






Lecture 12 直接配点法(Direct Collocation)
目录
- 轨迹优化的直接法(Direct Trajectory Optimization)
- 序列二次规划(Sequential Quadratic Programming)
- 直接配点法(Direct Collocation)
- DDP与DIRCOL的比较
直接法
前文所述的DDP/iLQR,基于PMP的shooting法,DP法,都称为轨迹优化的间接法(indirect methods),本节分析采用直接法的轨迹优化,即直接把轨迹优化问题转化成大的非线性优化问题,然后利用成熟的商用/开源的非线性求解器求解。直接法有时也叫作direct transtription。
针对一个标准的非线性优化问题,
min
x
f
(
x
)
s
.
t
.
c
(
x
)
=
0
d
(
x
)
≤
0
(1)
\begin{align} \min_x & f(x) \\ s.t. & c(x) = 0 \\ & d(x) \leq 0 \end{align}\tag{1}
xmins.t.f(x)c(x)=0d(x)≤0(1)
比较常用的非线性求解器有(Gurobi是做凸优化的)如IPOPT(开源) SNOPT(商用) KNITRO(商用)。一般来说,比较常用的非线性优化策略是基于序列二次规划SQP。
SQP
策略:使用二阶泰勒展开来近似目标函数
f
(
x
)
f(x)
f(x),使用一阶泰勒展开线性化约束
c
(
x
)
d
(
x
)
c(x) \ d(x)
c(x) d(x),进而把问题化成一个局部的QP问题。
min
Δ
x
1
2
Δ
x
T
H
Δ
x
+
g
T
Δ
x
∋
c
(
x
)
+
C
Δ
x
=
0
d
(
x
)
+
D
Δ
x
≤
0
where
H
=
∂
L
∂
x
,
g
=
∂
L
∂
x
,
C
=
∂
c
∂
x
,
D
=
∂
d
∂
x
b
L
(
x
,
λ
,
μ
)
=
f
(
x
)
+
λ
T
c
(
x
)
+
μ
T
d
(
x
)
(2)
\begin{align} \min_{\Delta x} & \frac{1}{2} \Delta x^T H \Delta x + g^T \Delta x \\ \ni & c(x)+ C \Delta x = 0 \\ & d(x) + D \Delta x \leq 0 \\ \text{where} H & = \frac{\partial L}{\partial x}, g = \frac{\partial L}{\partial x}, C = \frac{\partial c}{\partial x}, D = \frac{\partial d}{\partial xb} \\ L(x, \lambda, \mu) & = f(x) + \lambda^T c(x) + \mu^T d(x) \end{align}\tag{2}
Δxmin∋whereHL(x,λ,μ)21ΔxTHΔx+gTΔxc(x)+CΔx=0d(x)+DΔx≤0=∂x∂L,g=∂x∂L,C=∂x∂c,D=∂xb∂d=f(x)+λTc(x)+μTd(x)(2)
通过解QP问题来获得搜索方向
Δ
z
=
[
Δ
x
Δ
λ
Δ
μ
]
(3)
\begin{align} \Delta z = \begin{bmatrix} \Delta x \\ \Delta \lambda \\ \Delta \mu \end{bmatrix} \end{align}\tag{3}
Δz=
ΔxΔλΔμ
(3)
而后利用指标函数(Merit Function)进行线搜索
带约束的线搜索详见Lecture 5。如采用增广拉格朗日法解QP,则Merit function可以直接选为拉格朗日函数 L L L.
当问题只有等式约束而没有不等式约束时,此时就用普通的等式约束牛顿法迭代即可,
[
H
C
T
C
0
]
[
Δ
x
Δ
λ
]
=
[
−
∂
L
∂
x
−
c
(
x
)
]
(4)
\begin{align} \begin{bmatrix} H & C^T \\ C & 0 \end{bmatrix} \begin{bmatrix} \Delta x \\ \Delta \lambda \end{bmatrix} = \begin{bmatrix} -\frac{\partial L}{\partial x} \\ -c(x) \end{bmatrix} \end{align}\tag{4}
[HCCT0][ΔxΔλ]=[−∂x∂L−c(x)](4)
所以,SQP本质上可以看成通过牛顿法迭代求解最优化问题的推广,可以处理不等式约束。
可以看出,SQP本身的想法较为简单,但是要达到一个好的效果往往需要加多一些trick,
- 通过历史求解的结果或者启发函数的结果进行SQP的warm start,保证起始位置离局部最优位置的距离偏差别太大,同时,因为在优化的大部分时刻,可能active set都是不变的,因此也可以对active set做一个warm start。
- 由于SQP的子问题维度也比较大,因此,要取得好的效果,必须合理地利用(4)KKT系统Hessian的稀疏性来求解问题。SNOPT做的就不错。
- ps:利用DDP/iLQR方法求解问题,求解的局部QP问题是维度小的(只有一步的状态和输入),而SQP这种直接法,求解的QP问题维度是比较大的
- 假如本身(1)中的约束就是凸的,则可以把SQP推广成SCP(sequential convex programming),因为QP问题只能处理线性约束而不能通用的处理凸的约束,换成SCP之后就可以在不作约束简化的情况下进行迭代,在某些极端情况下(如我必须取得一个很好的约束满足效果)会是一个不错的选择。
- SCP仍在研究热点中
课上有个同学问了个问题,能不能通过加松弛变量的形式把不等式约束换成等式约束呢?因为我之前大四的时候学单纯形表(解线性回归问题)的时候也是那么做的。答案是不能。
首先,LP问题比QP问题简单的多,LP能不代表QP能。引入松弛变量后会有一个松弛变量大于等于0的约束,LP能很好地处理这个问题,因为是个标准型。而对于QP来说,本来就是为了去掉不等式约束,如今又引进来一个新的。
对于简单能解析的问题,可以通过这种方式来消掉不等式约束,最后解出结果再一一判断是否满足约束就好。
假如是通过引入一种松弛变量的平方的形式来处理不等式约束的话,教授说,实践中这种方法效果不好。
直接配点法(Direct Collocation)
在本课的大部分时刻,我们处理系统微分约束的方法都是,利用显式的RK4积分将其表示出来,即
x
˙
=
f
(
x
,
u
)
→
x
k
+
1
=
f
(
x
k
,
u
k
)
(5)
\begin{align} \dot x = f(x,u) \to x_{k+1} = f(x_k, u_k) \end{align}\tag{5}
x˙=f(x,u)→xk+1=f(xk,uk)(5)
这种策略在需要Rollout的方法来说是必须的,如DDP或者Riccati迭代中,我需要从初始状态
x
1
x_1
x1前向不断执行最优控制率才能得到优化后的整条轨迹,换句话说,系统是因果的,在迭代过程中,前一时刻的
x
k
x_k
xk并不知道
x
k
+
1
x_{k+1}
xk+1是怎样的。
但是,对于直接法的轨迹优化来说,没有rollout的这个过程,即整个系统不是一个马尔可夫链式的,我们是把所有变量都“揉”在一个大矩阵中进行的迭代优化,因此,任何时刻 x k x k + 1 x_k x_{k+1} xkxk+1都是同时存在的。此时,通过这种显式数值积分的方式来迭代,不再具有必要性。
回忆Lecture 2中我们进行后向欧拉积分(隐式积分),我们得出结论:后向积分的方式比前向积分的方式更加稳定,因为它更倾向于低估系统的能量。因此,在直接法的轨迹优化中,我们换一种更加稳定的方式来表达系统方程约束(5)。
我们期望找到一条系统约束式
c
k
(
x
k
,
u
k
,
x
k
+
1
,
u
k
+
1
)
=
0
(6)
\begin{align} c_k(x_k, u_k, x_{k+1}, u_{k+1}) = 0 \end{align}\tag{6}
ck(xk,uk,xk+1,uk+1)=0(6)
接下来介绍Direct Collocation方法,传统上,一般使用三次多项式样条来近似状态轨迹,使用一阶保持器来近似输入轨迹。
为什么是3阶呢?因为3阶多项式有4个未知参数,恰好可以被指定轨迹的 x k x k + 1 x k ˙ x k + 1 ˙ x_k \ x_{k+1} \ \dot{x_k} \ \dot{x_{k+1}} xk xk+1 xk˙ xk+1˙唯一确定。
当然也可以取更高的阶次,然后用更多的状态点来确定轨迹,但是这不一定意味着更好的效果,因为现实环境往往存在许多非光滑的分量,因此最优的状态轨迹不一定是更高次的。但是在航天领域,可以有很高阶的很光滑的多项式样条来近似。
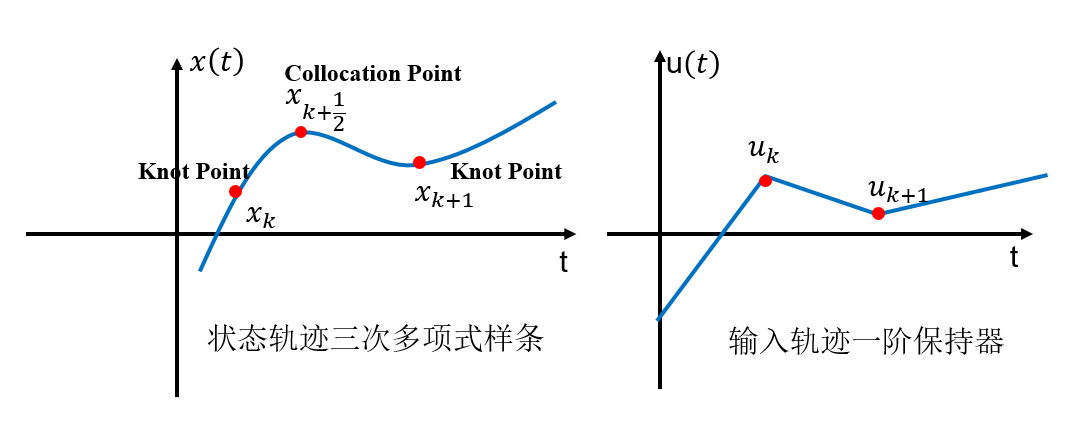
在三阶多项式的前提下,轨迹可以完全由前后两点的一阶导数来确定(注意这里优化变量其实只有
x
k
u
k
x_k\ u_k
xk uk,速度
x
k
˙
\dot{x_k}
xk˙仅是作为中间变量推导,在优化过程中并不是优化变量)
x
(
t
)
=
c
0
+
c
1
t
+
c
2
t
2
+
c
3
t
3
x
˙
(
t
)
=
c
1
+
2
c
2
t
+
3
c
3
t
2
[
1
0
0
0
0
1
0
0
1
h
h
2
h
3
0
1
2
h
3
h
2
]
[
c
0
c
1
c
2
c
3
]
=
[
x
k
x
˙
k
x
k
+
1
x
˙
k
+
1
]
[
1
0
0
0
0
1
0
0
−
3
/
h
2
−
2
/
h
3
/
h
2
−
1
/
h
2
/
h
3
1
/
h
2
−
2
/
h
3
1
/
h
2
]
[
x
k
x
˙
k
x
k
+
1
x
˙
k
+
1
]
=
[
c
0
c
1
c
2
c
3
]
(7)
\begin{align} &x(t) = c_0 + c_1t + c_2 t^2 + c_3 t^3 \\ &\dot x(t) = c_1 + 2 c_2 t + 3 c_3 t^2 \\ &\begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 1 & h & h^2 & h^3 \\ 0 & 1 & 2h & 3h^2 \\ \end{bmatrix} \begin{bmatrix} c_0 \\ c_1 \\ c_2 \\ c_3 \end{bmatrix} = \begin{bmatrix} x_k \\ \dot x_k \\ x_{k+1} \\ \dot x_{k+1} \end{bmatrix} \\ &\begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ -3/h^2 & -2/h & 3/h^2 & -1/h \\ 2/h^3 & 1/h^2 & -2/h^3 & 1/h^2 \\ \end{bmatrix} \begin{bmatrix} x_k \\ \dot x_k \\ x_{k+1} \\ \dot x_{k+1} \end{bmatrix} = \begin{bmatrix} c_0 \\ c_1 \\ c_2 \\ c_3 \end{bmatrix} \end{align}\tag{7}
x(t)=c0+c1t+c2t2+c3t3x˙(t)=c1+2c2t+3c3t2
101001h100h22h00h33h2
c0c1c2c3
=
xkx˙kxk+1x˙k+1
10−3/h22/h301−2/h1/h2003/h2−2/h300−1/h1/h2
xkx˙kxk+1x˙k+1
=
c0c1c2c3
(7)
获得
x
(
t
)
x(t)
x(t)的表达式后,代入
t
=
1
2
h
t=\frac{1}{2}h
t=21h,得到中点处的状态表达式,
x
k
+
1
/
2
=
x
(
t
k
+
h
/
2
)
=
1
2
(
x
k
+
x
k
+
1
)
+
h
8
(
x
˙
k
−
x
˙
k
+
1
)
=
1
2
(
x
k
+
x
k
+
1
)
+
h
8
(
f
(
x
k
,
u
k
)
−
f
(
x
k
+
1
,
u
k
+
1
)
)
x
˙
k
+
1
/
2
=
x
˙
(
t
k
+
h
/
2
)
=
−
3
/
2
h
(
x
k
−
x
k
+
1
)
−
1
/
4
(
x
˙
k
+
x
˙
k
+
1
)
=
−
3
/
2
h
(
x
k
−
x
k
+
1
)
−
1
/
4
(
f
(
x
k
,
u
k
)
+
f
(
x
k
+
1
,
u
k
+
1
)
)
u
k
+
1
/
2
=
u
(
t
k
+
h
/
2
)
=
1
2
(
u
k
+
u
k
+
1
)
(8)
\begin{align} x_{k+1/2} &= x(t_k + h/2) = \frac{1}{2}(x_k + x_{k+1}) + \frac{h}{8}(\dot x_k - \dot x_{k+1}) = \frac{1}{2}(x_k + x_{k+1}) + \frac{h}{8}(f(x_k, u_k) - f(x_{k+1}, u_{k+1})) \\ \dot x_{k+1/2} &= \dot x(t_k + h/2) = -3/2h (x_k - x_{k+1}) - 1/4(\dot x_k + \dot x_{k+1}) = -3/2h(x_k - x_{k+1}) - 1/4(f(x_k, u_k) + f(x_{k+1}, u_{k+1})) \\ u_{k+1/2} &= u(t_k + h/2) = \frac{1}{2}(u_k + u_{k+1}) \end{align}\tag{8}
xk+1/2x˙k+1/2uk+1/2=x(tk+h/2)=21(xk+xk+1)+8h(x˙k−x˙k+1)=21(xk+xk+1)+8h(f(xk,uk)−f(xk+1,uk+1))=x˙(tk+h/2)=−3/2h(xk−xk+1)−1/4(x˙k+x˙k+1)=−3/2h(xk−xk+1)−1/4(f(xk,uk)+f(xk+1,uk+1))=u(tk+h/2)=21(uk+uk+1)(8)
然后,在中点处,施加系统方程约束
x
˙
k
+
1
/
2
=
f
(
x
k
+
1
/
2
,
u
k
+
1
/
2
)
\dot x_{k+1/2}=f(x_{k+1/2},u_{k+1/2})
x˙k+1/2=f(xk+1/2,uk+1/2),即可获得(4)中的前后状态与输入的约束,
c
i
(
x
k
,
u
k
,
x
k
+
1
,
u
k
+
1
)
=
f
(
x
k
+
1
/
2
,
u
k
+
1
/
2
)
−
(
−
3
/
2
h
(
x
k
−
x
k
+
1
)
−
1
/
4
(
f
(
x
k
,
u
k
)
+
f
(
x
k
+
1
,
u
k
+
1
)
)
=
0
(9)
\begin{align} c_i(x_k, u_k, x_{k+1}, u_{k+1}) = f(x_{k+1/2}, u_{k+1/2}) - (-3/2h(x_k - x_{k+1}) - 1/4(f(x_k, u_k) + f(x_{k+1}, u_{k+1})) = 0 \end{align}\tag{9}
ci(xk,uk,xk+1,uk+1)=f(xk+1/2,uk+1/2)−(−3/2h(xk−xk+1)−1/4(f(xk,uk)+f(xk+1,uk+1))=0(9)
这就是Direct Collocation的主要内容,要澄清的是,由始至终,优化问题的变量都是
x
k
u
k
x_k \ u_k
xk uk,而不包含导数或者是多项式的系数。
方程(9)类似显式的三阶龙格库塔法,而在三阶的龙格库塔法中,需要求解三次系统方程的值,在(9)中,虽然也有三次evalute f ( x , u ) f(x,u) f(x,u) 的过程,但是在前后两次的约束中的 f ( x k , u k ) f(x_k,u_k) f(xk,uk)与 f ( x k + 1 , u k + 1 ) f(x_{k+1},u_{k+1}) f(xk+1,uk+1)可以重用,因此只有两次求解系统方程的值的过程。在系统非常复杂是,这可以省50%的算力。(7)(8)(9)这种方式也叫做,“Hermite-Simpson” 积分。
y n + 1 = y n + h 6 [ k 1 + 4 k 2 + k 3 ] k 1 = f ( x n , y n ) , k 2 = f ( x n + h 2 , y n + h 2 k 1 ) , k 3 = f ( x n + h , y n − h k 1 + 2 h k 2 ) . (10) \begin{gathered} y_{n+1}=y_n+\frac{h}{6}\left[k_1+4 k_2+k_3\right] \\ k_1=f\left(x_n, y_n\right), \\ k_2=f\left(x_n+\frac{h}{2}, y_n+\frac{h}{2} k_1\right), \\ k_3=f\left(x_n+h, y_n-h k_1+2 h k_2\right) . \end{gathered}\tag{10} yn+1=yn+6h[k1+4k2+k3]k1=f(xn,yn),k2=f(xn+2h,yn+2hk1),k3=f(xn+h,yn−hk1+2hk2).(10)
案例分析
利用DIRCOL法解Lecture 10中的acrobot MPC问题,
J
=
∑
i
=
1
N
−
1
(
x
−
x
g
o
a
l
)
T
Q
(
x
−
x
g
o
a
l
)
+
u
T
R
u
+
(
x
N
−
x
g
o
a
l
)
T
Q
f
i
n
a
l
(
x
N
−
x
g
o
a
l
)
s
.
t
x
˙
=
f
(
x
,
u
)
\begin{aligned} &J= \sum_{i=1}^{N-1}(x-x_{goal})^TQ(x-x_{goal})+u^TRu+(x_N-x_{goal})^TQ_{final}(x_N-x_{goal})\\ &s.t \ \ \ \ \dot{x}=f(x,u) \end{aligned}
J=i=1∑N−1(x−xgoal)TQ(x−xgoal)+uTRu+(xN−xgoal)TQfinal(xN−xgoal)s.t x˙=f(x,u)
迭代运行时间如下:本问题中没有加不等式约束,因此只有等式约束,步长
N
=
51
N=51
N=51,状态4维,输入1维,有255变量。
起点 x 1 x_1 x1与终点 x N x_N xN状态约束加起来2*4=8个,中间共有50个系统方程约束(向量形式),转成标量形式有200个中间约束。
将系统的状态随机初始化,在不同的初始化条件下,系统收敛后的运行轨迹是不同的,说明对于一个非线性的轨迹优化问题,存在多个局部极小值点。并且,若已经有一条粗糙的初始状态轨迹(不完全满足动力学约束的),则优化能很好很快地收敛到同一个局部极小值点。
从实验结果动图可以看出,对比DDP方法,基于直接法出来的轨迹质量整体还是要差一些。
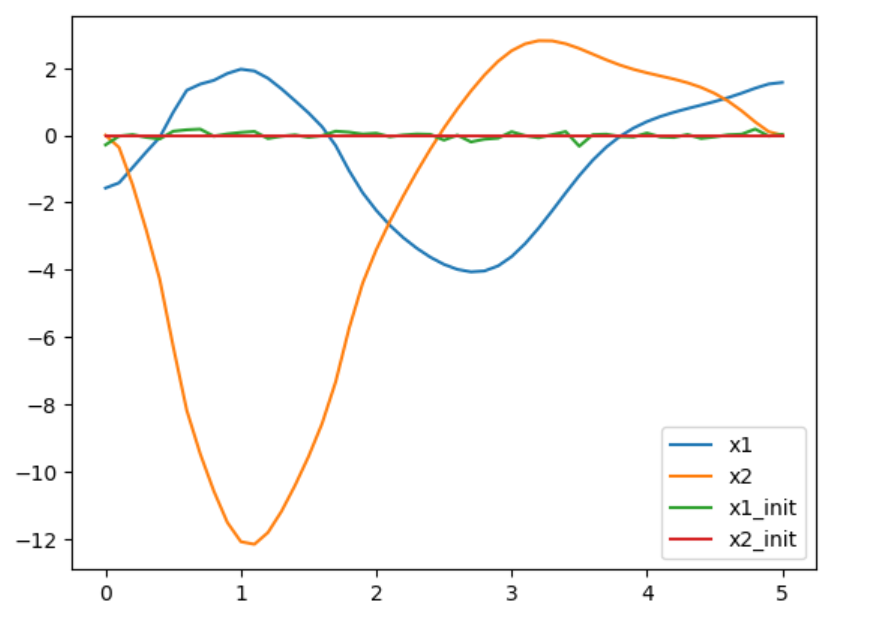
acrobot DIRCOL state with random init |
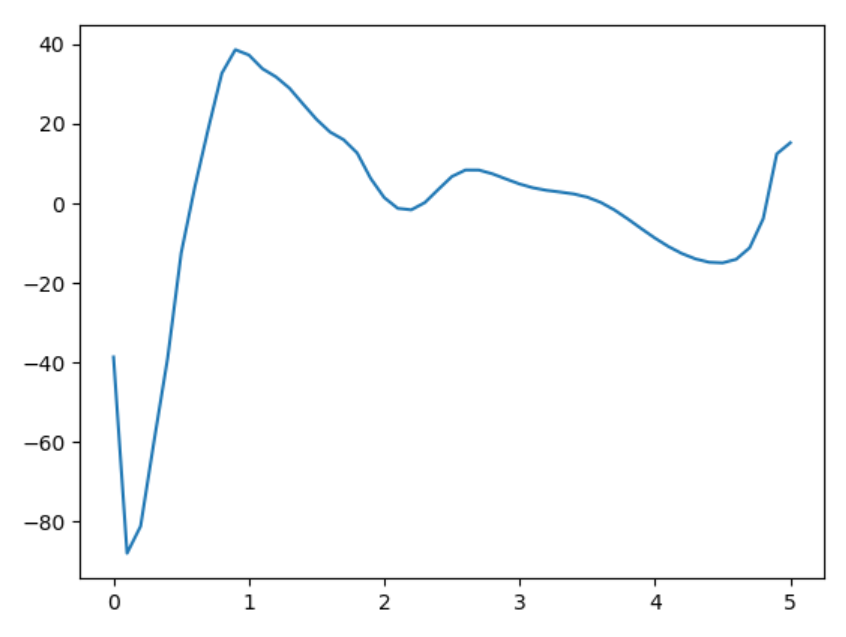
acrobot DIRCOL control with random init |
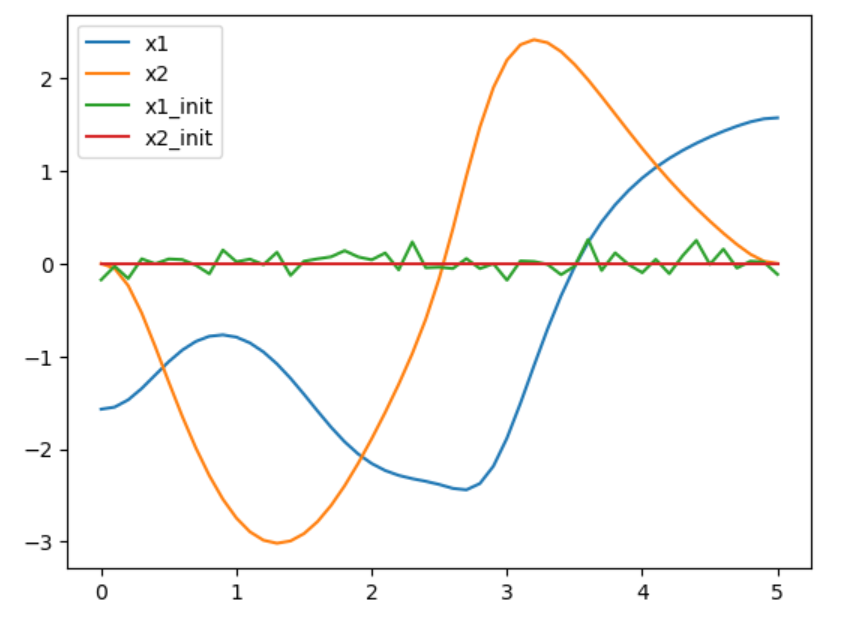
acrobot DIRCOL state with random init |
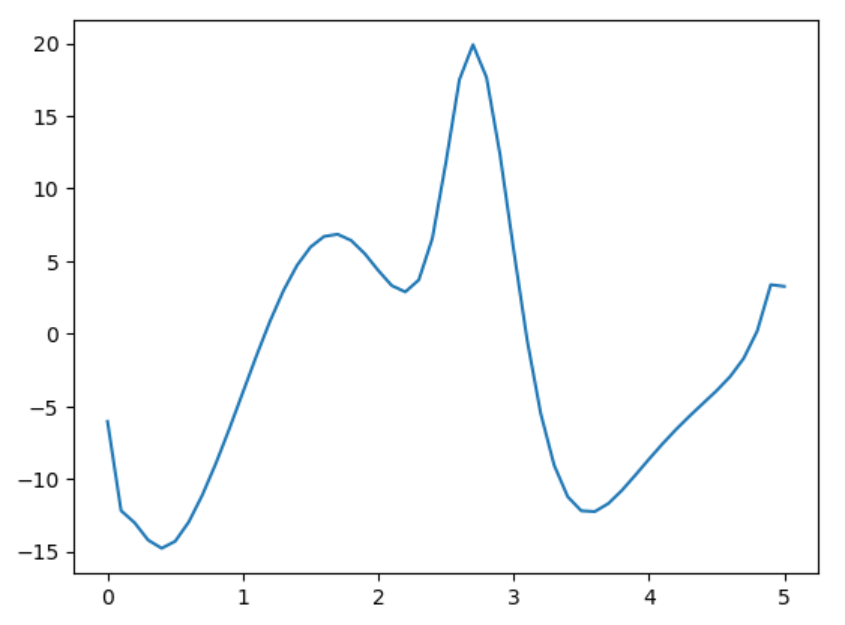
acrobot DIRCOL control with random init |
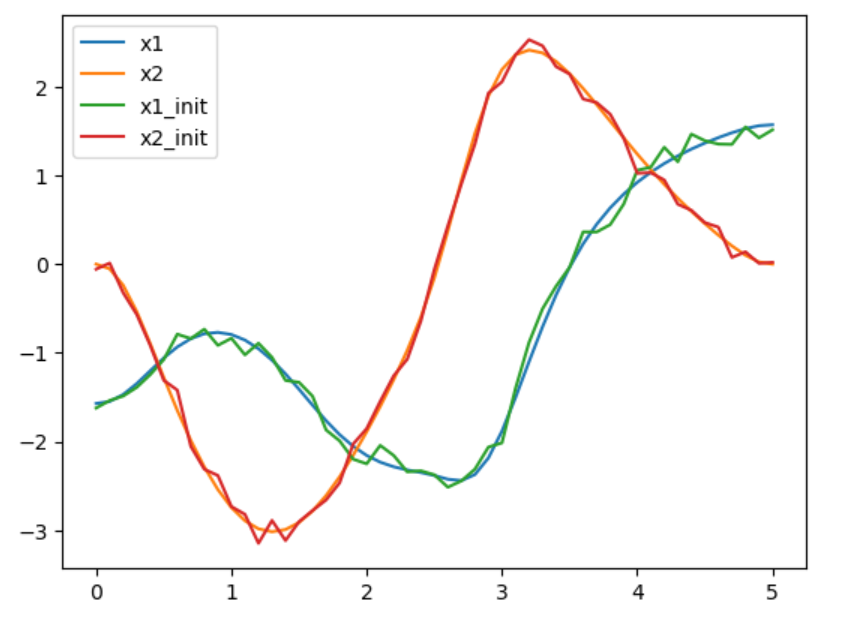
acrobot DIRCOL state traj with coarse initial state |
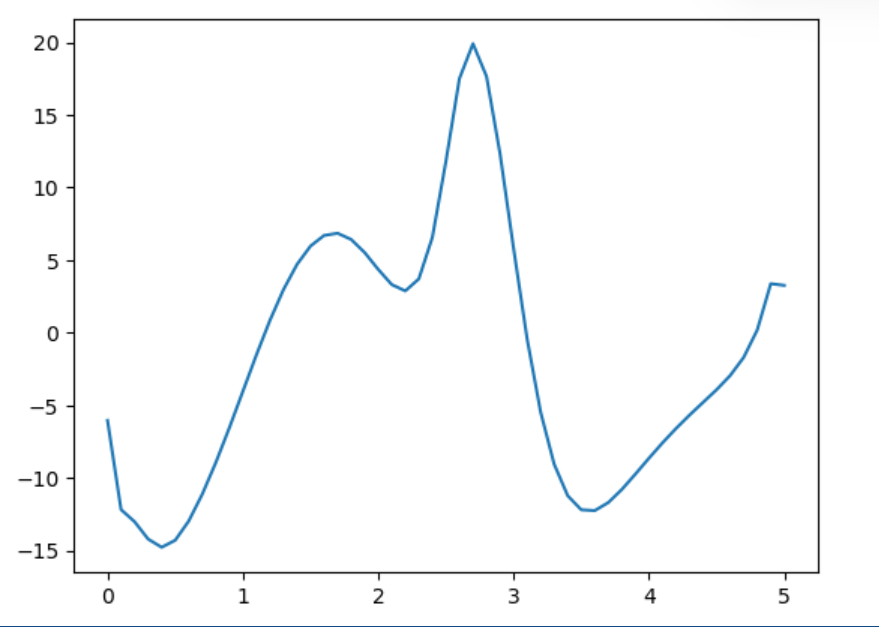
acrobot DIRCOL control traj with coarse initial state |

acrobot DIRCOL |

acrobot DIRCOL |
核心代码:
function dircol_dynamics(x1,u1,x2,u2)
#Hermite-Simpson integration with first-order hold on u
f1 = dynamics(a, x1, u1)
f2 = dynamics(a, x2, u2)
xm = 0.5*(x1 + x2) + (h/8.0)*(f1 - f2)
um = 0.5*(u1 + u2)
ẋm = (-3/(2.0*h))*(x1 - x2) - 0.25*(f1 + f2)
fm = dynamics(a, xm, um)
return fm - ẋm
end
function con!(c,ztraj)
z = reshape(ztraj,Nx+Nu,Nt) #整个Z变量是stack成x1 u1 x2 u2 的形式,reshape后每一列代表一个时刻的状态
c[1:Nx] .= z[1:Nx,1] - x0 #起点约束
@views dynamics_constraint!(c[(Nx+1):(end-Nx)],ztraj) #中间点系统方程约束
c[(end-Nx+1):end] .= z[1:Nx,end] - xgoal #这里给终点也加了一定要到目标的约束
end
总结
DIRCOL与DDP都是轨迹优化问题比较常用的方法,有着各自的优点与缺点,各地不同的实验室有着不同的集中点,都会更侧重于使用其中的某一个方法。下面仔细对比分析两者(详细的原因解释参考Lecture 11 12)。
| 指标 | DDP/iLQR(间接法) | Direct Collocation(直接法) |
|---|---|---|
| 动力学可行性 | 在整个迭代过程中,即使未完全收敛到局部极小值,系统动力学是一直可行的,因此即使优化未完全收敛,也可以将优化的结果给机器人执行,利于实时控制 | 在迭代过程中,由于不存在前向rollout的过程,因此,只有当优化完全收敛后,优化的变量 x k u k x_k \ u_k xk uk才是满足系统动力学约束的,不利于实时控制 |
| 初始状态轨迹估计 | 也正是由于rollout过程会一直保持系统动力学可行,因此无法给一条粗糙初始状态轨迹,只能给关于控制率 u u u的初始估计。因此不利于与一些粗糙的前端几何搜索或启发搜索结合(只能通过Cost方式结合) | 必须给关于 x x x和 u u u的初始估计,可以通过一些启发搜索或者一些RRT方案来搜索一条粗糙的初始轨迹作为优化的初始值,利于在复杂的环境中探索(可以方便的让优化的局部极小值保持在期望的附近) |
| 约束的处理 | 初始版本不能处理状态或输入上的约束。 u u u的约束较好处理,但是 x x x的约束一般来说要将整个DDP问题写成增广拉格朗日函数的形式来处理 x x x约束,再结合一些active set的trick也可以做到处理约束。但是,由于增广拉格朗日法的一些数值问题,在约束很苛刻时,问题迭代会变得病态 | 可以方便地处理 x u x \ u x u约束,实际上是把问题抛给商用/开源的非线性求解器。底层实现一般是对非线性优化问题利用SQP迭代求解。 |
| 速度 | 在无约束的情况下非常快,因为整个问题迭代过程的矩阵维度都很小,在有约束但是约束不苛刻的情况下,通过增广拉格朗日法收敛也比较快。时间复杂度是 O ( N ( n + m ) 3 ) O(N(n+m)^3) O(N(n+m)3)级别的 | 通常来说,构建成一个大矩阵的方式,即使利用了矩阵的稀疏特性,求解速度依旧会慢一些,时间复杂度是 O ( N 3 ( n + m ) 3 ) O(N^3(n+m)^3) O(N3(n+m)3)级别的 |
| 嵌入式平台实现 | 比较容易在嵌入式平台实现(问题维度较小) | 难以在嵌入式平台求解复杂的非线性优化或者SQP问题 |
| 数值问题 | 由于DDP法本质上算是一种shooting方法,要依赖串级的梯度和Hessian的传导,因此,会随着Backward pass迭代过程的积累的舍入和截断误差和矩阵的幂乘使矩阵的条件数变大,所以在Horizon大时,会使问题变得病态 | 通常来说使数值鲁棒的,因为不需要有这样的一个很长传导和误差积累过程 |
| 控制器 | 在迭代时,可以获得一个前馈+反馈的控制率,在收敛后,前馈控制率为0,免费获得了一个时变LQR问题的最优反馈控制率,因此不需要额外设计控制器来跟踪 | 优化收敛后得到的是仅仅是一条前馈轨迹,需要额外设计一个控制器来跟踪这条轨迹。 |
其他一些知识
- multi-shooting。一种介于DDP(全shooting)和DIRCOL(大矩阵)之间的方法,分段rollout,然后用约束把不同段连起来,算是以上提到的优缺点的折衷。
- 条件数condition number。条件数越大,表示矩阵离奇异状态(不可逆状态)越近。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









