






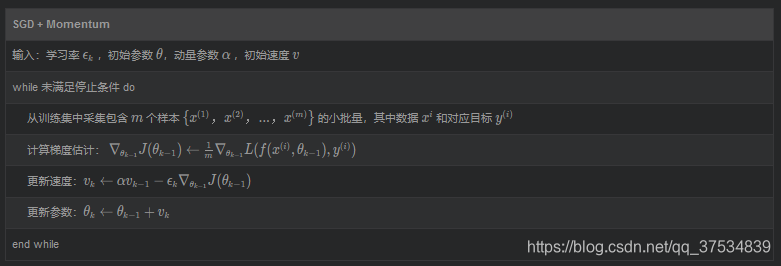
学习器
SGD
https://blog.csdn.net/kuweicai/article/details/102997831
学习策略
ReduceLROnPlateau
当一个指标停止改进时降低学习率。
- optimizer
- mode (str): One of
min,max - factor (float): Factor by which the learning rate will be reduced
- patience (int): Number of epochs with no improvement after which learning rate will be reduced.
- cooldown (int): Number of epochs to wait before resuming normal operation after lr has been reduced.
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
>>> scheduler = ReduceLROnPlateau(optimizer,mode='max', factor=0.1, patience=4, cooldown=0)
>>> for epoch in range(10):
>>> train(...)
>>> val_loss = validate(...)
>>> scheduler.step(val_loss)
CyclicLR
https://arxiv.org/abs/1506.01186
https://arxiv.org/pdf/1708.07120.pdf
https://arxiv.org/pdf/1908.06477.pdf
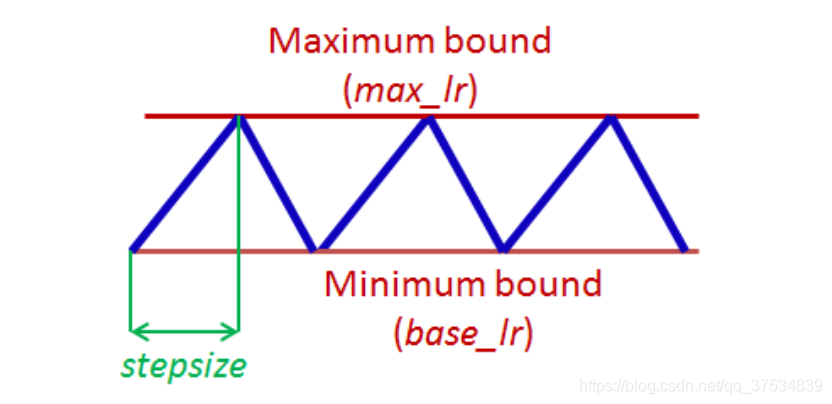
- base_lr (float or list) : lower boundary
- max_lr (float or list) : upper boundary
- step_size_up (int) – Number of training iterations in the increasing half of a cycle. Default: 2000 , stepsize equal to 2−10 times epoch
- step_size_down (int) – Number of training iterations in the decreasing half of a cycle. If step_size_down is None, it is set to step_size_up. Default: None
- cycle_momentum (bool) – If True, momentum is cycled inversely to learning rate between ‘base_momentum’ and ‘max_momentum’. Default: True
- base_momentum (float or list) – Lower momentum boundaries Default: 0.8
- max_momentum (float or list) – Upper momentum boundaries Default: 0.9
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
>>> scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.0001, max_lr=0.01,step_size_up=2000,step_size_down=None,cycle_momentum=True,base_momentum=0.8,max_momentum=0.9)
>>> data_loader = torch.utils.data.DataLoader(...)
>>> for epoch in range(10):
>>> for batch in data_loader:
>>> train_batch(...)
>>> scheduler.step()
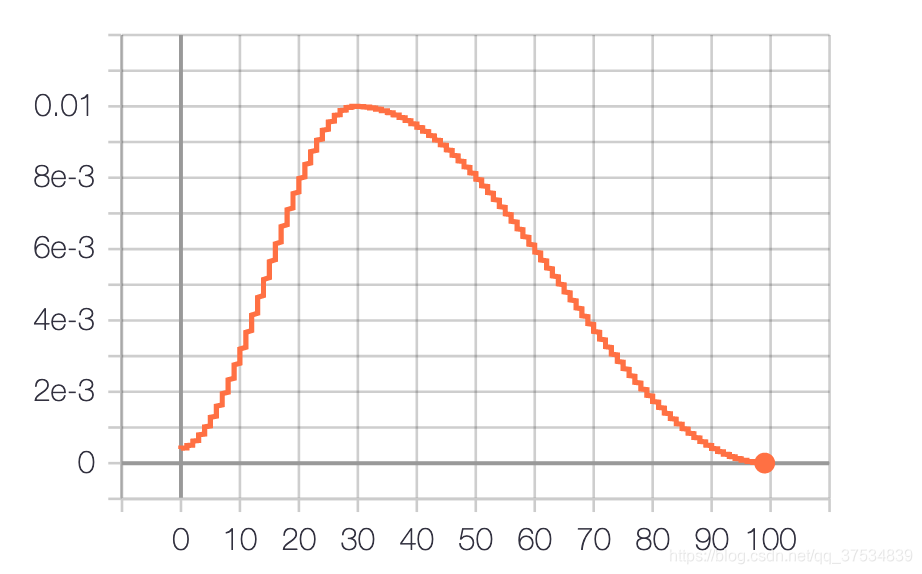
OneCycleLR
https://arxiv.org/pdf/1708.07120.pdf
- max_lr: upper boundary
- total_steps (int) – The total number of steps in the cycle. Note that if a value is not provided here, then it must be inferred by providing a value for epochs and steps_per_epoch. Default: None
- pct_start (float) – The percentage of the cycle (in number of steps) spent increasing the learning rate. Default: 0.3
- cycle_momentum (bool) – If True, momentum is cycled inversely to learning rate between ‘base_momentum’ and ‘max_momentum’. Default: True
- base_momentum (float or list) – Lower momentum boundaries Default: 0.85
- max_momentum (float or list) – Upper momentum boundaries Default: 0.95
- div_factor (float) – Determines the initial learning rate via initial_lr = max_lr/div_factor Default: 25
- final_div_factor (float) – Determines the minimum learning rate via min_lr = initial_lr/final_div_factor Default: 1e4
>>> data_loader = torch.utils.data.DataLoader(...)
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
>>> scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.01, total_steps = 782*100,pct_start=0.3,cycle_momentum=True,base_momentum=0.85,max_momentum=0.95,div_factor=25,final_div_factor=1e4)
>>> for epoch in range(10):
>>> for batch in data_loader:
>>> train_batch(...)
>>> scheduler.step()
CosineAnnealingWarmRestarts
SGDR
https://arxiv.org/pdf/1608.03983.pdf
-
T_0 (int) – Number of iterations for the first restart.
第一次循环iters -
T_mult (int, optional) – A factor increases TiT_{i}Ti after a restart. Default: 1.
每个循环结束后对于循环iters*T_mult,增长循环iters -
eta_min (float, optional) – Minimum learning rate. Default: 0.
>>> scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=2000, T_mult=1)
>>> iters = len(dataloader)
>>> for epoch in range(20):
>>> for i, sample in enumerate(dataloader):
>>> inputs, labels = sample['inputs'], sample['labels']
>>> optimizer.zero_grad()
>>> outputs = net(inputs)
>>> loss = criterion(outputs, labels)
>>> loss.backward()
>>> optimizer.step()
>>> scheduler.step(epoch + i / iters)
Stochastic Weight Averaging
Averaging Weights Leads to Wider Optima and Better Generalization
https://arxiv.org/pdf/1803.05407.pdf
In the example below, swa_model is the SWA model that accumulates the averages of the weights. We train the model for a total of 300 epochs and we switch to the SWA learning rate schedule and start to collect SWA averages of the parameters at epoch 160
>>> loader, optimizer, model, loss_fn = ...
>>> swa_model = torch.optim.swa_utils.AveragedModel(model)
>>> scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=300)
>>> swa_start = 160
>>> swa_scheduler = SWALR(optimizer, swa_lr=0.05)
>>>
>>> for epoch in range(300):
>>> for input, target in loader:
>>> optimizer.zero_grad()
>>> loss_fn(model(input), target).backward()
>>> optimizer.step()
>>> if i > swa_start:
>>> swa_model.update_parameters(model)
>>> swa_scheduler.step()
>>> else:
>>> scheduler.step()
>>>
>>> # Update bn statistics for the swa_model at the end
>>> torch.optim.swa_utils.update_bn(loader, swa_model)
>>> # Use swa_model to make predictions on test data
>>> preds = swa_model(test_input)
def moving_average(net1, net2, alpha=1):
for param1, param2 in zip(net1.parameters(), net2.parameters()):
param1.data *= (1.0 - alpha)
param1.data += param2.data * alpha
总结
分类
纯衰减学习率(FixdLR,ReduceLROnPlateau)
循环学习率(CyclicLR,OneCycleLR)
SWA(Stochastic Weight Averaging)
| 训练策略 | 需要的超参数 | 超参数的数量 | 详细的训练策略 |
|---|---|---|---|
| FixdLR | 总的iters(epochs),初始的学习率,衰减系数,步长 | 4 | 从初始学习率开始,每步长次epoch,学习率乘以衰减系数 |
| ReduceLROnPlateau | 总的iters(epochs),初始的学习率,patience,衰减系数,一个验证集指标,最低学习率 | 6 | 从初始学习率开始根据验证集的指标连续patience不增长(衰减),学习率乘以衰减系数 |
| CyclicLR | 总的iters(epochs),最高学习率,最低学习率,循环的步长(一般为2-10epoch) | 4 | 在总的iters内循环步长,每个步长内进行一次学习策略变化 |
| OneCycleLR(Warmup) | 总的iters(epochs),最高学习率,warmup阶段(一般为0.3),初始学习率(一般为最高学习率/25),最终学习率 (一般为最高学习率/10000) | 5 | 总的iters先进行warmup提高学习率,再下降学习率 |
| SWA | 基础学习策略,进行swa的epoch数量,swa的更新率,swa后学习率的衰减epoch | n+3 | 在基础学习策略后进行swa |
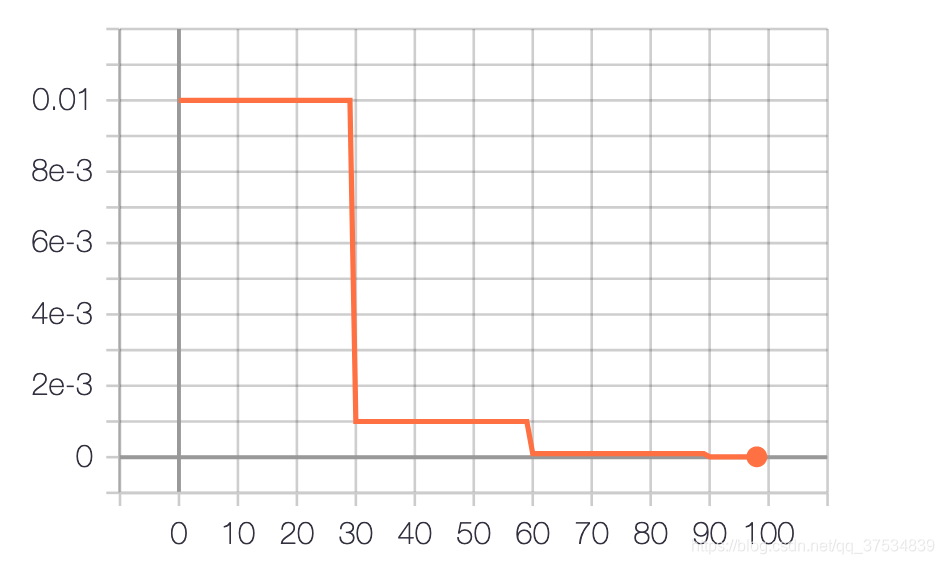
FixdLR
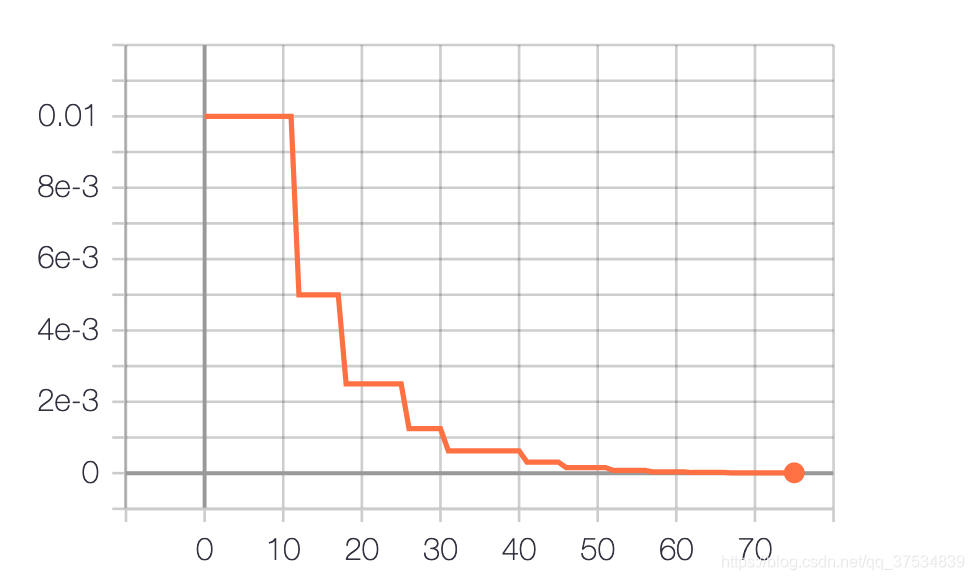
 ReduceLROnPlateau
ReduceLROnPlateau
CyclicLR
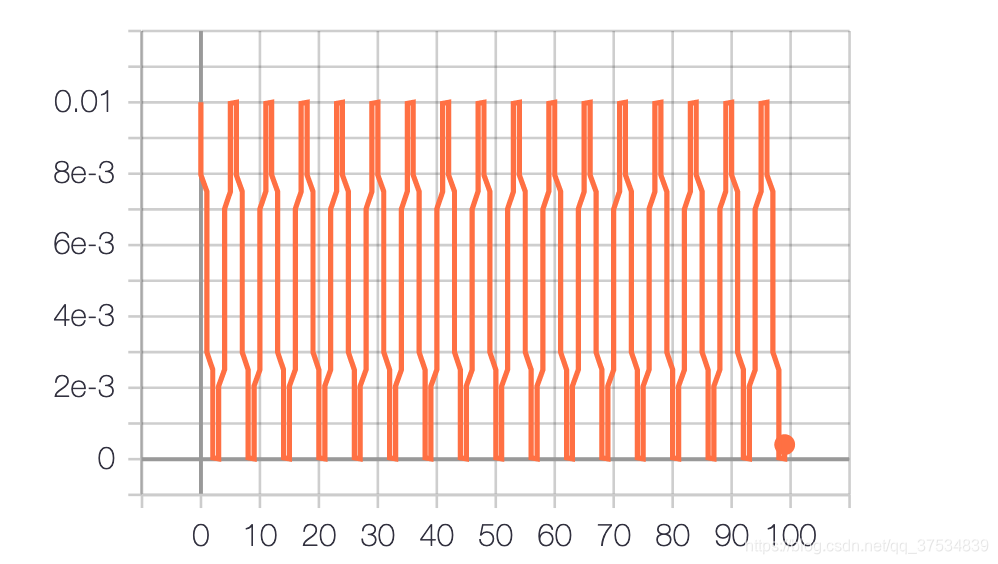
OneCycleLR(Warmup)
SWA
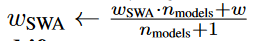
实验
实验设置:
基础的学习器:optimizer = optim.SGD(net.parameters(),lr=0.01,momentum=0.9,weight_decay=5e-4)optim.SGD(net.parameters(),lr=0.01,momentum=0.9,weight_decay=5e-4)
数据集:cifer10(训练集50000,测试集10000,10分类)
网络模型:双流efficient_b0的backbone,拼接featuremap,avgpool,fc。
batchsize=64
| 训练策略 | 具体的超参数设置 | 验证集最高指标 | run |
|---|---|---|---|
| FixdLR | 初始学习率0.01,100个epoch,每30个epoch衰减为原先0.1倍 | 86.19 | 1 |
| ReduceLROnPlateau | 初始学习率0.01,100个epoch,每验证集上准确率连续4次不增长,衰减原先0.5倍,最低1e-5 | avg(85.76,85.16)=85.46 | 2 |
| ReduceLROnPlateau | 初始学习率0.01,100个epoch,每验证集上准确率连续4次不增长,衰减原先0.1倍,最低1e-5 | 86.47 | 1 |
| OneCycleLR(Warmup) | 100个epoch,最高学习率0.01,前30个epoch为warmup阶段,初始学习率(一般为最高学习率/25),最终学习率 (一般为最高学习率/10000) | avg(86.84,86.84)=86.84 | 2 |
| CycleLR(triangle) | 100个epoch, 最高学习率0.01,最低学习率1e-5,每5.12个epoch进行一次循环,包括2.56个epoch线性从最低学习率到最高和2.56个epoch从最高学习率到最低学习率 | avg(86.61,86.44)=86.53 | 2 |
| CycleLR(cos) | 100个epoch, 最高学习率0.01,最低学习率1e-5,每6个epoch进行一次循环,包括3个epoch线性从最低学习率到最高和3个epoch从最高学习率到最低学习率 | 86.40 | 1 |
| SWA(FixdLR) | 前80epoch维持0.01学习率,从第80到110epoch从0.01线性衰减到1e-5,最后10epoch维持1e-5 | 86.38 | 1 |
| SWA(CosineAnnealingLR) | 前80epoch使用CosineAnnealingLR学习策略,从第80到110epoch从0.01线性衰减到1e-5,最后10epoch维持1e-5 | 87.02 | 1 |
| SWA(FixdLR) | 初始学习率0.01,前80epoch使用FixdLR学习策略,每35个epoch衰减为原先0.1,从第80到110epoch从1e-4线性衰减到1e-5,最后10epoch维持1e-5 | 85.99 | 1 |
分析
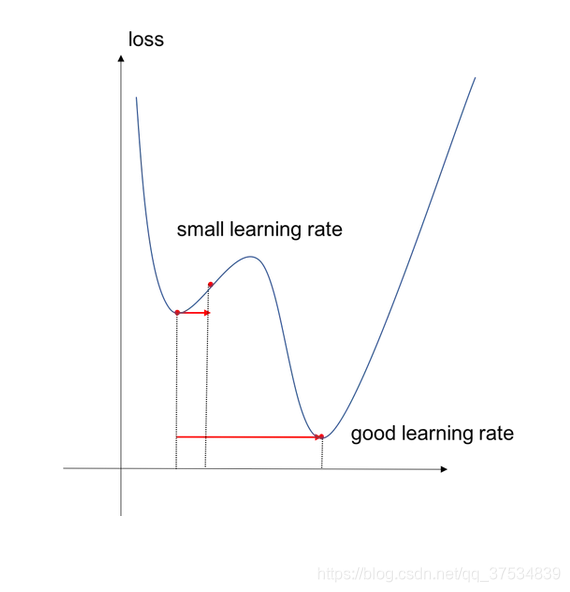
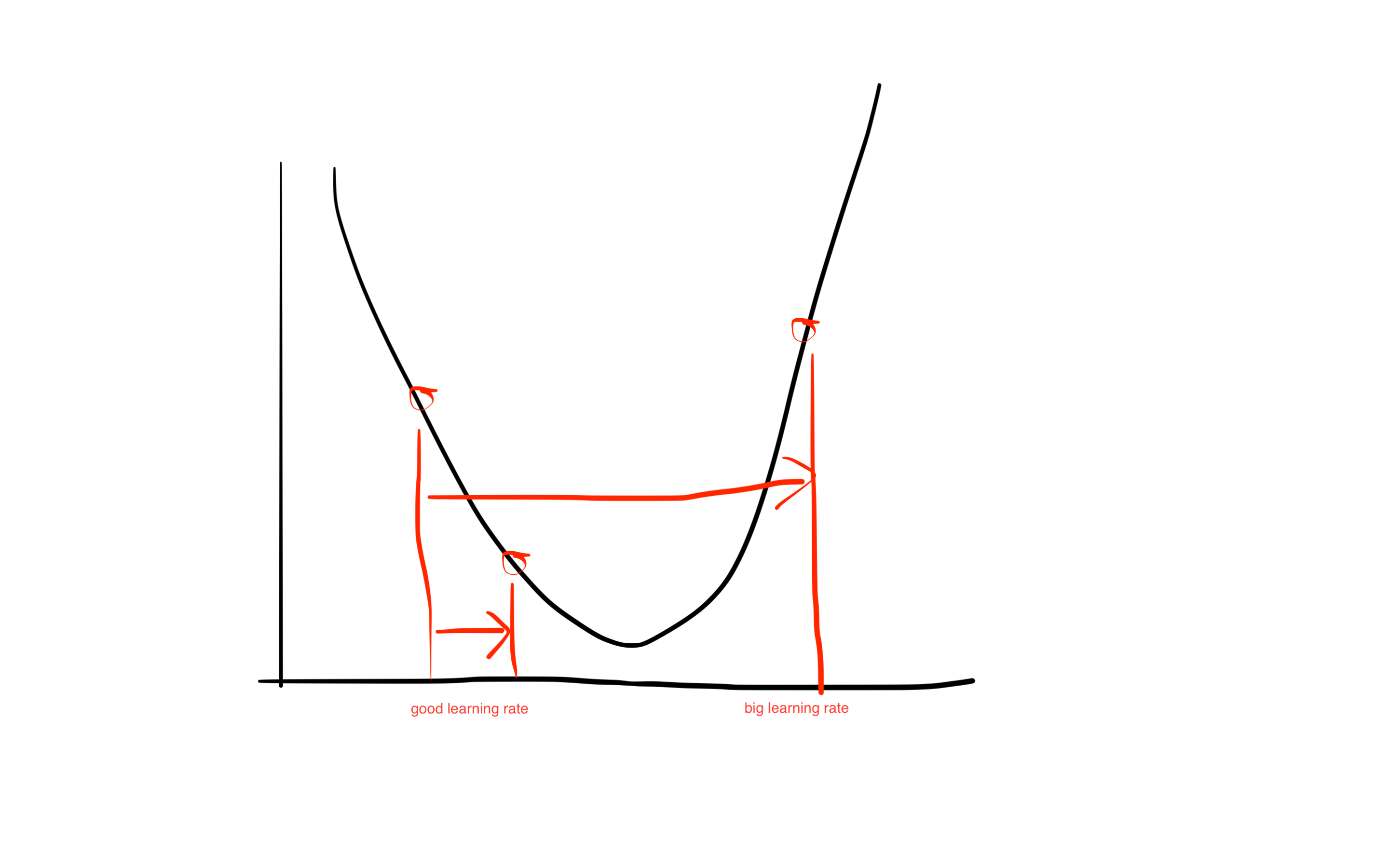
1.CLR的有效的原因?
衰减式的学习策略可能到达一个鞍点并且无法走出,增长的学习率有助于快速走出鞍点。
最佳的学习率在bounds之间,相比于固定的学习率,一个循环的结果更接近最佳的学习率。大学习率与小学习率的trade-off
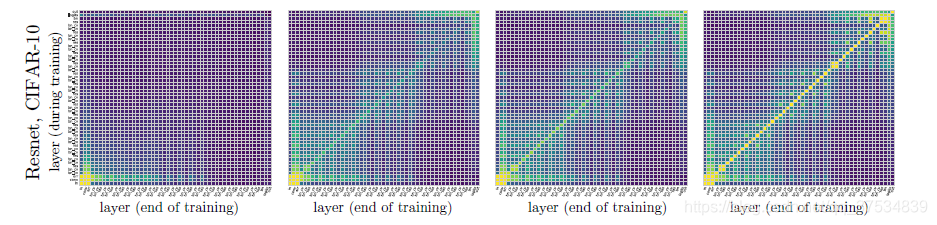
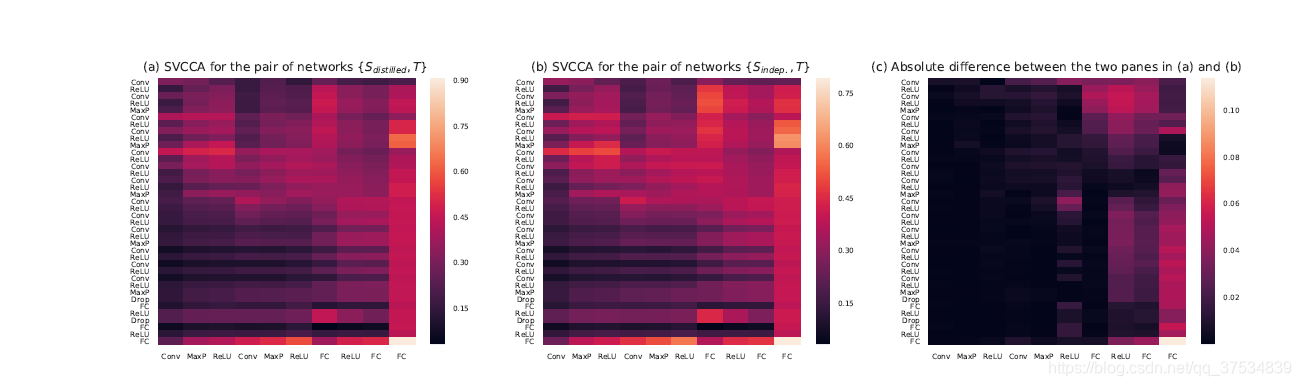
CCA分析*
CCA: 维持仿射变换不变的,快速比较两个网络层representation相似度的一种工具(计算方法)
google brain 2017 NIPS上提出
0->35->65->100:浅层先收敛,深层后收敛
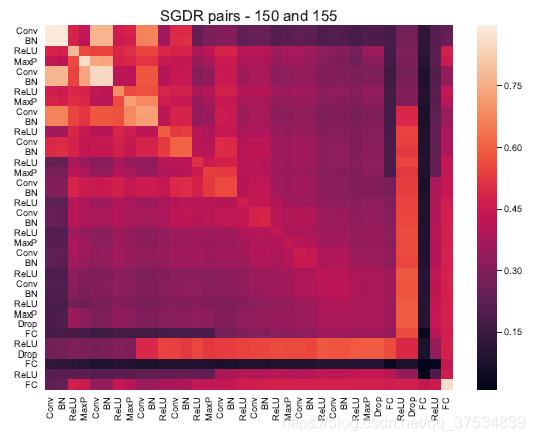
SGRD,restart从高处到低处,实现,并没有改变浅层的参数,改变的是深层的参数,完成一次倾向于跨越障碍的轨迹。
对于蒸馏的解释
2.warm up的有效性原因?
最初在resnet的论文中出现,使用warm up的原因是:初始学习率太大以至于网络无法收敛,因此从小的一个学习率warm up网络。提供全连接层的稳定性。
好的回答:
-
在训练的开始阶段,模型权重迅速改变mini-batch size较小。
-
样本方差较大。
第一种情况很好理解,可以认为,刚开始模型对数据的“分布”理解为零,或者是说“均匀分布”(当然这取决于你的初始化);在第一轮训练的时候,每个数据点对模型来说都是新的,模型会很快地进行数据分布修正,如果这时候学习率就很大,极有可能导致开始的时候就对该数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。当训练了一段时间(比如两轮、三轮)后,模型已经对每个数据点看过几遍了,或者说对当前的batch而言有了一些正确的先验,较大的学习率就不那么容易会使模型学偏,所以可以适当调大学习率。这个过程就可以看做是warmup。那么为什么之后还要decay呢?当模型训到一定阶段后(比如十个epoch),模型的分布就已经比较固定了,或者说能学到的新东西就比较少了。如果还沿用较大的学习率,就会破坏这种稳定性,用我们通常的话说,就是已经接近loss的local optimal了,为了靠近这个point,我们就要慢慢来。第二种情况其实和第一种情况是紧密联系的。在训练的过程中,如果有mini-batch内的数据分布方差特别大,这就会导致模型学习剧烈波动,使其学得的权重很不稳定,这在训练初期最为明显,最后期较为缓解(所以我们要对数据进行scale也是这个道理)。 -
有助于减缓模型在初始阶段对mini-batch的提前过拟合现象
-
保持分布的平稳有助于保持模型深层的稳定性
作者:香侬科技
链接:https://www.zhihu.com/question/338066667/answer/771252708
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3.SWA有效的原因?
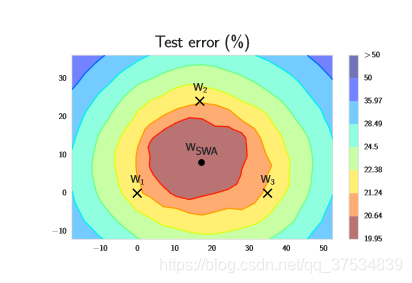 减少方差,----->在误差可控的范围内,不同模型的差异越大越好。循环余弦策略好于固定策略
减少方差,----->在误差可控的范围内,不同模型的差异越大越好。循环余弦策略好于固定策略
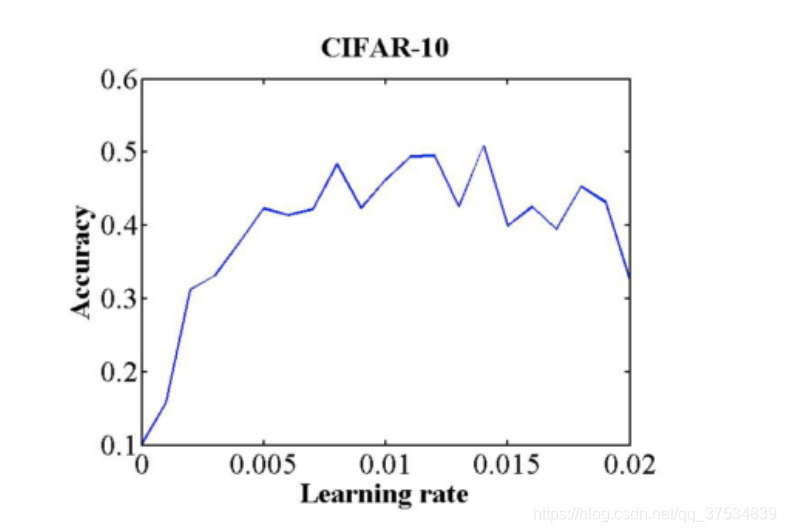
4.如何找到一个好的初始学习率?
LR test (网格搜索)

















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









