










 本文详细解释了PTX库中mma指令在处理1bit矩阵乘法(m16n8k128)时,如何利用线程和寄存器进行数据分配。矩阵A和B的存储方式,以及矩阵C的结果生成过程都被清晰地阐述。
本文详细解释了PTX库中mma指令在处理1bit矩阵乘法(m16n8k128)时,如何利用线程和寄存器进行数据分配。矩阵A和B的存储方式,以及矩阵C的结果生成过程都被清晰地阐述。
PTX 的mma指令用于计算不同数据类型的矩阵乘法,目前在CUTLASS库中wmma和mma都有使用。
在此记录下mma指令在计算1bit矩阵乘法时,怎么理解其中的线程中的寄存器对于矩阵数据的存放。
这里以1bit m16n8k128为例。
原PTX文档链接如下:
matrix-fragments-for-mma-m16n8k128
一、mma.m16n8k128

原文档这句话是说,这里将会用一个warp(通常是32个线程)执行1bit矩阵大小为m16n8k128的矩阵乘法。m16n8k128的意思是,矩阵A尺寸是16*128(row-major),矩阵B尺寸是128*8(col-major),结果矩阵C尺寸是16*8(row-major)(结果矩阵一般是float数据类型)。注意,这里仍旧是1bit为一个数据。
然后1bit矩阵的所有数据都会被32个线程瓜分。具体怎么瓜分呢?
二、1bit矩阵的线程具体分配过程理解
2.1 矩阵A

图1
PTX文档中对于1bit矩阵数据的瓜分过程写的很清楚了,但是一开始很难理解到底是什么意思。
这里记录一下自己对于它们的理解。
例如,针对矩阵A尺寸为16*128,它一共有16*128个1bit数据,因此需要占用这么大的内存空间。
如图1所示,这里分配了编号为T0到T31的一共32个线程用于装载矩阵A数据,每个线程分配2个.b32寄存器。计算一下,一共是32x2x32=2048bit,刚好矩阵A大小也是16*128=2048bit,刚好装下。
根据图1所示,32个线程进行了一个8行4列的排布,并且每个线程中都有两个.b32大小的寄存器。第0到第7行的数据都被均分到32个线程的第一个寄存器中。第8到第15行的数据都被均分到32个线程的第二个寄存器中。为了方便理解,画一个简图2:

图2 线程和寄存器位置简图
根据图2应该可以把线程中寄存器的位置分配和矩阵A在线程的寄存器中的分布位置联系起来。
2.2矩阵B

图3
矩阵B尺寸是128*8bit。32个线程T0到T31按照4行8列排布,由于矩阵B本身是列排列(col-major),所以线程的顺序也是列排布的顺序,第一列下来是T0,T1,T2,T3。每个线程分配1个.b32寄存器。所以是每32个相邻的bit数据放进一个.b32寄存器中。计算一下,也是刚好放进去。
2.2矩阵C
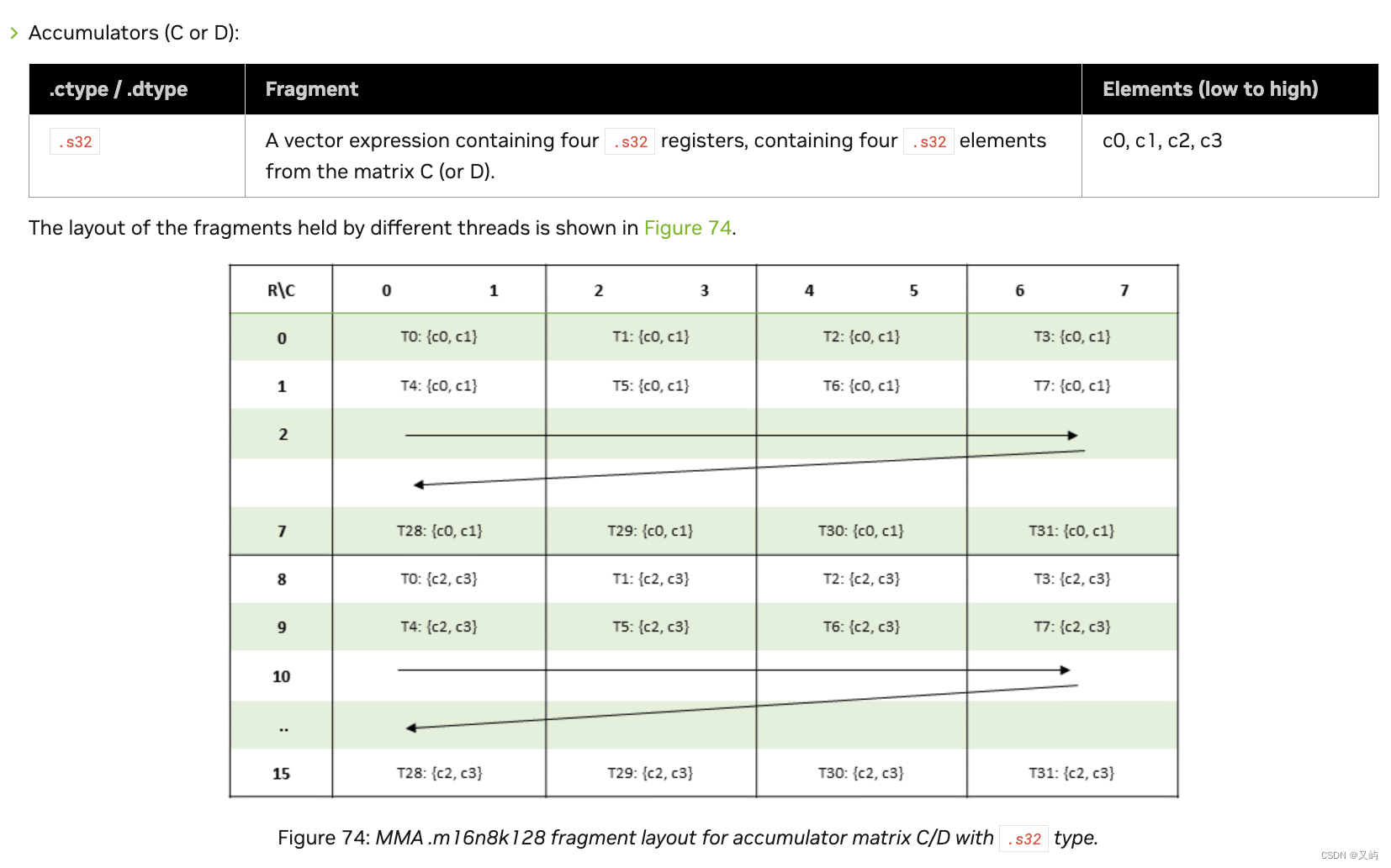
图4
矩阵C大小是16*8,数据类型是.s32。线程T0到T31按照8行4列排布,每个线程里面装4个.s32寄存器,也就是说可以装4个矩阵C数据。
矩阵C的前8行数据,每两个数据为一组,顺序装进每个线程的前两个寄存器中。
矩阵C的后8行数据,每两个数据为一组,顺序装进每个线程的后两个寄存器中。
32个线程和寄存器的位置排布如图5所示。
















 981
981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









