







论文简介:
近些年来,GAN在超分辨率上取得了巨大成功,特别是2018年,引入了感知损失作为生成图像视觉质量的评判方法。作者将用GAN来解决超分辨率分成了两种类型:1、图像重建。利用MSE(均方误差)损失函数,来提高图像的PSNR(峰值信噪比)。然而作者提出了,用这种方法超分辨率的图像,虽然PSNR很高,但是人看上去却效果并不好,可能会过于平滑或粗糙。2、图像生成。这种方法是目前普遍效果较好的,因为图像的生成过程中,可以不必拘泥于某一固定的指标(后面作者也提到了,很难用某一固定的指标来像人一样,衡量生成图像的逼真度),而引入视感知损失,从而生成更加逼真的纹理和细节。作者就是从之前的基于图像生成的超分辨率模型改进,而提出的这篇文章。

目前存在的生成模型,最大的问题就是对生成图像的评价。虽然感知损失函数的评判结果和人类的评判结果相似,然而作者指出,这些感知损失存在的问题——不可微和不稳定。由于损失函数不可微,这就使得利用梯度来优化变得困难。
为了解决这些问题,作者提出了RankerGAN模型。这个模型有相比较于之前的超分辨率模型,最大的创新就是作者引入了Ranker机制。作者提出,人在评判图像时,是对于一组图像进行排序,从而区分出哪个质量更高,而不是给每一个图片一个确定的得分。这与之前对于图片的评判方式很不一样。作者以2018年最牛的两个超分辨率模型SRGAN和ESRGAN为基础,用两种模型生成的结果用感知损失计算后,排序,再用排序结果来对Ranker进行训练,从而得到了超过两种模型的新模型。从某种意义上说,Ranker的引入,让原本不可微的感知损失函数变得“可微”,从而可以根据感知损失的梯度对生成器进行优化,Ranker是感知损失与生成器的一个桥梁。
总结文章的贡献:
1、作者提出了一个新模型,克服了以往感知函数不可维的弊端,从而可以从感知函数的方向上去优化G。
2、作者提出的模型,是用以往的模型作为数据来训练的,融合了用于训练的模型的优势,达到了超越他们的效果。
3、作者指出,模型用不同的模型来训练,可以达到不同的效果。
关于Ranker:
先说一下文章最核心的部分——Ranker。Ranker的引入,使得模型可以利用更加符合人类观念的NIQE函数,从而引导生成器生成更符合人类观念的超分辨率图。
1、Ranker的结构:
Ranker是一个孪生神经网络,也就是由两个结构一样的神经网络捆绑在一起组成的。网络接收两张不同的输入图像,计算出两个rank值,经过Margin Ranking Loss对两个rank值求损失,从而输出rank损失。在使用时,其实只使用孪生神经网络的其中一个神经网络,得到网络的输出rank值。
2、Ranker训练过程
首先作者将低分辨率图y,用不同的超分辨率模型,生成超分辨率图x1,x2…xn。之后,用NIQE函数对生成的超分辨率图进行计算,每一个图有一个计算值(值越小,代表图像质量越好)。之后对x1,x2…xn进行成对的排列组合,得到 pair-wise rank images,即(xi,xj,labelij),其中若xi>xj,labelij=1;若xi<xj,labelij=-1。之后用pair-wise rank images来训练Ranker。我们希望训练后的Ranker可以反映图像NIQE的值,也就是说,我们希望pair-wise rank images输入到Ranker中后,可以按照预先计算的NIQE输出正确的排序。为此,作者引入了margin-ranking loss,这是常见的用于优化排序模型的损失函数。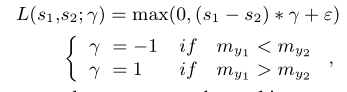
其中s1,s2,是由Ranker这个孪生网络给出的得分,my1,my2是NIQE对两个不同的超分辨率结果y1,和y2的计算值。e则是控制s1和s2距离的一个阈值。从公式来看,当L=0时,s1和s2的距离应该至少大于e。
这里个人认为,文中这个公式的负号错了,应该是
r=1 if my1 < my2
r=-1 if my1 > my2
因为当y1比y2效果好时,有my1<my2,此时应该r=1。要想L=0,应该使得(s1-s2)* r + e < 0,推得出s1<s2-e。即s1的排名要比s2的排名低至少e的大小。这与NIQE的评判标准相同,也与文章后面提到的

符合。接下来就是Ranker的优化函数,用来最小化L。其中 日R 是Ranker的参数,从这也能看出,Ranker两个通道的参数是一样的。
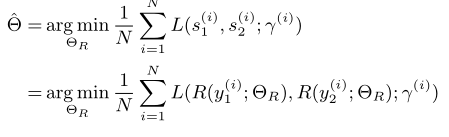
3、Ranker loss:
Ranker loss不是用来训练Ranker的,而是由训练好的Ranker计算出来,用于优化生成器的。
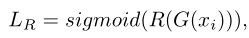
这里个人有个小小的疑问,为啥要将计算出的ranker score进行sigmoid归一化?
生成模型:
这里的生成模型,作者用的标准SRGAN,唯一同的是,在SRGAN生成图像后,添加了一步:将生成的图像输入到Ranker中,计算rank score,作为Ranker loss参与到生成器的优化。
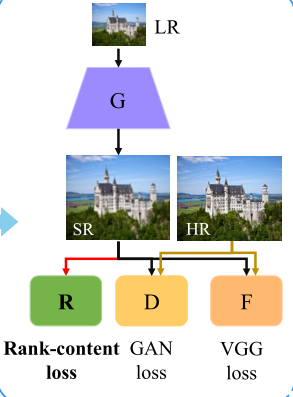
其中GAN loss 和VGG loss都与原SRGAN中的一样。
总结:
正如文章中所说,RankerSRGAN可以结合在训练Ranker时所用的超分辨率模型的优点,得到超过他们的效果。个人认为,这是因为Ranker通过NIQE的排序,对相应的图像进行特征提取,获得了捕捉高NIQE图像所存在的缺陷的能力。有了捕获高NIQE的能力后,Ranker就可以在训练生成器时,避免生成器发生这些问题,即避免了SRGAN和ESRGAN(文章中的Ranker,是用这两种模型的结果进行训练的)生成图像时的弊端。
个人推测,固定NR-IQA,当参与训练Ranker的超分辨率模型增多时,Ranker的训练计算量会上升,但Ranker的能力也会增加。
个人读文章后的一个疑问:
为什么NIQE是不可微的,而用神经网络拟合的“NIQE”就是可微的了?















 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









