






 文章介绍了确定性最优控制的背景和历史,包括从最速降线问题到现代控制理论的发展。确定性最优控制是在已知系统模型的情况下,寻找使成本函数最小化的控制策略。极小值原理是解决此类问题的一阶必要条件,提供了状态和控制变量的微分方程。文章还讨论了间接法(shootingmethod)作为求解最优控制的一种方法,但指出这种方法在现代计算中已较少使用,因其收敛性和数值稳定性不足。
文章介绍了确定性最优控制的背景和历史,包括从最速降线问题到现代控制理论的发展。确定性最优控制是在已知系统模型的情况下,寻找使成本函数最小化的控制策略。极小值原理是解决此类问题的一阶必要条件,提供了状态和控制变量的微分方程。文章还讨论了间接法(shootingmethod)作为求解最优控制的一种方法,但指出这种方法在现代计算中已较少使用,因其收敛性和数值稳定性不足。
Lecture 6 确定性最优控制(Deterministic Optimal Control)
目录
- 控制简史
- 确定性最优控制(Deterministic Optimal Control)
- 连续时间
- 离散时间
- 极小值原理(Pontryagin’s Minimum Principle)
控制简史
1696年,数学家约翰-伯努利提出了著名最速降线问题,要设计一个怎样的斜坡才能使小球最快的掉下来。
在众多解法中,牛顿使用了变分法,即优化的变量本身是一个函数(坡的曲线表达)。变分法的想法是经典最优控制问题的解法,也在许多其他领域有应用。
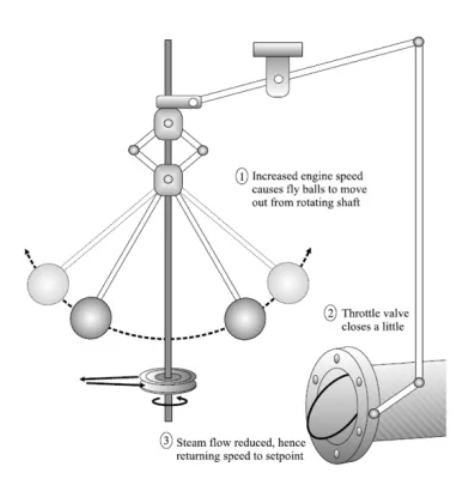
1769年,瓦特发明了飞轮调速器,采用了反馈控制的思想,当转轴转速增加时,则在机械装置的作用下,自动调小蒸汽输入,开启了反馈控制系统的研究序幕。
从二十世纪初到二十世纪六十年代是经典控制理论的年代,许多著名的想法,如拉普拉斯变换、奈奎斯特稳定性判据都在那个年代被提出。
有个小小的彩蛋,教授上课说,卡尔曼滤波的作者的原文被拒了很多次,投不出去,后面是NASA中某位大佬发现然后并期望用这个来做阿波罗登月计划估计航天器的状态,后面经过改良后用的扩展卡尔曼滤波EKF。
二十世纪六十年代到现在,随着计算机的发展,现代控制理论逐渐走向历史舞台,状态空间的概念被广泛应用。前苏联科学家Pontryagin提出了著名的极小值原理,李雅普诺夫提出了著名的李雅普诺夫稳定性判据。
1950年到现在,出现自适应控制(adaptive control)和强化学习的概念。因为对于一个复杂的系统,很有可能系统模型参数是时变的,因此,这是一种在线做梯度下降(上升)来在线更新系统参数的思想。
1980年代,鲁棒控制开始被研究,在那之前人们自然想着,像LQR这种最优控制器是自然稳定的,但是有人证明了,在LQR参数矩阵中施加一些很小的噪声,也会使整个控制系统发散,因此带来了许多相关研究。
1970年代,模型预测控制开始被研究,最开始由于算力的受限,主要是被用于如化工行业,这类系统的时间常数大,对实时性要求不高,因此我可以花几分钟的时间来算出一个可行解。
二十世纪七八十年达,机械臂开始兴起,八十年代,有了足式机器人如著名本田机器人ASIMO的前身E0,只有下半身的行走,在当年,人们是把机械臂相关的控制算法换到足式机器人中。而近代,许多足式机器人如Atals和mini cheetah都做了有关刚体动力学的针对性分析。
最后,教授总结,当前研究的困难点有
- 如何找到通用的处理接触的理论
- 如何将model-base控制和model-free的强化学习结合
- 如何在强化学习中加入先验知识让RL更加数据高效
- 如何保证不确定非线性系统的控制安全裕度
- 在一个非协作的环境中,如何处理其他adversial 课题

确定性最优控制
前面Lecture 1-5我们一直在打基础,学习了如何离散化模型,如何做一些优化,从这一节开始,我们正式进入最优控制的学习。
确定性最优控制是指系统的模型是确定的,在当前状态 x x x给一个特定的 u u u,根据系统方程我就一定可以知道下一步状态会怎么转移。这于随机最优控制或者RL那些不同,因为后者往往是一种概率时间,状态转义也是用一个概率函数表示的。
min
x
(
t
)
,
u
(
t
)
=
J
(
x
(
t
)
,
u
(
t
)
)
=
∫
t
0
t
f
l
(
x
(
t
)
,
u
(
t
)
)
d
t
+
l
F
(
x
(
t
f
)
)
∋
x
˙
(
t
)
=
f
(
x
(
t
)
,
u
(
t
)
)
∋
Any other constraints
(1)
\begin{align} \min_{x(t), u(t)} &= J(x(t), u(t)) = \int_{t_0}^{t_f} l(x(t), u(t)) dt + l_{F} (x(t_f)) \\ \ni \ &\dot{x}(t) = f(x(t), u(t)) \\ \ni \ &\textrm{Any other constraints} \end{align}\tag{1}
x(t),u(t)min∋ ∋ =J(x(t),u(t))=∫t0tfl(x(t),u(t))dt+lF(x(tf))x˙(t)=f(x(t),u(t))Any other constraints(1)
其中,我们最小化的目标
J
J
J是关于函数
x
(
t
)
u
(
t
)
x(t) \ u(t)
x(t) u(t)的泛函,
l
(
x
(
t
)
,
u
(
t
)
)
l(x(t),u(t))
l(x(t),u(t))叫做state cost,而
l
F
(
x
t
f
)
l_F(x_{t_f})
lF(xtf)是terminal cost。
ps:课上有同学提问了一个很有意思的问题?为什么优化的变量是 x ( t ) 和 u ( t ) x(t)和u(t) x(t)和u(t),而不能把 x ( t ) x(t) x(t)通过状态方程消掉,最终只优化 u ( t ) u(t) u(t)呢?
确实可以这么做,这么做有个专门的名字,叫做shooting/indirect method,但是这样做有几个坏处:一,只用u(t)的话代表要对整条轨迹进行前向仿真forward rollout/simulation,这样做因为 A N A^N AN次方会导致优化问题的条件数变得很差,使优化问题变得病态,会出现类似于神经网络优化中的梯度消失或梯度爆炸问题。二,有些时候,无法找到一种稳定的初始控制率给我rollout,如,假如是一个人形机器人,找不到一个初始好的u(t),那么整个优化问题会变得很难。但是,假如我是x(t)和u(t)一起优化的方式,我可以通过动捕数据提前采好人类行走时候的x(t)给到优化器作为初始值,这样子即使我没有一个好的初始的u(t),我也能让整个优化问题至少一开始不在一个很奇怪的状态。这种方法就是目前常用的方法
- 通过解这个最优化解出来的轨迹是一个开环轨迹(因此,要么就解的特别快,总是用前面的开环轨迹执行,如MPC问题,要么就离线解,在线用一个很好的反馈控制器来跟踪)。与此相反,在随机最优控制问题中,由于问题的定义是充满噪声的,因此解随机最优控制问题必须要得到一个闭环的轨迹。
- (1)式指定的优化问题在大部分时候,是没有解析解的,但是少部分很特殊的情况有,如LQR问题。
离散情况
min x 1 : N , u 1 : N − 1 J ( x 1 : N , u 1 : N − 1 ) = ∑ k = 1 N − 1 l ( x k , u k ) + l F ( x N ) ∋ x n + 1 = f ( x n , u n ) ∋ u min ≤ u k ≤ u max Torque limits. ∋ c ( x k ) ≤ 0 ∀ k Obstacle / collision constraints. (2) \begin{align} \min_{x_{1:N}, u_{1:N-1}} \ & J(x_{1:N}, u_{1:N-1}) = \sum_{k=1}^{N-1} l(x_k, u_k) + l_F(x_N) \\ \ni \ & x_{n+1} = f(x_n,u_n) \\ \ni \ & u_{\min} \leq u_k \leq u_{\max} \ \ \textrm{Torque limits.} \\ \ni \ & c(x_k) \leq 0 \ \forall k \ \ \textrm{Obstacle / collision constraints.} \end{align}\tag{2} x1:N,u1:N−1min ∋ ∋ ∋ J(x1:N,u1:N−1)=k=1∑N−1l(xk,uk)+lF(xN)xn+1=f(xn,un)umin≤uk≤umax Torque limits.c(xk)≤0 ∀k Obstacle / collision constraints.(2)
- 这是一个有限维度的优化问题,而不像连续时间的情况,是一个无线维度的问题
- x k u k x_k \ u_k xk uk叫做结点(knot points)
- 可以通过数值积分把连续问题转成离散问题,然后再通过插值(interpolation),把离散问题的解转回到连续问题中。
极小值原理(Pontryagin’s Minimum Principle)
在离散情况下,极小值原理只是KKT条件的一种特殊表达形式,可以直接由带约束的优化问题的KKT条件推导出,因此,PMP也是确定性最优控制问题解的一阶必要条件。
教授原话:I am going to argue that this is not a big deal.
极小值原理也可以叫做极大值原理,取决于目标函数是最小化Cost还是最大化Reward。
min
x
1
:
N
,
u
1
:
N
−
1
J
(
x
1
:
N
,
u
1
:
N
−
1
)
=
∑
k
=
1
N
−
1
l
(
x
k
,
u
k
)
+
l
F
(
x
N
)
∋
x
n
+
1
=
f
(
x
n
,
u
n
)
(3)
\begin{align} \min_{x_{1:N}, u_{1:N-1}} \ & J(x_{1:N}, u_{1:N-1}) = \sum_{k=1}^{N-1} l(x_k, u_k) + l_F(x_N) \\ \ni \ & x_{n+1} = f(x_n,u_n) \end{align}\tag{3}
x1:N,u1:N−1min ∋ J(x1:N,u1:N−1)=k=1∑N−1l(xk,uk)+lF(xN)xn+1=f(xn,un)(3)
我们考虑问题具有输入限制(如力矩限制)。状态的约束(如避障)比较难处理。写出(3)的拉格朗日函数
L
=
∑
k
=
1
N
−
1
[
l
(
x
k
,
u
k
)
+
λ
k
+
1
(
f
(
x
k
,
u
k
)
−
x
k
+
1
)
]
+
l
F
(
x
N
)
(4)
\begin{align} L = \sum_{k=1}^{N-1} \Big[ l(x_k,u_k) + \lambda_{k+1} (f(x_k,u_k)-x_{k+1}) \Big] + l_F(x_N) \\ \end{align}\tag{4}
L=k=1∑N−1[l(xk,uk)+λk+1(f(xk,uk)−xk+1)]+lF(xN)(4)
因为一些历史上的原因,我们把(3)这个式子重新写成哈密尔顿函数(Hamiltonian)形式
H
(
x
,
u
,
λ
)
=
l
(
x
,
u
)
+
λ
T
f
(
x
,
u
)
(5)
\begin{align} H(x, u, \lambda) = l(x,u) + \lambda^T f(x,u) \end{align}\tag{5}
H(x,u,λ)=l(x,u)+λTf(x,u)(5)
将(5)代入(4),把求和符号里面的第一项拿出来,凑成这种
H
(
x
k
,
u
k
,
λ
k
+
1
)
λ
k
H(x_k,u_k,\lambda_{k+1}) \ \lambda_{k}
H(xk,uk,λk+1) λk的形式。
L
=
H
(
x
1
,
u
1
,
λ
2
)
+
[
∑
k
=
2
N
−
1
H
(
x
k
,
u
k
,
λ
k
+
1
)
−
λ
k
T
x
k
]
+
l
F
(
x
N
)
−
λ
N
T
x
N
(6)
\begin{align} L = H(x_1, u_1, \lambda_2) + \Big[ \sum_{k=2}^{N-1} H(x_k,u_k,\lambda_{k+1}) - \lambda_k^T x_k \Big] + l_F(x_N) - \lambda_N^T x_N \end{align}\tag{6}
L=H(x1,u1,λ2)+[k=2∑N−1H(xk,uk,λk+1)−λkTxk]+lF(xN)−λNTxN(6)
式子(6)是标准的带等式约束最优化问题,我们将其对所有变量求梯度(
x
1
x_1
x1不是变量,是给定),另梯度为0,得到极值的必要条件。
∂
L
∂
λ
k
+
1
=
∂
H
(
x
k
,
u
k
,
λ
k
+
1
)
∂
λ
k
+
1
−
x
k
+
1
=
f
(
x
k
,
u
k
)
−
x
k
+
1
=
0
∂
L
∂
x
k
=
∂
H
∂
x
k
−
λ
k
T
=
∂
l
∂
x
k
+
λ
k
+
1
T
∂
f
∂
x
k
−
λ
k
T
=
0
∂
L
∂
x
N
=
∂
l
F
∂
x
N
−
λ
N
T
=
0
(7)
\begin{align} \frac{\partial L}{\partial \lambda_{k+1}} &= \frac{\partial H(x_k,u_k,\lambda_{k+1})}{\partial \lambda_{k+1}} - x_{k+1} = f(x_k,u_k) - x_{k+1} = 0 \\ \frac{\partial L}{\partial x_k} &= \frac{\partial H}{\partial x_k} - \lambda_{k}^T = \frac{\partial l}{\partial x_k} + \lambda_{k+1}^T \frac{\partial f}{\partial x_k} - \lambda_k^T = 0 \\ \frac{\partial L}{\partial x_N} &= \frac{\partial l_F}{\partial x_N} - \lambda_N^T = 0 \end{align}\tag{7}
∂λk+1∂L∂xk∂L∂xN∂L=∂λk+1∂H(xk,uk,λk+1)−xk+1=f(xk,uk)−xk+1=0=∂xk∂H−λkT=∂xk∂l+λk+1T∂xk∂f−λkT=0=∂xN∂lF−λNT=0(7)
对于u,我们显式地把方程写出来(所有变量都可以写成这种
a
r
g
m
i
n
argmin
argmin的形式,但是其他变量因为是无约束的,从这个
a
r
g
m
i
n
argmin
argmin可以推出极值必要条件)。假如u本身是无受限的,那么从
a
r
g
m
i
n
argmin
argmin也能推出必要条件是
L
L
L对u的梯度为0。
u
k
=
arg
min
u
~
L
=
arg
min
u
~
H
(
x
k
,
u
~
,
λ
k
+
1
)
∋
u
~
∈
U
(8)
\begin{align} u_k &= \arg\min_{\tilde{u}} L=\arg\min_{\tilde{u}} H(x_k, \tilde{u}, \lambda_{k+1}) \\ \ni \ & \tilde{u} \in \mathcal{U} \end{align}\tag{8}
uk∋ =argu~minL=argu~minH(xk,u~,λk+1)u~∈U(8)
式(5)中, u u u也是变量,但是因为在我们问题定义中, u u u是带有不等式约束,因此我们不显式对 u u u求梯度。ps:这里(7)的写法是在我们的约定中求雅克比而不是梯度,是个行向量。
对(7)式变换,写成状态方程的形式,有
x
k
+
1
=
∇
λ
H
(
x
k
,
u
k
,
λ
k
+
1
)
=
f
(
x
k
,
u
k
)
λ
k
=
∇
x
H
(
x
k
,
u
k
,
λ
k
+
1
)
=
∇
x
l
(
x
k
,
u
k
)
+
(
∂
f
∂
x
)
T
λ
k
+
1
u
k
=
arg
min
u
~
H
(
x
k
,
u
~
,
λ
k
+
1
)
∋
u
~
∈
U
λ
N
=
∂
l
F
∂
X
N
(9)
\begin{align} x_{k+1} &= \nabla_{\lambda} H(x_k, u_k, \lambda_{k+1}) = f(x_k, u_k) \\ \lambda_k &= \nabla_{x} H(x_k,u_k,\lambda_{k+1}) = \nabla_x l(x_k,u_k) + (\frac{\partial f}{\partial x})^T \lambda_{k+1} \\ u_k &= \arg\min_{\tilde{u}} H(x_k, \tilde{u}, \lambda_{k+1}) \\ &\ \ \ni \ \tilde{u} \in \mathcal{U} \\ \lambda_{N} &= \frac{\partial l_F}{\partial X_{N}} \end{align}\tag{9}
xk+1λkukλN=∇λH(xk,uk,λk+1)=f(xk,uk)=∇xH(xk,uk,λk+1)=∇xl(xk,uk)+(∂x∂f)Tλk+1=argu~minH(xk,u~,λk+1) ∋ u~∈U=∂XN∂lF(9)
连续形式为
x
˙
=
∇
λ
H
(
x
,
u
,
λ
)
=
f
c
o
n
t
i
n
u
o
u
s
(
x
,
u
)
−
λ
˙
=
∇
x
H
(
x
,
u
,
λ
)
=
∇
x
l
(
x
,
u
)
+
(
∂
f
c
o
n
t
i
n
u
o
u
s
∂
x
)
T
λ
u
=
arg
min
u
~
H
(
x
,
u
~
,
λ
)
∋
u
~
∈
U
λ
N
=
∂
l
F
∂
X
N
(10)
\begin{align} \dot{x} &= \nabla_{\lambda} H(x, u, \lambda) = f_{\rm continuous}(x, u) \\ -\dot{\lambda} &= \nabla_{x} H(x,u,\lambda) = \nabla_x l(x,u) + (\frac{\partial f_{\rm continuous}}{\partial x})^T \lambda \\ u &= \arg\min_{\tilde{u}} H(x, \tilde{u}, \lambda) \\ &\ \ \ni \ \tilde{u} \in \mathcal{U} \\ \lambda_{N} &= \frac{\partial l_F}{\partial X_{N}} \end{align}\tag{10}
x˙−λ˙uλN=∇λH(x,u,λ)=fcontinuous(x,u)=∇xH(x,u,λ)=∇xl(x,u)+(∂x∂fcontinuous)Tλ=argu~minH(x,u~,λ) ∋ u~∈U=∂XN∂lF(10)
(10)中的第二个式子-\lambda是因为在离散情况也是从\lambda_{k+1}到\lambda_k的推导
一般的教程可能写到这里也停了,可能大家还会很迷迷糊糊,(9)和(10)这一堆式子有什么用呢,因为,对于很多问题,这几个式子都是没有解析解的(LQR有),那么该怎么使用呢。
根据极小值原理(9)或(10)式,我们可以写出最优控制问题的第一种解法,间接法(indirect)或者叫打靶法(shooting)。在一个问题中,我们的初始状态 x 1 x_1 x1是已知的,而根据(9)中最后一个式子, λ N \lambda_N λN也是知道的。因此,有以下迭代流程
- 得到 x 1 x_1 x1和 λ N \lambda_N λN,根据经验,设定一条初始的 u u u的轨迹
- 使用(9-1)正向rollout系统方程,获得 x 1 x 2 . . . x N x_1 \ x_2 ... x_N x1 x2...xN
- 因为所有的 x u x \ u x u都已知了,可以使用(9-2)反向迭代 λ \lambda λ,求出所有 λ \lambda λ
- 所有的 x u λ x \ u \ \lambda x u λ都已知,则哈密尔顿函数 H H H已知,根据(9-3),求解带约束最优化问题(如用牛顿法),获得一条新的 Δ u \Delta u Δu轨迹,利用armijo法则进行线搜索或者最优的 u u u。重新回到第二步迭代至收敛(一般收敛的原则是 u u u的变化小于一定的阈值)
无论系统本身是线性的还是非线性的(线性的系统局部线性化就等于本身),我们一直分析的是类似 Δ x ˙ = A Δ x + B Δ u \Delta \dot{x}=A\Delta x+B\Delta u Δx˙=AΔx+BΔu这种系统,迭代法寻找的总是 Δ u \Delta u Δu,因为一切的一切比如 λ x \lambda \ x λ x都是在上一个 u u u的基础上获得的,我们经过rollout后得到的值。
从上面这几步可以看出,基于shooting方法迭代求解该方程,需要有一次正向传播过程,再有一次反向传播过程,这就很像训练神经网络的梯度下降更新权重的过程。这个过程实际是比较慢的,下节会举例对比说明,所以在现代,基本都不会根据这个流程做了,这种方法无论是收敛性、数值优劣和鲁棒性都不够强。
小结
- 这种方法叫做indirect method或者shooting method
- 在连续时间中, λ ( t ) \lambda(t) λ(t)叫做协态轨迹。后面会介绍, λ \lambda λ 实际是cost-to-go的梯度
- 这种梯度下降迭代法过时了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









