







Autopilot:允许车辆保持车道,跟随前车,弯道减速,等等,处理从停车场到城市街道,再到高速公路的所有驾驶过程。
一、硬件:
8个120W像素的摄像头,每秒36帧,360度空间,内置144 Tops(每秒万亿次操作)算力的计算平台,用于运行这些神经网络。
不需要激光雷达、毫米波、超声波、高精地图,基于实时的摄像头。
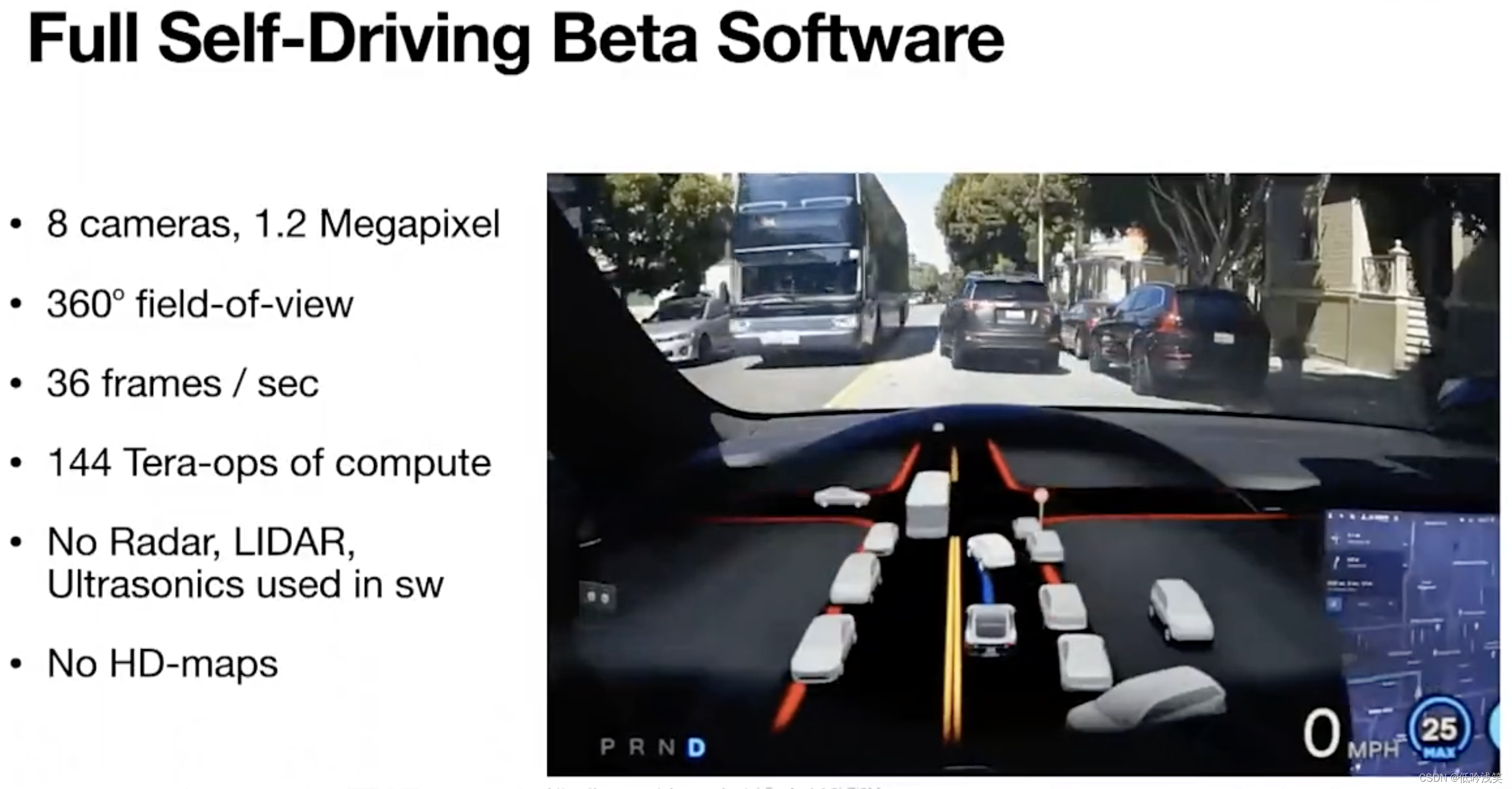
图1 硬件示意图
二、障碍物检测
2.1 障碍物表示

图2 图像空间效果图
图像空间分割:pixel-wise segmentation (可驾驶or不可驾驶),存在问题:1>感知结果在图像中,转三维空间会产生不必要的噪声。2>不能提供完整的3D结构,很难推理出所有悬空的障碍物,或者墙壁,或者其他可以遮挡场景的物体。

图3 深度建模效果图
深度建模:每个像素都有深度,利用相机射线反转到3D空间,密集的深度图。存下问题:1>近距离很好,远距离变得不一致,很难被后续流程使用。e.g.,墙不直了,弯弯扭扭; 2>靠近地面,点很少,很难针对障碍避让编写合理的逻辑; 3>2D深度到3D空间转化问题,每个相机都会生成一个深度图,很难生成一个汽车周围统一的三维空间。
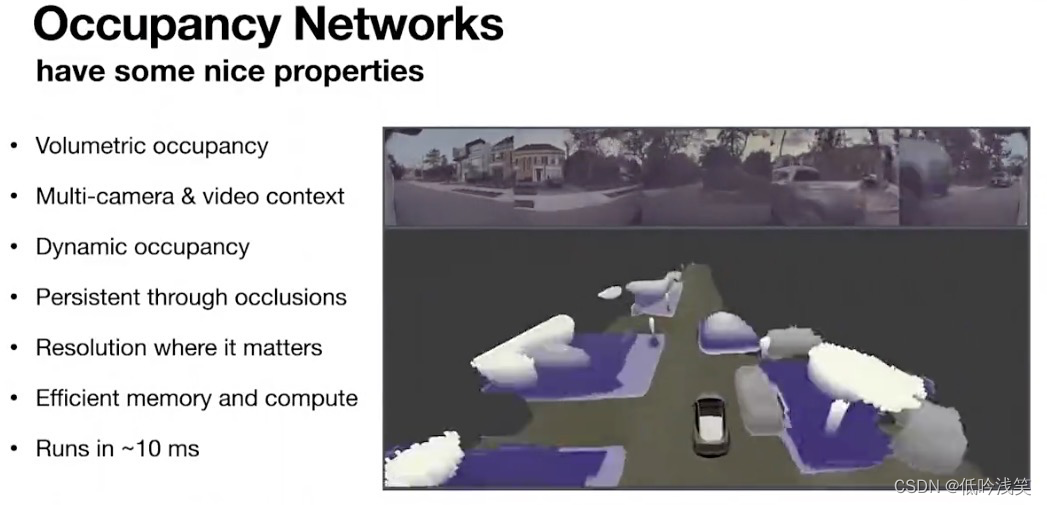
图4 占有网络效果图
解决方案->占用网络(Occupancy Network):
接受8个相机流作为输入,并生成一个汽车周围空间的体积化的占用值。每一个体素(或汽车周围的每一个位置),网络都会生成该体素是否被占用的结果。事实上,它生成了一个该体素(或三维位置)被占用或不被占用的概率值。网络完成所有内部传感器的融合,并产生单一的输出空间。生成静态物体的占用值,比如墙壁和树木之类的东西,也可以生成动态物体:如车,有时。也包括其他移动的障碍物,如道路上的碎片。输出在3D空格,可以预测一条曲线的存在。虽然它生成了密集的三维占有值,看起来体积庞大,但计算十分高效,因为他把分辨率分配到了关键的地方。图像存在距离远近的问题,但是在占用网络中,在与驾驶有关的所有体积中,分辨率几乎都一致。
速度:小于10ms,100HZ,比摄像机产生图像的速度快得多。

图5 几个摄像流,鱼眼摄像头,朝向正面的广角。左立柱摄像头,面向左边的摄像头。
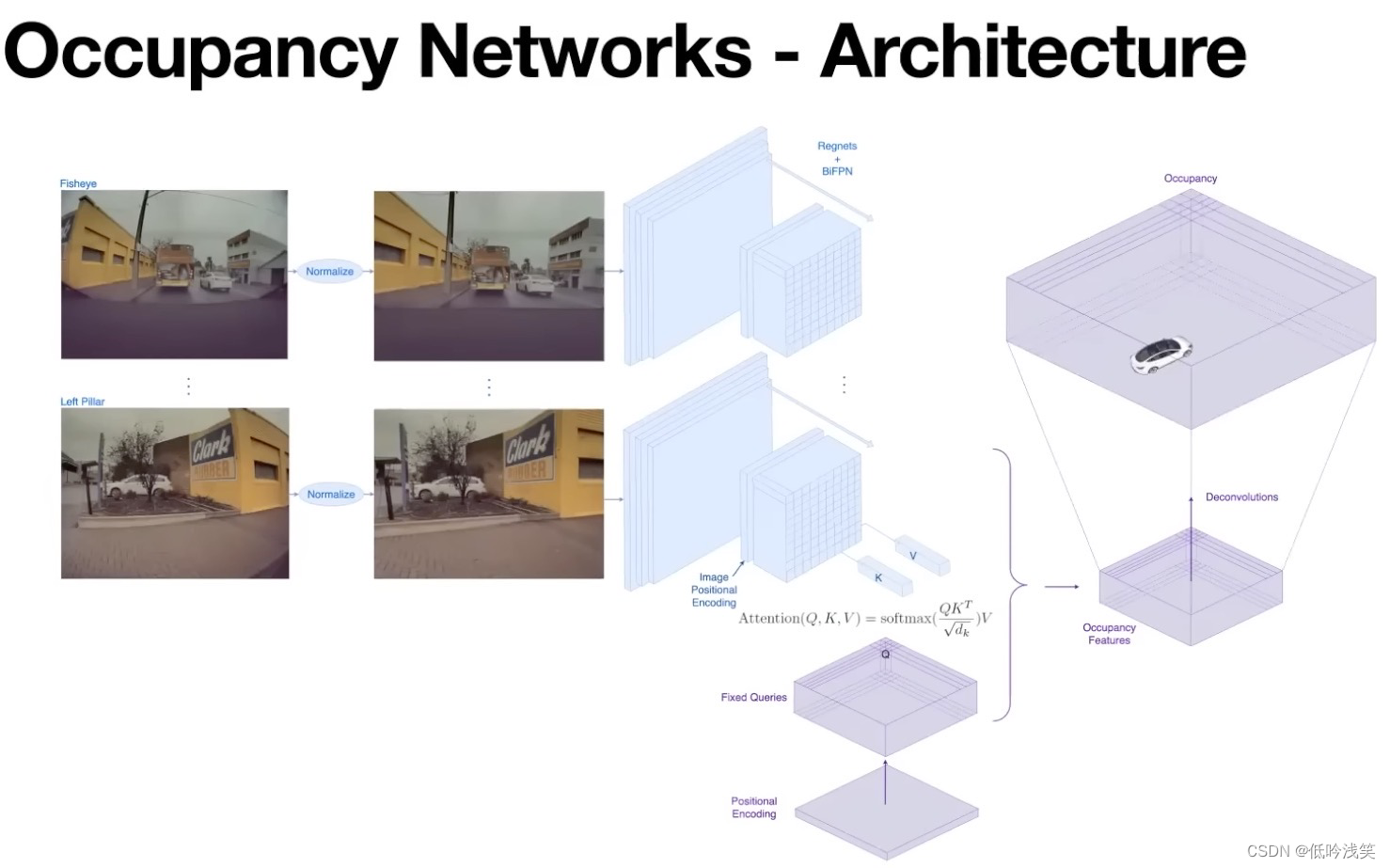
图6 占有网络结构图
2.2 占有网络技术方案
占有网络的总体网络结构:
- 输入:多个相机(鱼眼、正常相机),首先进行归一化,消除传感器本身的限制(e.g.,内部校准、图像畸变、类似因素),
- 特征提取:采用RegNets和BIFPNs来提取图像特征。
- 生成3D的占有体素:通过Query的查询方案,与几年前的《Occupancy networks》类似。查询一系列3D点,判断3D点是否可用。接受3D位置编码,将其映射为固定的查询,这些固定的查询参与每一个图像空间的特征。在图像空间中也嵌入了位置信息。3D Query参与所有图像流的图像空间查询,然后生成3D占用特征。
- 上采样:这些都是高维特征,很难直接计算,所以在较低的分辨率下生成这些高维特征。使用上采样技术,生成更密集的高分辨率占用值。

图7 动态VS静态?一些bad case没有明确的边界,区分物体类别会受到影响。行人看起来像"垃圾",塑料看起来像行人。
动态物体VS静态物体:最初采用占用网络的目的是处理静态的障碍物,如:树、墙,因为有不同的神经网络在车内运行,处理不同类型的障碍物,但是很难定义显式的树。动态网络采用其他的框架,但会出现了类似图5 的动静问题。
解决方案是,在通同一个框架中同时生成移动和静止的障碍物,防止有什么东西在移动和静止之间的缝隙中逃脱或转变。不存在绝对静止的物体,受到力后就会发生改变。

图8 添加动态网络检测的占有网络
占用值流(occupancy flow):在原来的静态物体检测框架中,添加了动态物体检测,如图8所示,但并不通过占用值来区分这些物体。可以有额外的语义分类,帮助后续的控制策略。就纯粹的占用值所言,并不区分某个空间被占用的原因是什么,只是给出瞬间占用值。但是这并不足够,瞬时占用值和速度有关,和障碍物类型有关。在不同的未来时间点,占用值会发生什么变化?比如:跟车场景。因此,除了预测占用值,还预测占用值流(occupancy flow)。这个流可以是占用值相对时间的一阶导数,也可以是高阶导数,预测更准确的时间流。为生成占用值流,接收多个时间步骤作为输入。从一段时间缓冲区中提取所有不同的占用值特征,将这些占用值特征对齐到一致的统一坐标系下,使用相同的上次样技术,来生成占用值和占用值流。

图9 占用值和占用值流的效果,添加占用值流的模型效果,红色行车方向相同,绿色行车方向相反,地面上有个垃圾桶。

图10 出现未知类别的障碍物

图11 出现未知的形状
占用流优点:1>直接避免由于障碍物分类而带来的问题,存在一些不知道类型的车(只露出一半),但这对控制不重要,如图10。通常,人们通过立方体或者多边形来表示运动的物体,但一些物体存在未知的突起(任意形态),通过占有网络,可以获得这些形态,不需要复杂的网络拓扑,如图11 2>改善控制技术栈,使用几何信息来推理遮挡情况,汽车知道被树或者路进行了遮挡,然后采用不同的控制策略来处理这个问题,并消除这种遮挡关系。因为有三维空间信息,明白多少速度/距离会撞上。控制车辆前挪,寻找遮挡物体。这个占用网络在很多不同的方面都有助于改善控制技术栈。
图12 NeRFs from the fleet

图13 真实世界运行NeFR的问题
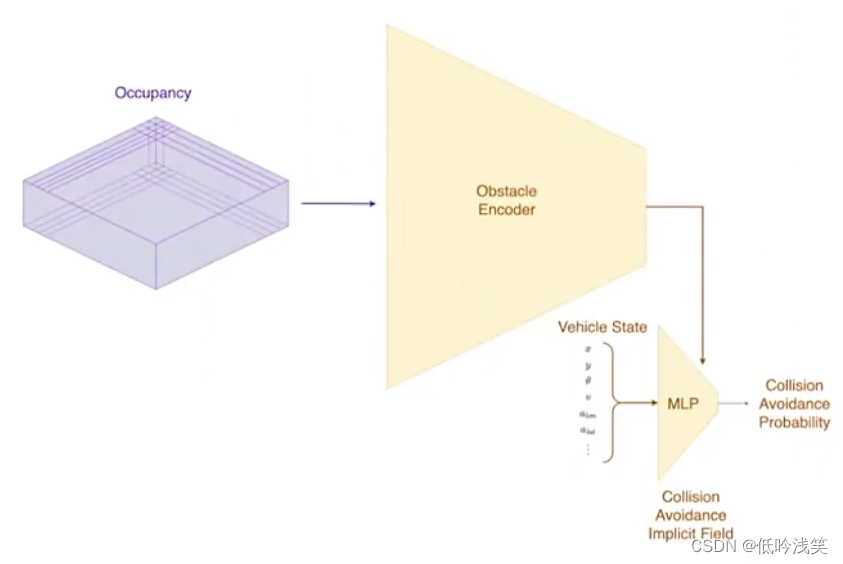
图14 添加语义保护的RGB示意图
Neural radiance field:占用网络是神经辐射场(neural radiance field)方法的扩展,神经辐射场尝试从多视角图像中重构场景。通常从单个点的多个图像中重建场景。从车队选取任意行程,有着不错的校准和轨迹估算技术栈,用这些生成精确的跨越时间的多条相机路线,然后运行最新的NeFR模型,通过三维状态生成可差分的渲染图像,生成高质量的三维重建。原始NeRF使用一个单一的神经网络来表示整个三维场景,最近作品Plenoxels,使用体素进行表示,还可以使用体素(微小的mlps体素)或其他的连续表示,对概率进行插值来生成可差分的渲染图像。真实世界运行NeFR有一些问题,主要是光的折射、反射、雾天、雨天等。解决方案是使用更高级别的描述符,在某种程度上不受局部光照瑕疵的影响。rgb本身包含大量噪点,在rgb上添加描述符,可以提供一种语义上的保护,防止rgb值变化。
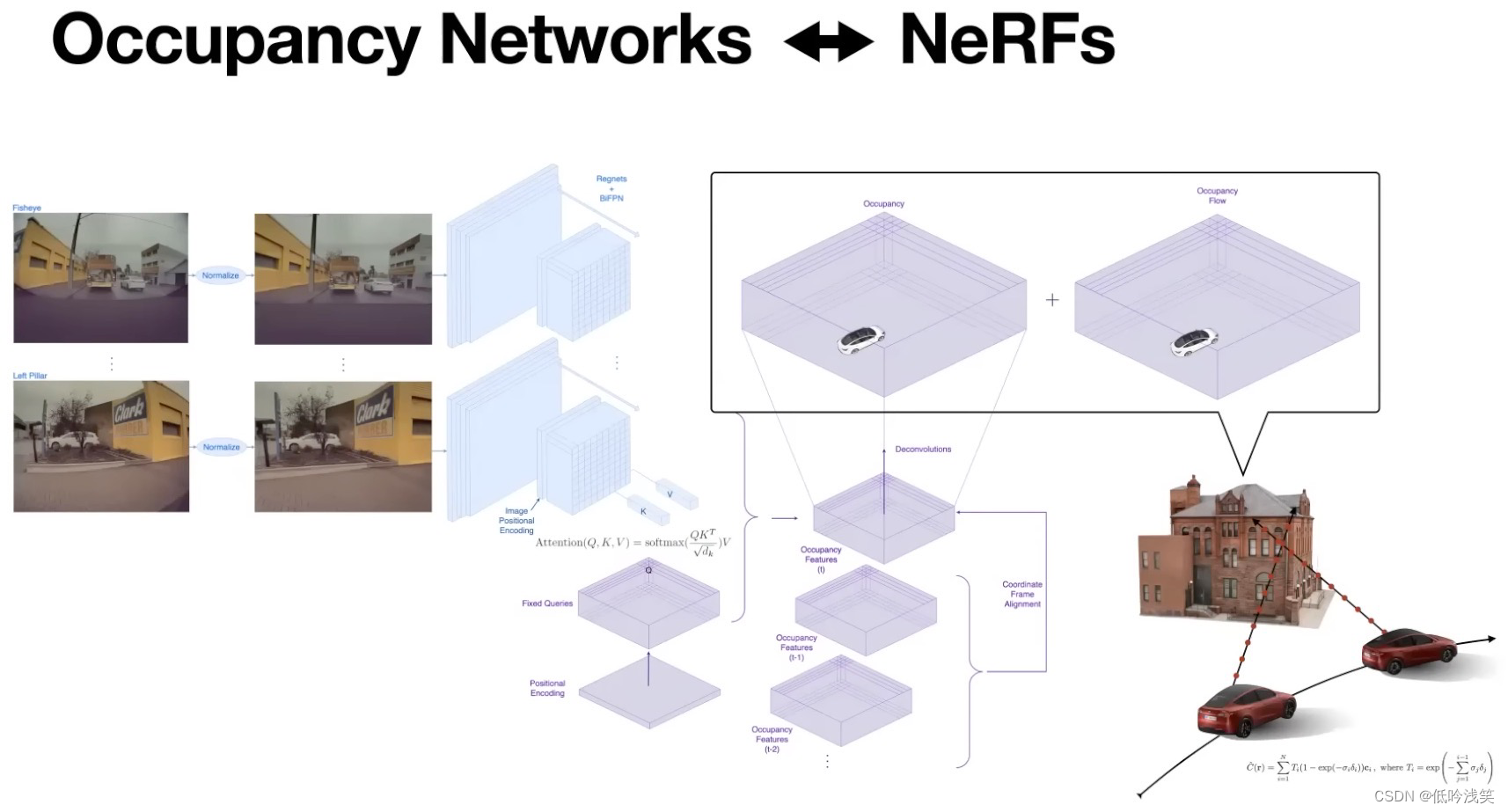
图15 添加NeRFs监督的占用网络
NeRFs优化占用网络:将可差分渲染架构NeRFs作为一个损失函数作用于占用网络的输出,因为这些占用网络需要若干个镜头来生成占用值,无法运行完整的NeRFs优化。Tesla 提出了精简优化版本,确保它所生成的占用值,能解释汽车在运行时接受到的所有传感器观测数据。当然,训练阶段使用这种监督也有帮助。除此之外,还可以通过对不同传感器数据的留出图像进行可差分渲染,来实现监督。通过运动的某种时间约束,这类监督可以对占用值,也可以对占用值进行监督。
2.3 避免碰撞
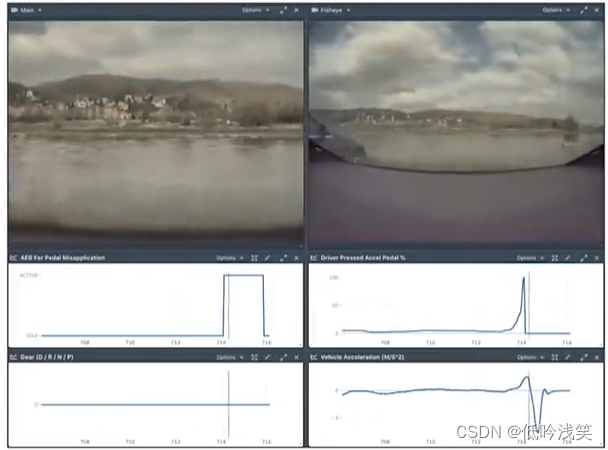
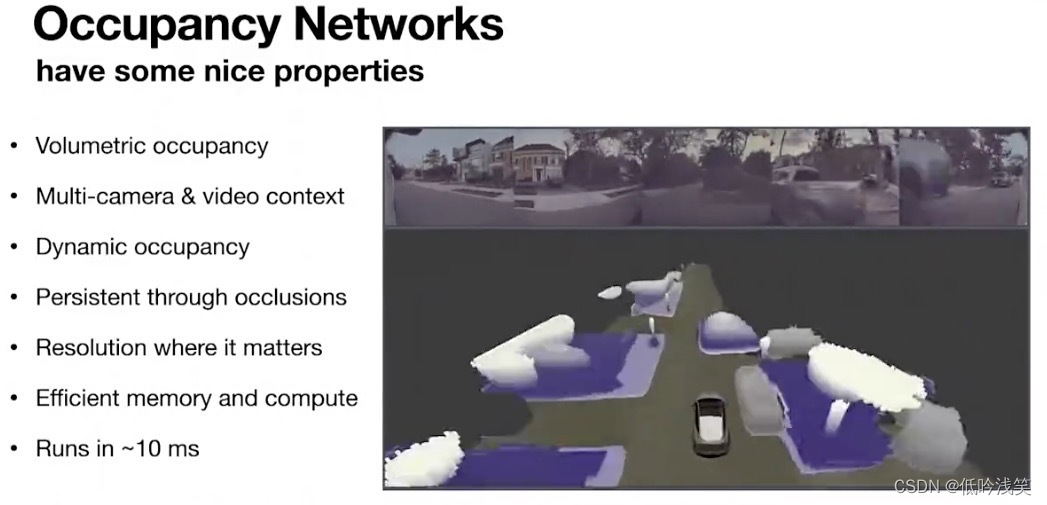
图16 autopilot避免行车危险
油门和刹车混淆:autopilot 可以避免
Self-driving:安全、舒适、合理的快
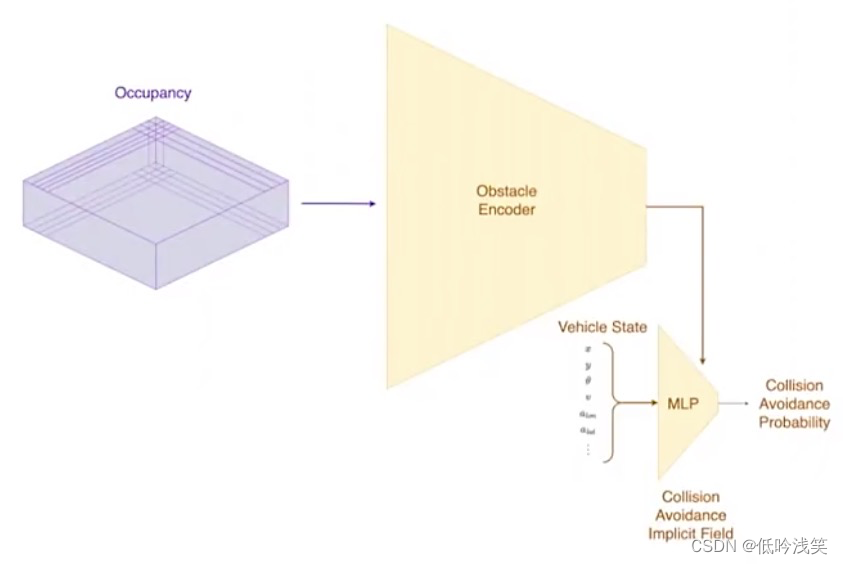
图10 汽车状态和碰撞概率预测
提前进行减速,需要在碰撞发生前很多秒就预测这个碰撞是可以避免还是不可以避免,以稳稳的踩下刹车,安全平稳地避免碰撞。
基于搜索的方法,搜索空间大,速度慢,汽车实时运行时,没有足够的时间来完成这样的计算。
Tesla采用神经网络做近似计算,采用最近出现的隐式场(implicit fields) 对障碍避让进行编码。从之前的网络中获取占用值,编码成一个极度压缩的多层感知器(MLP)。这个MLP用于隐式表示,在任何特定的查询状态下,某个碰撞是否可以避免。这里显式的是汽车的位置、方向、速度、侧向和纵向加速度。基于当前的汽车状态,给出发生碰撞的概率。比如,2s、5s或者某个时间范围内,碰撞是否可以避免?网络可以在几微妙内,快速查询出是否会发生碰撞的大概概率。

图11 汽车碰撞概率,绿色安全,黑色是障碍物,灰色是道路表面,红色是碰撞区域。 跟汽车的当前方向和车速有关。
汽车本身存在一定的尺寸,当汽车进行旋转,与周围的障碍物结合起来,碰撞场正在发生变化。
当车辆的方向改变,与道路方向对齐,通道会打开,变绿,这意味着汽车不会处于碰撞状态。
当车速或者刹车时间进行改变,碰撞场也会发生改变
汽车会在必要时介入,进行转向或者刹车,避免碰撞。
总结:
1.展示了如何使用多摄像机喝图像帧,来产生密集的占有值或者占有值流。
2.简要地展示了采用视觉自动标注以外,如何使用车队大量的多视角约束来进行监督。
3.一旦得到占用值,就可以把他应用于其他神经网络,以生成一个高校的碰撞避免场。
4.汽车永不碰撞。
相关Paper:
1.《Occupancy Networks: Learning 3D Reconstruction in Function Space》 CVPR2019
Github:https://github.com/autonomousvision/occupancy_networks
2.NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
3. Plenoxels: Radiance Fields without Neural Networks
关注两个方面:
- 输入,输出,标注
- 网络结构
















 2901
2901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











