







Availability
1. General Scenario
Source of stimulus: We differentiate between internal and external origins of faults or failure because the desired system response may be different.
Stimulus: A fault of one of the following classes occurs:
- Omission. A component fails to respond to an input.
- Crash. The component repeatedly suffers omission faults.
- Timing. A component responds but the response is early or late.
- Response. A component responds with an incorrect value.
Artifact: This specifies the resource that is required to be highly available, such as a processor, communication channel, process, or storage.
Environment: The state of the system when the fault or failure occurs may also affect the desired system response.
Response: There are a number of possible reactions to a system fault.
Response measure: The response measure can specify an availability percentage, or it can specify a time to detect the fault, time to repair the fault, times or time intervals during which the system must be available, or duration for which the system must be available.
| Portion of | Possible Values |
| Source | Internal/external: people, hardware, software, physical infrastructure, physical environment |
| Stimulus | Fault: omission, crash, incorrect timing, incorrect response |
| Artifact | System’s processors, communication channels, persistent storage, processes |
| Environment | Normal operation, startup, shutdown, repair mode, degraded operation, overloaded operation |
| Response | Prevent the fault from becoming a failure Detect the fault: · log the fault · notify appropriate entities (people or systems) Recover from the fault · disable the source of events causing the fault · be temporarily unavailable while the repair is being affected · fix or mask the fault/failure or contain the damage it causes · operate in a degraded mode while the repair is being affected |
| Response | Time or time interval when the system must be available Availability percentage (e.g. 99.999%) Time to detect the fault Time to repair the fault Time or time interval in which system can be in degraded mode Proportion (e.g., 99%) or rate (e.g., up to 100 per second) of a certain class of faults that the system prevents, or handles without failing |
2. Tactics
2.1 Detect Faults
Tactics categories:
- Ping/echo: determining reachability and the round-trip delay through the associated network path using request/response pair.
- Monitor: monitoring the state of health of other parts of the system.
- Heartbeat: a periodic message exchange between a system monitor and a process being monitored(responsibility of initiation of health state is held by the monitor, while in ping/echo, it is held by the component itself).
- Timestamp: used to detect incorrect sequences of events, primarily in distributed message passing systems.
- Sanity checking: checking the validity or reasonableness of a component's operations or outputs.
- Condition monitoring: checking conditions in a process or a device, or validating assumptions made during the design.
- Voting: checking that replicated components are producing the same results.
- Exception: detection of a system condition that alters the normal flow of execution.
- Self-test: procedure for a component to test itself for correct operation.
2.2 Recover from Faults
Tactics categories:
- Active redundancy(hot spare): all nodes in a protection group receive and process identical inputs in parallel. So, when the active node breaks, the spare can take over its task in milliseconds.
- Passive redundancy(warm spare): only active nodes in the protection group process input traffics, while the redundant spares are only updated.
- Spares(cold spare): redundant spares remain out of service until a fail-over occurs, at which point a power-on-reset procedure is initiated on the redundant spare prior to its being placed in service.
- Exception handling: dealing with the exception by reporting it or handling it, potentially masking the fault by correcting the cause of the exception and retrying.
- Rollback: revert to a previous known good state, referred to as the "rollback line".
- Software upgrade: in-service upgrades to executable code images in a non-service-affecting manner.
- Retry: if the fault is transient, retrying the operation may lead to success.
- Ignore faulty behavior: ignoring the messages sent from a source when they are determined to be spurious.
- Degradation: maintaining the most critical system functions in the presence of component failures, dropping less critical functions.
- Reconfiguration: reassigning responsibilities to the resources left functioning while maintaining as much functionality as possible.
- Shadow: operating a previously failed or in-service upgraded component in a “shadow mode” for a predefined time prior to reverting the component back to an active role.
- State resynchronization: partner to active redundancy and passive redundancy where state information is sent from active to standby components.
- Escalating Restart: recover from faults by varying the granularity of the component(s) restarted and minimizing the level of service affected.
- Non-stop Forwarding: functionality is split into supervisory and data. If a supervisor fails, a router continues forwarding packets along known routes while protocol information is recovered and validated.
2.3 Prevention
Tactics categories:
- Removal From Service: temporarily placing a system component in an out-of-service state for the purpose of mitigating potential system failures
- Transactions: bundling state updates so that asynchronous messages exchanged between distributed components are atomic, consistent, isolated, and durable.
- Predictive Model: monitor the state of health of a process to ensure that the system is operating within nominal parameters; take corrective action when conditions are detected that are predictive of likely future faults.
- Exception Prevention: preventing system exceptions from occurring by masking a fault, or preventing it via smart pointers, abstract data types, wrappers.
- Increase Competence Set: designing a component to handle more cases—faults—as part of its normal operation.
3. Summary

Interoperability
Interoperability is about the degree to which two or more systems can usefully exchange meaningful information.
Like all quality attributes, interoperability is not a yes-or-no proposition but has shades of meaning.
1. General Scenario
Source of Stimulus: A system initiates a request to interoperate with another system.
Stimulus: A request to exchange information among the system(s).
Artifact: The systems that wish to interoperate.
Environment: The systems that wish to interoperate are discovered at runtime or are known prior to runtime.
Response: The request to interoperate results in the exchange of information. The information is understood by the receiving party both syntactically and semantically. Alternatively, the request is rejected and appropriate entities are notified. In either case, the request may be logged.
Response measure: The percentage of information exchanges correctly processed or the percentage of information exchanges correctly rejected.
| Portion of | Possible Values |
| Source | A system |
| Stimulus | A request to exchange information among the system(s). |
| Artifact | The systems that wish to interoperate |
| Environment | System(s) wishing to interoperate are discovered at runtime or known prior to run time. |
| Response | One or more of the following: ·the request is (appropriately) rejected and appropriate entities (people or systems) are notified ·the request is (appropriately) accepted and the information is exchanged successfully ·the request is logged by one or more of the involved systems |
| Response | One or more of the following: ·percentage of information exchanges correctly processed ·percentage of information exchanges correctly rejected
|
2. Interoperability Tactics
2.1 Locate
Categories:
- Discover service: Locating a service through searching a known directory service. There may be multiple levels of indirection in this location process – i.e. a known location points to another location that in turn can be searched for the service.
2.2 Manage Interfaces
Categories:
- Orchestrate: using a control mechanism to coordinate, manage and sequence the invocation of services. The orchestration is used when systems must interact in a complex fashion to accomplish a complex task.
- Tailor Interface: adding or removing capabilities to an interface such as translation, buffering, or data-smoothing.
3. Summary

Modifiability
Modifiability is about to change. And our interest in it is in the cost and risk of making changes.
To plan for modifiability, an architect has to consider three questions:
- –What can change?
- –What is the likelihood of the change?
- –When is the change made and who makes it?
1. General Scenario
Source of Stimulus: This portion specifies who makes the change.
Stimulus: This portion specifies the change to be made.
Artifact: This portion specifies what is to be changed: specific components or modules, the system's platform, its user interface, its environment, or another system with which it interoperates.
Environment: This portion specifies when the change can be made: design time, compile time, build time, initiation time, or runtime.
Response: Make the change, test it, and develop it.
Response Measure: All of the possible responses take time and cost money.
| Portion of | Possible Values |
| Source | The end user, developer, system administrator |
| Stimulus | A directive to add/delete/modify functionality, or change a quality attribute, capacity, or technology |
| Artifacts | Code, data, interfaces, components, resources, configurations, … |
| Environment | Runtime, compile time, build time, initiation time, design time |
| Response | One or more of the following: ·make modification ·test modification ·deploy modification |
| Response
| Cost in terms of: ·number, size, the complexity of affected artifacts ·effort ·calendar time ·money (direct outlay or opportunity cost) ·extent to which this modification affects other functions or quality attributes ·new defects introduced |
2. Tactics for Modifiability
2.1 Reduce the Size of a Module
Categories:
- Split modules: If the module being modified includes a great deal of capability, the modification costs will likely be high. Refining the module into several smaller modules should reduce the average cost of future changes.
2.2 Increase Cohesion
Categories:
- Increase semantic coherence: If the responsibilities A and B in a module do not serve the same purpose, they should be placed in different modules. This may involve creating a new module or it may involve moving responsibility to an existing module.
2.3 Reduce Coupling
Categories:
- Encapsulate: Encapsulation introduces an explicit interface to a module. This interface includes an API and its associated responsibilities, such as “perform a syntactic transformation on an input parameter to an internal representation.”
- Use an intermediary: Given a dependency between responsibility A and responsibility B (for example, carrying out A first requires carrying out B), the dependency can be broken by using an intermediary.
- Restrict dependencies: Restricts the modules which a given module interacts with or depends on.
- Refactor: Undertaken when two modules are affected by the same change because they are (at least partial) duplicates of each other.
- Abstract common services: Where two modules provide not-quite-the-same but similar services, it may be cost-effective to implement the services just once in a more general (abstract) form.
3. Summary

Performance
Performance is about time and the software system’s ability to meet timing requirements.
1. General Scenario
Source of Stimulus: The stimuli arrive either from external (possibly multiple) or internal sources.
Stimulus: The stimuli are the event arrivals.
Artifact: The artifact is the system or one or more of its components.
Environment: The system can be in various operational modes, such as normal, emergency, peak load, or overload.
Response: The system must process the arriving events.
Response Measure: The response measures are the time it takes to process the arriving events (latency or deadline), the variation in this time (jitter), the number of events that can be processed within a particular time interval (throughput), or a characterization of the the events that cannot be processed (miss rate).
| Portion of Scenario | Possible Values |
| Source | Internal or external to the system |
| Stimulus | The arrival of a periodic, sporadic, or stochastic event |
| Artifact | System or one or more components in the system. |
| Environment | Operational mode: normal, emergency, peak load, overload. |
| Response | Process events, change the level of service |
| Response Measure | Latency, deadline, throughput, jitter, the miss rate |
2. Tactics for Performance
2.1 Control Resource Demand
Categories:
- Manage sampling rate: If it is possible to reduce the sampling frequency at which a stream of data is captured, then demand can be reduced, typically with some loss of fidelity.
- Limit event response: Process events only up to a set maximum rate, thereby ensuring more predictable processing when the events are actually processed.
- Prioritize events: If not all events are equally important, you can impose a priority scheme that ranks events according to how important it is to serve them.
- Reduce overhead: The use of intermediaries (important for modifiability) increases the resources consumed in processing an event stream; removing them improves latency.
- Bound execution time: Place a limit on how much execution time is used to respond to an event.
- Increase resource efficiency: Improving the algorithms used in critical areas will decrease latency.
2.2 Manage Resource
Categories:
- Increase resources: Faster processors, additional processors, additional memory, and faster networks all have the potential for reducing latency.
- Increase concurrency: If requests can be processed in parallel, the blocked time can be reduced. Concurrency can be introduced by processing different streams of events on different threads or by creating additional threads to process different sets of activities.
- Maintain multiple copies of computations: The purpose of replicas is to reduce the contention that would occur if all computations took place on a single server.
- Maintain multiple copies of data: Keeping copies of data (possibly one a subset of the other) on storage with different access speeds.
- Bound queue sizes: Control the maximum number of queued arrivals and consequently the resources used to process the arrivals.
- Schedule resources: When there is contention for a resource, the resource must be scheduled.
3. Summary

Security
Security is a measure of the system’s ability to protect data and information from unauthorized access while still providing access to people and systems that are authorized.
1. General Scenario
Source of Stimulus: The source of the attack may be either a human or another system.
Stimulus: The stimulus is an attack.
Artifact: The target of the attack can be either the services of the system, the data within it, or the data produced or consumed by the system.
Environment: The attack can come when the system is either online or offline, either connected to or disconnected from a network, either behind a firewall or open to a network, fully operational, partially operational or not operational.
Response: The system should ensure that transactions are carried out in a fashion such that data or services are protected from unauthorized access.
Response Measure: Measures of a system's response include how much of a system is compromised when a particular component or data value is compromised, how much time passed before an attack was detected, how many attacks were resisted, how long it took to recover from a successful attack, and how much data was vulnerable to a particular attack.
| Portion of | Possible Values |
| Source | Human or another system which may have been previously identified (either correctly or incorrectly) or may be currently unknown. A human attacker may be from outside the organization or from inside the organization. |
| Stimulus | The unauthorized attempt is made to display data, change or delete data, access system services, change the system’s behavior, or reduce availability. |
| Artifact | System services; data within the system; a component or resources of the system; data produced or consumed by the system |
| Environment | The system is either online or offline, connected to or disconnected from a network, behind a firewall or open to a network, fully operational, partially operational, or not operational |
| Response | Transactions are carried out in a fashion such that ·data or services are protected from unauthorized access; ·data or services are not being manipulated without authorization; ·parties to a transaction are identified with assurance; ·the parties to the transaction cannot repudiate their involvements; ·the data, resources, and system services will be available for legitimate use. The system tracks activities within it by ·recording access or modification, ·recording attempts to access data, resources or services, ·notifying appropriate entities (people or systems) when an apparent attack is occurring. |
| Response | One or more of the following ·how much of a system is compromised when a particular component or data value is compromised, ·how much time passed before an attack was detected, ·how many attacks were resisted, ·how long does it take to recover from a successful attack, ·how much data is vulnerable to a particular attack |
2. Tactics for Security
2.1 Detect Attacks
Categories:
- Detect intrusion: Compare network traffic or service request patterns within a system to a set of signatures or known patterns of malicious behavior stored in a database.
- Detect service denial: Comparison of the pattern or signature of network traffic coming into a system to historic profiles of known Denial of Service (DoS) attacks.
- Verify message integrity(完整性): Use techniques such as checksums or hash values to verify the integrity of messages, resource files, deployment files, and configuration files.
- Detect message delay: Checking the time that it takes to deliver a message, it is possible to detect suspicious timing behavior.
2.2 Resist Attacks
Categories:
- Identify actors: Identify the source of any external input to the system.
- Authenticate actors: Ensure that an actor (user or a remote computer) is actually who or what it purports to be.
- Authorize actors: Ensure that an authenticated actor has the rights to access and modify either data or services.
- Limit access: Ensuring that an authenticated actor has the rights to access and modify either data or services.
- Limit exposure: Ensuring that an authenticated actor has the rights to access and modify either data or services.
- Encrypt(加密) data: Apply some form of encryption to data and to communication.
- Separate entities: Can be done through physical separation on different servers attached to different networks, the use of virtual machines, or an “air gap”.
- Change default settings: Force the user to change settings assigned by default.
2.3 React to Attacks
Categories:
- Revoke access: Limit access to sensitive resources, even for normally legitimate users and uses, if an attack is suspected.
- Lock computer: Limit access to a resource if there are repeated failed attempts to access it.
- Inform actors: Notify operators, other personnel, or cooperating systems when an attack is suspected or detected.
2.4 Recover From Attacks
Categories:
- Audit: Keep a record of user and system actions and their effects, to help trace the actions of, and to identify, an attacker.
3. Summary

Testability
Software testability refers to the ease with which software can be made to demonstrate its faults through (typically execution-based) testing.
Specifically, testability refers to the probability, assuming that the software has at least one fault, that it will fail on its next test execution.
If a fault is present in a system, then we want it to fail during testing as quickly as possible.
1. General Scenario
Source of Stimulus: The source could be a human or an automated tester.
Stimulus: A set of tests executed.
Artifact: A unit of code, a subsystem, or the whole system.
Environment: The test can happen at development time, at compile time, at deployment time, or while the system is running.
Response: The system performs the desired test.
Response Measure: Response measures are aimed at representing how easily a system under test gives up its fault.
| Portion of | Possible Values |
| Source | Unit testers, integration testers, system testers, acceptance testers, end users, either running tests manually or using automated testing tools |
| Stimulus | A set of tests are executed due to the completion of a coding increment such as a class, layer or service; the completed integration of a subsystem; the complete implementation of the system; or the delivery of the system to the customer. |
| Environment | Design time, development time, compile time, integration time, deployment time, runtime |
| Artifacts | The portion of the system being tested |
| Response | One or more of the following: execute test suite and capture results; capture activity that resulted in the fault; control and monitor the state of the system |
| Response | One or more of the following: effort to find a fault or class of faults, effort to achieve a given percentage of state space coverage; probability of fault being revealed by the next test; time to perform tests; effort to detect faults; length of longest dependency chain in test; length of time to prepare test environment; reduction in risk exposure (size(loss) * prob(loss)) |
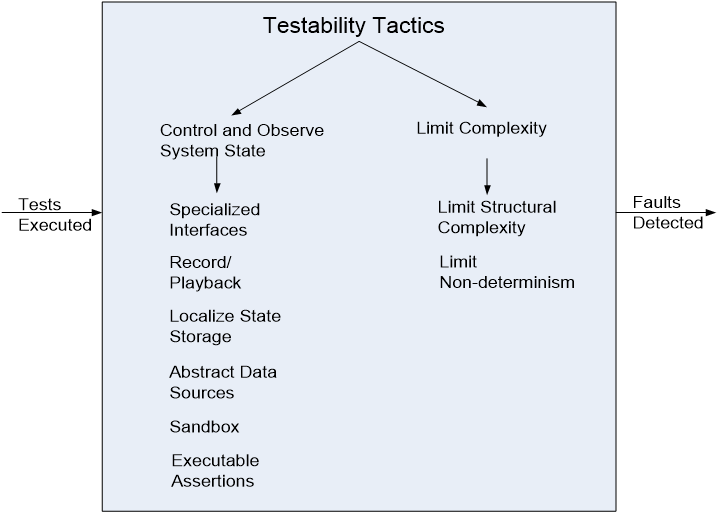
2. Tactics for Testability
2.1 Control and Observe System State
Categories:
- Specialized interfaces: To control or capture variable values for a component either through a test harness or through normal execution.
- Record/playback: Capturing information crossing an interface and using it as input for further testing.
- Localize state storage: To start a system, subsystem, or module in an arbitrary state for a test, it is most convenient if that state is stored in a single place.
- Abstract data sources: Abstracting the interfaces lets you substitute test data more easily.
- Sandbox: Abstracting the interfaces lets you substitute test data more easily.
- Executable assertions: Assertions are (usually) hand-coded and placed at desired locations to indicate when and where a program is in a faulty state.
2.2 Limit Complexity
Categories:
- Limit structure complexity: Avoiding or resolving cyclic dependencies between components, isolating and encapsulating dependencies on the external environment, and reducing dependencies between components in general.
- Limit non-Determinism: Finding all the sources of non-determinism, such as unconstrained parallelism, and weeding them out as far as possible.
3. Summary
Usability
Usability is concerned with how easy it is for the user to accomplish the desired task and the kind of user support the system provides.
Over the years, a focus on usability has shown itself to be one of the cheapest and easiest ways to improve a system’s quality (or, more precisely, the user’s perception of quality).
1. General Scenario
Source of Stimulus: The end users.
Stimulus: The stimulus is that the end user wishes to use a system efficiently, learn to use the system, minimize the impact of errors, adapt the system, or configure the system.
Environment: The user actions with which usability is concerned always occur at runtime or at system configuration time.
Artifact: The artifact is the system or the specific portion of the system with which the user is interacting.
Response: The system should either provide the user with the features needed or anticipate the user's need.
Response Measure: The response is measured by task time, number of errors, number of tasks accomplished, user satisfaction, the gain of user knowledge, the ratio of successful operations to total operations, etc.
| Portion of | Possible Values |
| Source | End user, possibly in a specialized role |
| Stimulus | End user tries to use a system efficiently, learn to use the system, minimize the impact of errors, adapt the system, or configure the system |
| Environment | Runtime or configuration time |
| Artifacts | System or the specific portion of the system with which the user is interacting. |
| Response | The system should either provide the user with the features needed or anticipate the user’s needs. |
| Response Measure | One or more of the following: task time, number of errors, number of tasks accomplished, user satisfaction, gain of user knowledge, ratio of successful operations to total operations, or amount of time or data lost when an error occurs. |
2. Tactics for Usability
2.1 Support User Initiative
Categories:
- Cancel: The system must listen for the cancel request; the command being canceled must be terminated; resources used must be freed, and collaborating components must be informed.
- Pause/resume: Temporarily free resources so that they may be re-allocated to other tasks.
- Undo: Maintain a sufficient amount of information about system state so that an earlier state may be restored, at the user’s request.
- Appregate: Ability to aggregate lower-level objects into a group, so that a user operation may be applied to the group, freeing the user from the drudgery.
2.2 Support System Initiative
Categories:
- Maintain task model: Determines context so the system can have some idea of what the user is attempting and provide assistance.
- Maintain user model: Explicitly represents the user's knowledge of the system, the user's behavior in terms of expected response time, etc.
- Maintain system model: System maintains an explicit model of itself. This is used to determine expected system behavior so that appropriate feedback can be given to the user.
3. Summary

Other Important Quality Attributes
















 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









