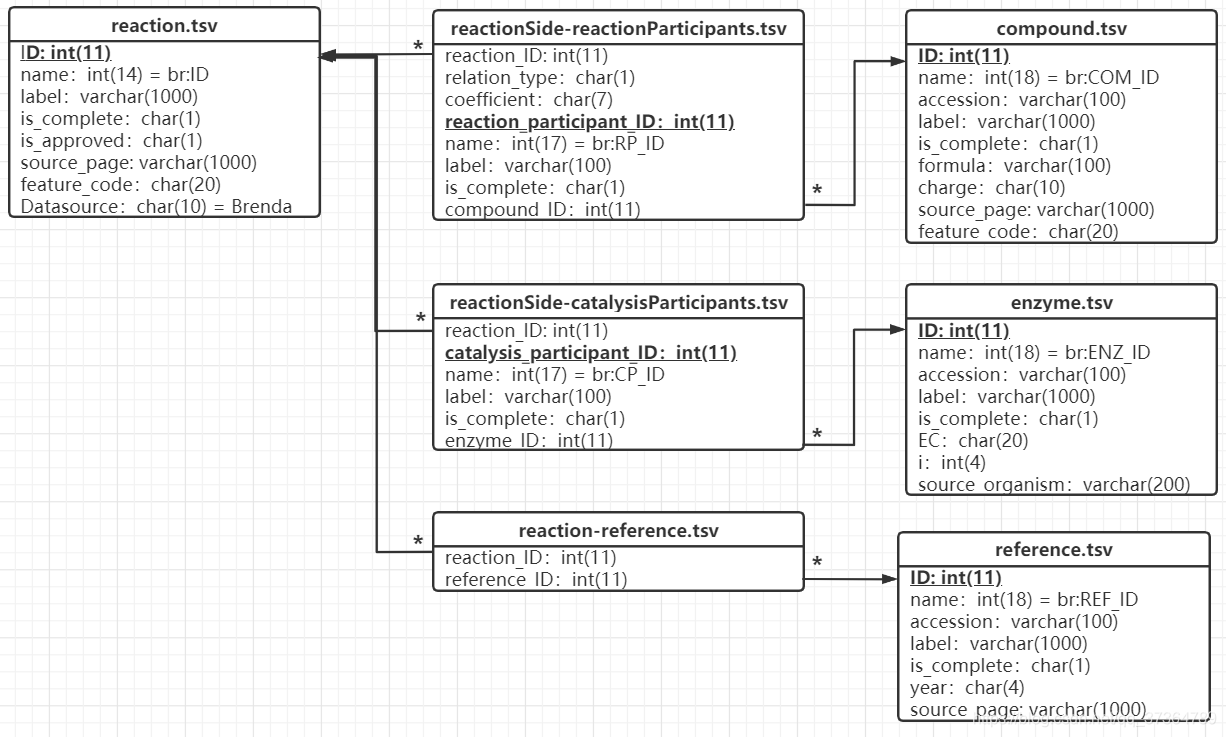
表项对任务的支持
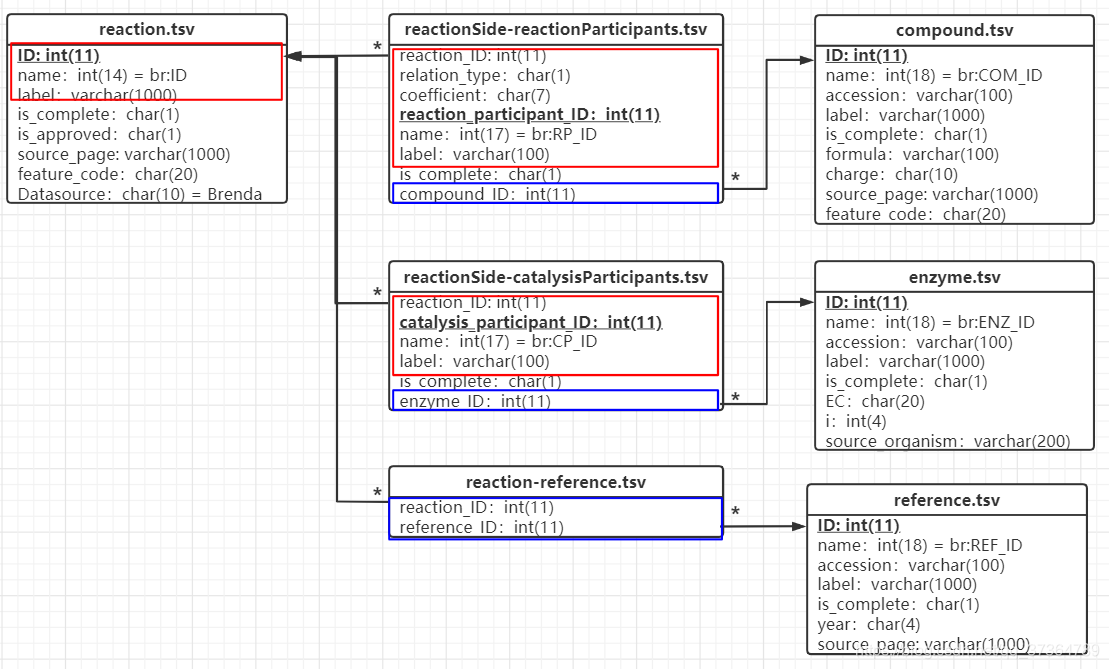
基于上图示,说明表项更新与检索时的流程:
- 反应的表示与关联
下图红框中为表示反应所必要的信息(ID,Name的定义不会展现在UI上),蓝框中为反应与化学物质、酶、参考文献的关联,这些信息使得可以通过酶、化合物、文献将多个反应关联起来。
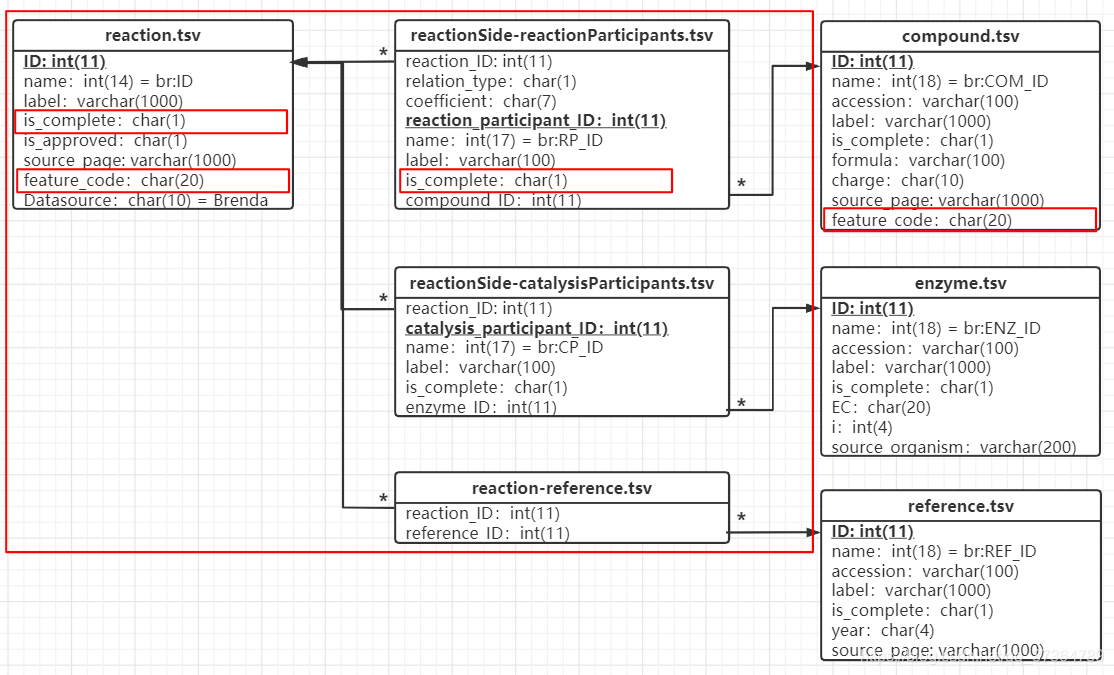
- 添加反应
根据反应的已知信息,给下面各个表格添加内容;通过反应、化合物、酶、文献的feature_code来消歧(判断反应是否在表格中),利用is_complete来标注条目的信息完善程度。
- 更新反应
分为更新元数据与更新关联数据两类。元数据更新与添加反应类似。更新关联数据即对三个关系表中的ID进行更新即可。 - 添加化学物质/酶/参考文献
略。
从Brenda中获取信息,整理为数据表格式
该任务分解如下:
- 为每一个EC页面生成自己的反应、酶、化合物、参考文献 Records。参考Brenda Parser README
- 整理全局的化合物、酶、参考文献表。
- 整理全局的反应表。
- 建立反应表与其它三个表的关联关系。
下面图示各个表项的资料来源。
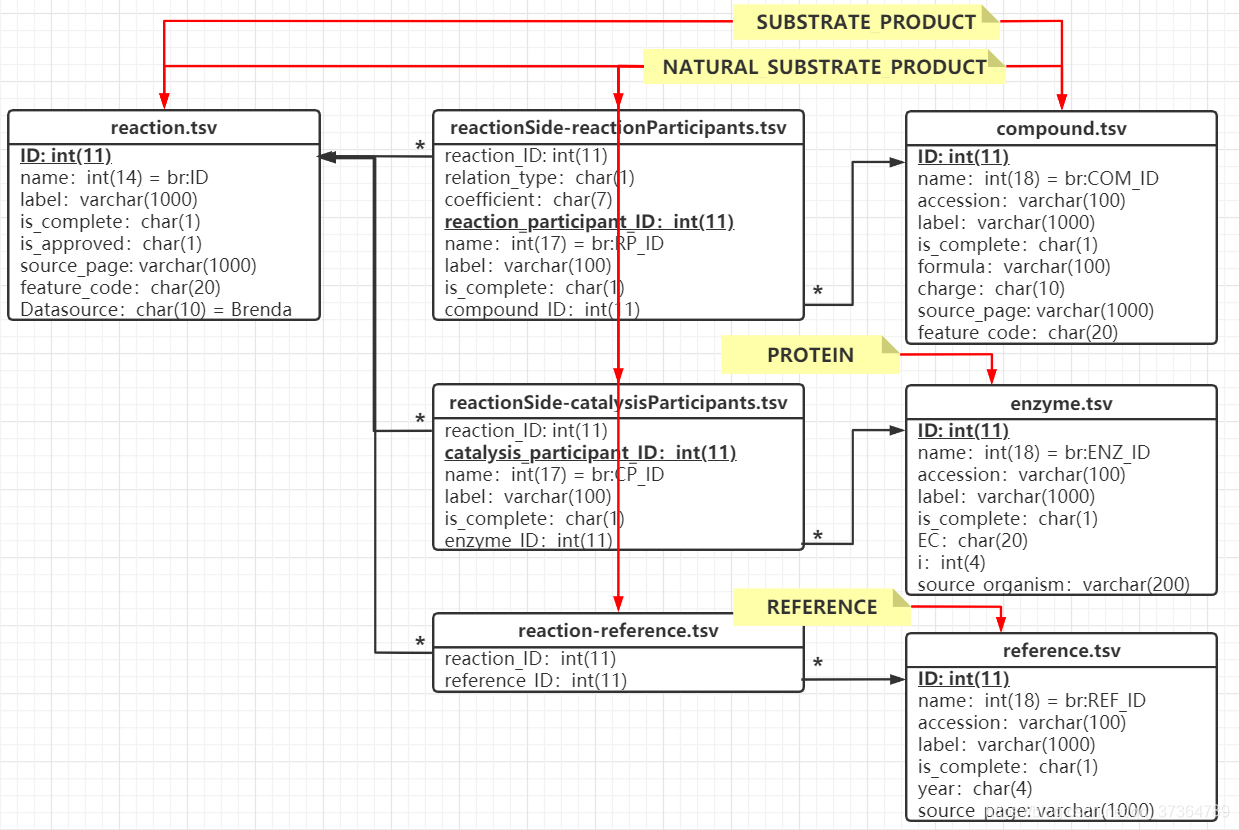
相比之前,主要是添加了REFERENCE的内容,也需要在关系中体现出来。
代码工作
为genTables()添加REFERENCE的正则表达式
参考文献的格式如下。
<2> O’Connor, K.C.; Bailey, J.E.: Hydrolysis of emulsified tributyrin by porcine pancreatic lipase. Enzyme Microb. Technol. (1988) 10, 352-356. {Pubmed:} (c)
使用的正则表达式如下:
'<([\d]+)> (.+?) {Pubmed:[\d]*}(?: \(c\))?'
由此,在Page的Tables中可以取到REFERENCE表格。
测试代码对于整个文件的鲁棒性
多个\t分隔符
修复了一处bug。
'\t’作为分隔符,默认是一行只有一个的,如下:

但是,有的行有两个以上:

在得到record的时候只取了第一个,便可能会有问题,因此,将record的代码改为:
record = line.split('\t')[1][:-1] # 原版本
record = ' '.join(line.split('\t')[1:])[:-1] # 修改后
解决了这个问题。
边缘情况:{Pubmed:n}
另外,还有一处{Pubmed:n}的bug,在REFERENCE的正则表达式中添加了n,解决了这个问题。
提取全局表信息
主要是将之前的局部表信息整合进全局表,代码多有重复,实际上是又重新写了一遍。
首先是各个表格实际可以得到的与需要的内容:
'''
Returns
-------
compound : List of (ID, label)
enzyme : List of (ID, label, EC, i, source_organism)
reference : List of (ID, label, source_page, i)
reaction : List of (ID, label, is_complete, is_approved, source_page, Datasource)
rS_rP : List of (rID, relation_type, rPID, label, cID)
rS_cP : List of (rID, cPID, label, eID)
r_r : List of (rID, refID)
'''
采用一个大字典TSV保存所有的形式,最后输出该字典。
def genTSVs(self):
TSVs = {'compound':[], 'enzyme':[], 'reference':[], 'reaction':[],
'rS_rP':[], 'rS_cP':[], 'r_r':[], }
return TSVs
genTSVs的主要部分是循环Brenda的Pages,根据Pages已做好的保存信息的格式化的str方式存储的Tables,整理输出为各个TSVs。
page.Tables[‘PROTEIN’] >> TSVs[‘enzyme’]
page.Tables[‘REFERENCE’] >> TSVs[‘reference’]
page.Tables[‘NATURAL_SUBSTRATE_PRODUCT’] + page.Tables[‘SUBSTRATE_PRODUCT’] >> Other TSVs.
一些说明:
- enzyme和reference都是原Table整理得很好的,耦合也没反应那么强,所以直接拿出来就能用。
- compound可以通过外部导入数据库的方式来做比对,这里仍是通过反应来提取。
- compound 和 reaction 考虑了不同page之间重复的可能,所以各自用了一个dict+判断来将label映射到ID来消歧。
输出为tsv文件
将输出的TSVs保存为文件:
def toTSVFile(TSVs):
for table_name, entries in TSVs.items():
with open(os.path.join('brenda_tables', table_name + '.tsv'), 'w') as f:
f.write('\n'.join('\t'.join(str(item) for item in entry) for entry in entries))
信息统计:
for table_name, entries in TSVs.items():
print('{:>10}: {:>7,}'.format(table_name,len(entries)))
'''
compound: 109,157
enzyme: 95,145
reference: 163,605
reaction: 109,278
rS_rP: 409,475
rS_cP: 473,907
r_r: 557,709
'''
More TODO
至此,基本的信息就提取结束。但是,由于Brenda的“粗糙”,其格式不一致现象严重,例如:
compound.tsv
在compound.tsv中搜索“H2O”,可以得到以下五花八门的“H2O”:
68 H2O
207 H2o
5593 2 H2O
8406 2 H2O ?
21479 + H2O
62003 h2O
等等。
其中有一些是带有化学计量数的,有大小写不一致的,错误划分“+”的,等等。
enzyme.tsv
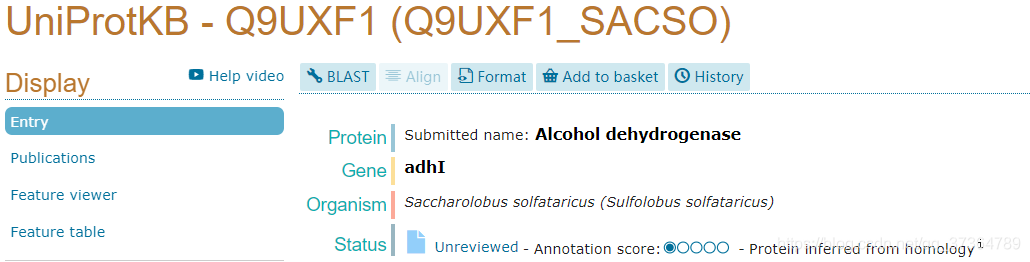
在enzyme.tsv中,根据来源生物来区分同种不同源(同一EC号不同来源与不同序列)的酶,其名字中有一些带有Uniprot及编号,指代了其序列来源,这个信息应当再划分一列:Uniprot ID来展示(如Brenda所做的那样)。
94 1.1.1.1_95 1.1.1.1 94 Saccharolobus solfataricus Q9UXF1 UniProt
reference.tsv
对于reference.tsv,提取其元数据,做一个研究趋势分析(Wildman提建议:为什么不用WoS来做呢?)。
(实际上Brenda中是有2019/2020年的数据的…)
(2018):1977
(2019):691
(2020):20
122497 Maianti, J.P.; Tan, G.A.; Vetere, A.; Welsh, A.J.; Wagner, B.K.; Seeliger, M.A.; Liu, D.R.: Substrate-selective inhibitors that reprogram the activity of insulin-degrading enzyme. Nat. Chem. Biol. (2019) 15, 565-574. 3.4.24.56 130
(这个格式似乎是一个home-made的格式,不属于以下的主流参考文献格式规范)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









