






首先申明:
1.本次实验原代码来源为笔者所在大学的自然语言处理实验课程提供,非笔者完全原创,笔者只在其基础上进行了一些修改和优化。如构成侵权,请联系本人删除。
2.笔者水平有限,文章内容口语化比较严重,且存在个人理解,欢迎大佬们在评论区批评指正。
3.本文面向的是,在自然语言处理和 python 编程两个方面仅仅入门的学习者,且比起讲解,更偏向于笔者的学习思路分享。大佬可能会觉得索然无味,见谅。
另:笔者新人,文风比较生涩,望各位海涵。
目录
五、小结
前情提要:
在实现姓氏分类的过程中,我们使用了词袋模型进行了姓氏字符串的记录和分类工作。那么词袋模型在机器翻译任务中能不能得到使用呢?能,但不多。可能翻译一些比较短的句子能够有一些作用,但是词袋模型有一个非常不好的特性,就是不考虑顺序。这一特性对于顺序要求非常高的机器翻译而言,几乎是致命的缺陷。
因此,想要进行机器翻译,就需要引入一些能够考虑序列关系的结构。而对于实现机器翻译的结构的探寻,一直都是 NLP 领域非常热门的话题。
本次介绍的编码器-解码器模型(seq2seq)就是一个比较经典的模型。当然,在正式开始介绍之前,我也会先介绍一些发展过程中的模型,以便读者对于这一模型的由来有更为清楚的认知。
一、模型介绍
机器翻译是干什么的读者应该非常熟悉了,这里就不进一步进行介绍任务的细节了,直接讲模型。
1.1 词嵌入(embedding)
这一点在上期也有提到。即字符和字符串并不是计算机希望得到的数据,因此需要将其转化为计算机希望看到的数据形式。所以就出现了独热编码。但是独热编码只是简单的表示一个词在词典中的位置,并不能表示词与词之间的联系。因此,需要用某种方式将词和词之间的关系连接起来,于是就有了词向量。而词嵌入就是“独热编码-词向量”之间的映射过程。
不过本文并不是人为规定词向量的映射规则,而是利用机器学习的方法,将词嵌入定义成和线性全连接层类似的一个层。这样就能够通过机器学习的过程对词嵌入过程中的参数进行修改,而不是通过根据经验人为添加规则。这样的好处就是能够让机器自我学习得到合适的词嵌入映射关系,避免由于人工经验的死板对结果产生影响。
Q:在如今的网络时代,每个词的不同语言都能相互翻译,为什么不使用逐词翻译的方式?
A:由于不同语言的语法不同,语句的顺序并不是相同的。况且,由于多义词的存在,单纯的逐字翻译并不能达到非常准确的效果。
1.2 简单 RNN
为了解决序列化的翻译问题,就需要一个能够记录顺序关系的结构,因此,RNN(循环神经网络)出现了。循环神经网络能够通过按照时间步读取输入数,结合隐藏状态,得到输出,同时更新隐藏状态。这样的网络能够在进行读取输入进行分析的同时记录时间步相关的隐藏状态,因此在处理序列相关的任务具有一定的优势。原理如下:
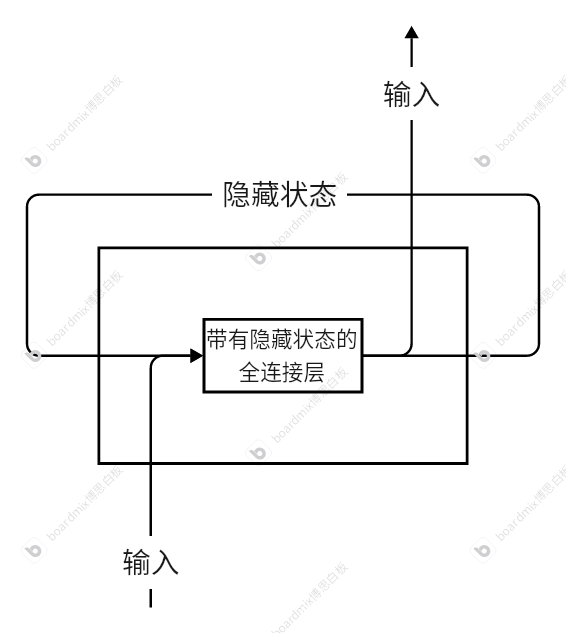
通过输入和上一个时间步的隐藏状态,经过带有隐藏状态的全连接层,最终得到输出和这一个时间步的隐藏状态。这样,就实现了考虑顺序影响的功能。但是这一方法也有一定的局限性,比如,输入和输出必须是相同长度的,且数值不稳定,即便利用梯度截断一类的方式也很难解决。
图中,我们按照时间步的顺序输入了字符串“clas”作为输入,最终得到了输出“lass”。但是,有一点能够明显感受到,那就是,有几个输入,就有几个输出。输入和输出永远的数量对等的。这对于机器翻译来说算是比较致命的缺陷,毕竟谁也不能保证翻译前后是同样的字数。
这就使得简单 RNN 模型在机器翻译这一任务的表现最多算是中规中矩。
1.3 门控循环单元(GRU)
1.2 节中提到了简单 RNN 的两个局限性,门控循环单元就是对于“数值不稳定”这一问题的解决方案。 相比于原本的对于上一时间步隐藏状态的全盘接收,引入门的概念很好的避免了接收不需要的信息的过程。
GRU内部结构除了隐状态之外,使用了两个门控来实现隐藏态的更新:重置门和更新门。
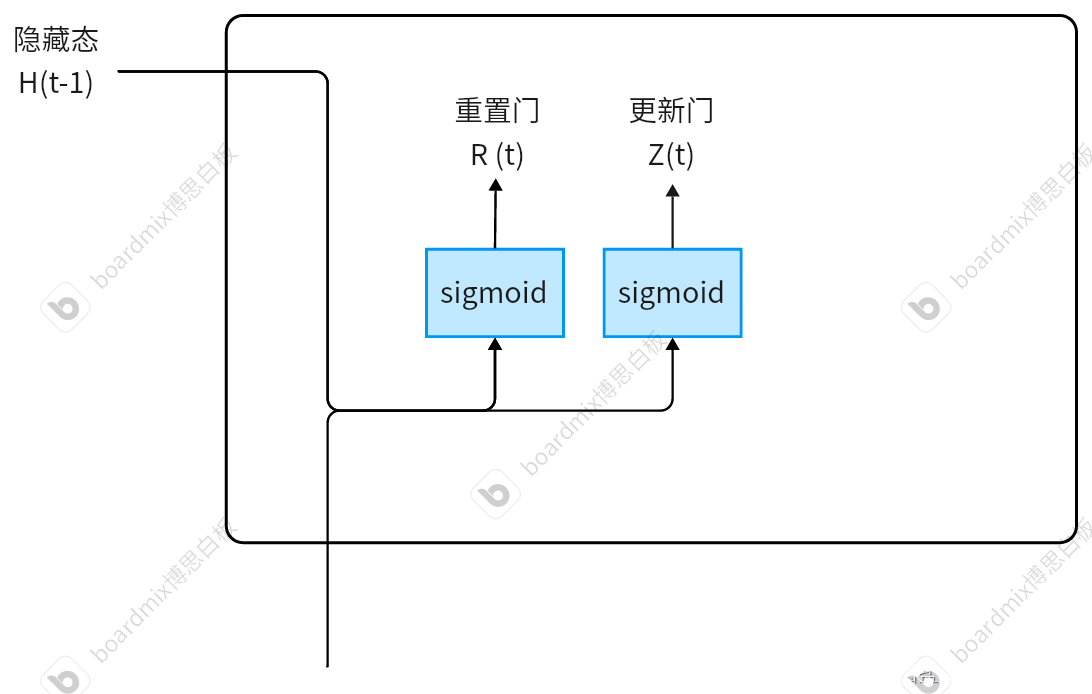
图中sigmoid 表示包含 sigmoid 激活函数的全连接层。
通过 sigmoid 函数将其设计为(0,1)之间的向量,这样便于后续进行凸组合。具体的原理比较复杂,对于单纯的使用者也不需要掌握。只需要知道:
- 重置门的作用是控制哪些上一步的隐状态能够“被记住”。
- 更新门的作用是控制哪些哪些隐状态能够继续传递到下一步。
因此,这一模型的工作思路就出现了:
- 根据输入和上一步的隐状态确定重置门和更新门状态
- 根据重置门状态处理上一步的隐状态,然后和输入得到这一步的候选隐状态
- 候选隐状态通过更新门的处理得到最终传给下一步的隐藏态状态
由于重置门和更新门的存在,数值不稳定的问题能够极大得到缓解,具体的实现方式如下(了解即可,实际使用的代码是 torch 包装好的模型):
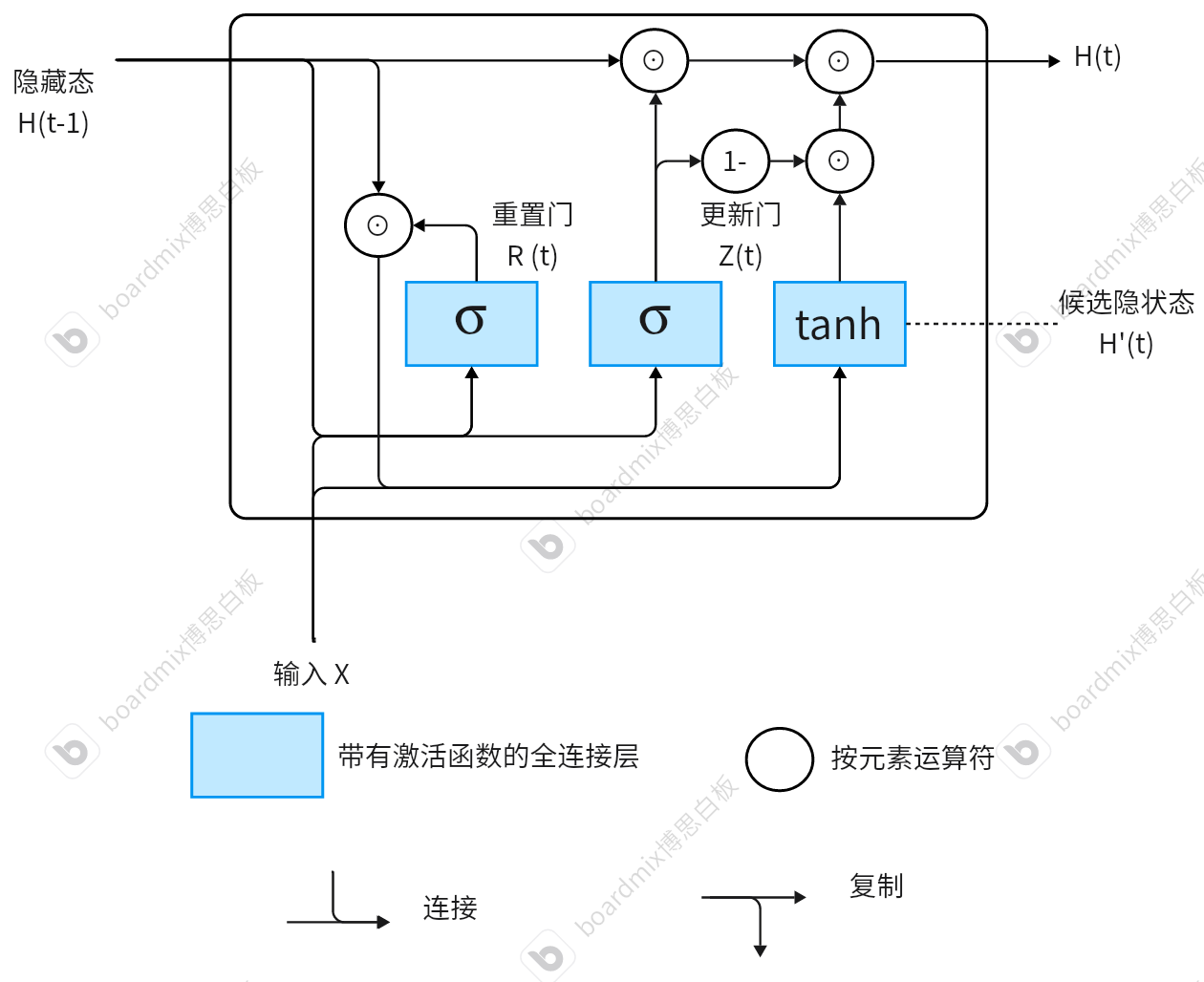
这幅图演示的就是 GRU 的工作原理。大致了解即可,实际代码中使用的是包装好的代码。
另外值得一提的是,代码中的GRU模块支持使用多层的 GRU 模块。这一功能实际上就是通过将 GRU 前一层的输出叠加 dropout 之后作为后一层的输入,进而实现的。这也就是,深度循环神经网络的一种实现方式。同样,了解即可。
1.4 序列到序列学习(Seq2Seq)
这一方式就是为了避免 1.2 节中提到的第二个问题:输入输出长度对等。
不同于简单 RNN 中的输出方式,序列到序列的方式是将循环层分为两个部分:编码器和解码器。输出的方式也不再是一个词输入得到一个词输出,而是先通过编码器得到一个中间状态,再将这个结果输入解码器最终得到翻译的结果,这样就能有效避免长度限制对于结果输出的影响。编码器-解码器的结构示意图如下:
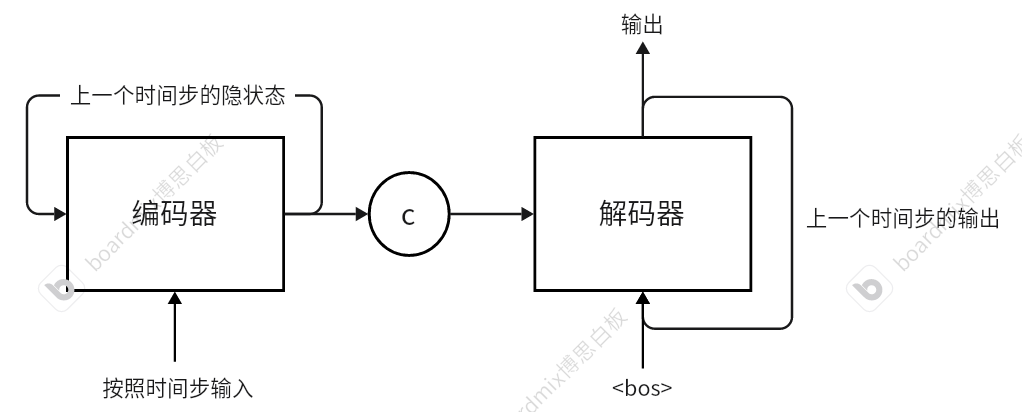
按照时间步将字符串输入编码器得到中间状态 c,然后将中间状态 c 输入解码器,并将<bos>标志作为翻译结果句子的开始(bigen of sentence),最后通过将上一时间步的输入作为下一时间步的输出的方式,按时间步输出最终的结果。
Q:既然是不定长的输入,那么要怎么表示翻译结束呢?句号吗?
A:就像解码器第一个时间步的输入给定<bos>标志一样,我们在创建数据集的时候同样加入了<eos>标志(end of sentence)作为句子的输入,因此,解码器会在输出为<eos>的时候停止循环过程。至于句号,对于 seq2seq 模型而言,也是一个单词。
与之前的内容一样,仅了解原理,明白这个结构的宏观构成,以及这个结构能够胜任机器翻译的原因就可以了。
下面讲一讲编码器和解码器的宏观结构:
1.4.1 编码器
编码器其实是一个相当简单的结构,长话短说,就是一个嵌入层加上一个RNN 层。
嵌入层的结构和功能也就是 1.1 节介绍的词嵌入,这里就不过多介绍了;
RNN 层就是循环神经网络部分,可以是用本文介绍的GRU,同样可以使用双向循环神经网络,或者LSTM 这些进行。不论使用什么,RNN层的目的是和 1.2 节中简单 RNN 一样的,只是后续更为现代的循环伸进网络往往具有老旧的循环神经网络不具有的优势,仅此而已。
ps:其实如果不追求原理的细节了解的化,结构的变化体现在代码中实际上就是 RNN 层这一行调用的 torch.nn 库中的模型不同而已,其他的没什么区别。
1.4.2 解码器
解码器与编码器的不同之处就是,为了进行预测,需要在最后加上线性全连接层,以便于最终的预测工作。当然,也可以为之添加一个注意力机制层,那样就是一共四个部分,嵌入层、注意力机制层、RNN 层和线性全连接层。某种意义上说注意力机制层可以更复杂一些,就像 transformer 那样。由于这里主要是为了讲解编码器-解码器结构,这里就“一切从简”,用一个双层感知机模型完成。具体什么是注意力机制,笔者会在下一篇讲解 transformer 中讲解。
二、数据集介绍
本次实验使用的数据来源为European Parliament Proceedings Parallel Corpus 1996-2011,使用数据集选择为:parallel corpus French-English, 194 MB, 04/1996-11/2011,也就是说,本文进行的是法语和英语的相互翻译。不过数据集中法语部分并没有添加 和
两种音标,因此需要考虑的字符数量会略少一些,具体会在数据读取的部分介绍。
三、实验环境
笔者使用的是MacBook16Pro 搭载 MacOS 系统。由于某些原因,不能装载 N 卡和 CUDA,因此使用 SSH 的方式挂载云端算力进行。以下是一些云端的环境等信息:
GPU:
- CUDA 11.3
编译软件:
- Pycharm
python 包版本(python=3.8):
- d2l 0.17.5
- ipython 8.4.0
- matplotlib 3.5.1
- numpy 1.21.5
- pandas 1.2.4
- Pillow 9.1.1
- sentencepiece 0.1.92
- torch 1.11.0+cu113
- torchinfo 1.8.0
- torchtext 0.6.0
- torchvision 0.12.0+cu113
- tqdm 4.61.2
如果有其他不确定的部分欢迎私信交流。
四、代码部分
前面已经介绍了原理,也配置好了环境,那么开始编程!
4.1 环境部分
引入各种需要的包:
import collections
import os
import io
import math
import torch
from torch import nn
import torch.nn.functional as F
import torchtext.vocab as Vocab
import torch.utils.data as Data
import time # 检查错误的时候使用
import sys
from d2l import torch as d2l
PAD, BOS, EOS = '<pad>', '<bos>', '<eos>'
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"version: torch=={torch.__version__}", "\ndevice available:", device, "\n") # 检测 torch 版本以及 GPU 是否可用最后的打印就是观察一下版本以及 gpu 是否可用。由于挂载了云算力,这一步的结果当然是肯定的。
version: torch==1.11.0+cu113
device available: cuda 这里就是基本所有需要用到的包的内容了。
4.2 数据读取与数据集的建立
这一部分和笔者上一篇文章中非常类似,就是处理字符串到计算机喜欢的格式,需要建立语言的词汇表,将原本的字符串转化为「索引」的序列。和原本不同的地方在于,由于处理的内容是句子而不是词汇,我们还需要考虑分词的问题,即如何将原本连续的字符串变为合理分割之后的单词序列。
对于这一问题,笔者使用的是 Python 中的正则表达式进行匹配修改,最终将格式规范为每个单词和标点之间只留下一个空格,这样就能够利用split函数的特点,用空格将字符串分解为单词和合法的标点,做法如下:
def preprocess_text(text):
"""
用于将原本标点风格随意的文本 转化为 格式化的文本
即:将标点也作为一个「标记」进行处理
Args:
text (str): 需要处理的字符串,如:本次任务中的句子
Returns:
(str): 格式化处理之后的字符串
"""
text = text.lower()
# 将原本的 标点符号 格式变化为 空格-标点符号-空格 的形式,方便后续的分割
text = re.sub(r"([.,!?])", r" \1 ", text)
# 将原本非法的分隔符以及连续的空格转变为一个空格
text = re.sub(r"[^a-z.,!?'çàéèùœ]+", r" ", text)
# print(text)
# time.sleep(1)
return text这里一定要注意的是,由于使用的是法语-英语的数据集,在使用的时候要注意,除了小写字母之外,还需要考虑法语输入法特有的 6 个字符。如果不添加的话,生成的数据集中,由于法语部分字符会被当成非法字符处理,原本的单词也可能会因此变成两个单词,与原本的完全不一致。因此,这里将特殊的 6 个字符也加入进去。
然后就是 split 分割。分割之后,为了保证训练模型的完备性,这里需要在简单分解之后,进行补全操作,也就是加上句尾标志<eos>以及用于填充到对应长度的空标志<pad>。分割的部分是写在外面函数的,这里导入的是分割好的数据。
def process_one_seq(seq_tokens, all_tokens, all_seqs, max_seq_len):
"""
根据给定的一个「句子」更新「词汇表」和「句子列表」
「词汇表」用于「索引」和「标记」之间的转换,以便机器能够训练的同时人能够看懂
「句子列表」用于后续的数据集生成
- 将一个序列中所有的词记录在all_tokens中以便之后构造词典,然后在该序列后面添加PAD直到序列
- 长度变为max_seq_len,然后将序列保存在all_seqs中
Args:
seq_tokens (list): 记载了这一句子所有「标记」的列表
all_tokens (list): 记载了已经读取的 所有「标记」的列表
all_seqs (list): 记载了已经读取的 所有句子对应「标记」列表 的列表
max_seq_len (int): 句子的最大长度,也是规范化之后的标准长度
"""
all_tokens.extend(seq_tokens)
seq_tokens += [EOS] + [PAD] * (max_seq_len - len(seq_tokens) - 1) # 保证最终保存的 seq 符合规范
all_seqs.append(seq_tokens)Vocab 构建,这些上篇文章介绍过了,因此这次使用包装好的 Vocab 以节约时间。返回构建好的词汇表和句子转化成对应的索引之后的数据集。
def build_data(all_tokens, all_seqs):
"""
构建数据集
使用所有的词来构造词典,并将所有序列中的词变换为词索引后构造Tensor
:param all_tokens (list): 记载了已经读取的 所有「标记」的列表
:param all_seqs (list): 记载了已经读取的 所有句子对应「标记」列表 的列表
:return: (Vocab, torch.Tensor): 「词汇表」和 「标记」化之后的句子
"""
vocab = Vocab.Vocab(collections.Counter(all_tokens),
specials=[PAD, BOS, EOS])
indices = [[vocab.stoi[w] for w in seq] for seq in all_seqs]
return vocab, torch.tensor(indices)然后把上面三个函数打包起来,作为整个从读取数据到生成数据集的过程。
def read_data(max_seq_len, fr_pth, en_pth):
"""
读取数据并生成对应的 数据集 和「词汇表」
:param max_seq_len (int): 最大句长
:param fr_pth (str): 法语文本库路径
:param en_pth (str): 英文文本库路径
:return: (Vocab, Vocab, TensorDataset): 英文词汇表,法语词汇表,训练数据集
"""
in_tokens, out_tokens, in_seqs, out_seqs = [], [], [], []
with io.open(en_pth) as f:
en_lines = f.readlines()
with io.open(fr_pth) as f:
fr_lines = f.readlines()
print("Loading data from files...")
for i in tqdm(range(min(len(en_lines), len(fr_lines)))):
# 处理读取的数据格式
in_seq = preprocess_text(fr_lines[i].rstrip())
out_seq = preprocess_text(en_lines[i].rstrip())
in_seq_tokens, out_seq_tokens = in_seq.split(' '), out_seq.split(' ')
if max(len(in_seq_tokens), len(out_seq_tokens)) > max_seq_len - 1:
continue # 如果加上EOS后长于max_seq_len,则忽略掉此样本
# 处理文本数据,同时记录构建「词汇表」和数据集所需要的列表
process_one_seq(in_seq_tokens, in_tokens, in_seqs, max_seq_len)
process_one_seq(out_seq_tokens, out_tokens, out_seqs, max_seq_len)
# 利用处理过程中记录的数据创建数据库和「词汇表」
in_vocab, in_data = build_data(in_tokens, in_seqs)
out_vocab, out_data = build_data(out_tokens, out_seqs)
return in_vocab, out_vocab, Data.TensorDataset(in_data, out_data)这里设置了一个最大句长的限制,毕竟算力有限,数据集又非常庞大,这里只能为了能够训练出一定的结果,做出一点小小的牺牲。最终笔者选择的最大句长最终设置为 10.
在读取数据之后我们得到了,一个英文词汇表,一个法语词汇表,和一个「索引」化之后的数据集。
然后就可以先把数据集读进来试试了。
# 数据对应的路径
en_pth = "../data13/fr-en/europarl-v7.fr-en.en"
fr_pth = "../data13/fr-en/europarl-v7.fr-en.fr"
# 数据集部分
#
# 数据集中「语句」的最大长度
max_seq_len = 10
# 数据集和两种语言的词汇表的生成
in_vocab, out_vocab, dataset = read_data(max_seq_len, fr_pth, en_pth)
# 查看数据集中第 0 个样本的状态
# 这样有助于理解数据集的工作内容
print(dataset[0])
结果显示读取和转化成功:
Loading data from files...
100%|██████████| 2007723/2007723 [01:15<00:00, 26544.07it/s]
(tensor([260, 7, 8, 151, 2, 0, 0, 0, 0, 0]), tensor([253, 12, 5, 146, 2, 0, 0, 0, 0, 0]))数据搞定了,下面就要看看模型部分了。
4.2 编码器(Encoder)
编码器,按照原理介绍部分构建需要的内容,即:一个嵌入层,一个 RNN 层(选择用 GRU
实现)
class Encoder(nn.Module):
"""
编码器 类
对初始序列进行编码,记录序列的特征信息
- 由于使用了包装好的模型,实际上这里只需要了解网络最基本的构成即可:
-
- embedding 层,恰如其名,进行词嵌入的工作。
- 将原本没有实际意义的向量,利用某种映射关系,映射到可能具有一定联系的向量空间中
- 你可嫩个会有疑惑:这个工作用 nn.Linear 不是也可以实现吗?
- 确实。
- 但是由于笔者比较懒,不想再和上次形式分类任务一样写一个 one-hot 编码器了
- 使用 nn.Embedding,能够直接传入「索引」组成的序列,简单快捷
-
- rnn 层,也就是编码器能够处理序列的最基本结构,循环神经网络
- nn.GRU 就是一个非常好用的循环神经网络结构
-
- 多层 GRU 实际上是
- 将上一层 GRU 的 h 输出作为下一层的 h 输入,
- 将上一层 GRU 的 h 输出乘上 dropout,作为下一层的 x 输入
"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
drop_prob=0, **kwargs):
super(Encoder, self).__init__(**kwargs)
# 词嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
# GRU
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=drop_prob)
def forward(self, inputs, state):
# 输入形状是(批量大小, 时间步数)。将输出互换样本维和时间步维
# 这是由于 nn.GRU 要求的输入输出形状为 (seq_len, batch, input_size)
embedding = self.embedding(inputs.long()).permute(1, 0, 2)
return self.rnn(embedding, state)
def begin_state(self):
# 定义一个初始状态为 None,其实就是使用 GRU 的默认 h_0
return None其实就是简单的叠加即可。注意在 forward 的过程中是否有需要转换维度顺序的。不同的模型由于需求不同,会按照最方便的任务进行维度的定义,在其他任务的情况下可能需要转换前两个维度(例如本次任务),这就需要我们足够了解模型每个层的实际用法。
4.3 解码器(Decoder)
解码器和编码器在逻辑上多的地方就是注意力机制层和线性全连接层。虽然本次任务使用的注意力机制层很简单,笔者还是将其独立出来。
def attention_model(input_size, attention_size):
# 定义注意力机制模块
# 根据原理可以轻易的知道,其实注意力机制就是一个矩阵乘法,更细致一些就是偏置为 0 的线性变换
# 因此可以用下面的方式进行表示
model = nn.Sequential(nn.Linear(input_size, attention_size, bias=False),
nn.Tanh(),
nn.Linear(attention_size, 1, bias=False))
return model
def attention_forward(model, enc_states, dec_state):
"""
enc_states: (时间步数, 批量大小, 隐藏单元个数)
dec_state: (批量大小, 隐藏单元个数)
"""
# 将解码器隐藏状态广播到和编码器隐藏状态形状相同后进行连结
dec_states = dec_state.unsqueeze(dim=0).expand_as(enc_states)
enc_and_dec_states = torch.cat((enc_states, dec_states), dim=2)
e = model(enc_and_dec_states) # 形状为(时间步数, 批量大小, 1)
alpha = F.softmax(e, dim=0) # 在时间步维度做softmax运算
return (alpha * enc_states).sum(dim=0) # 返回背景变量然后就是和编码器一样的简单叠加:
class Decoder(nn.Module):
"""
解码器 类
- 某种意义上说,就是编码器中间加上注意力机制模块,
- 以及由于引入注意力机制模块需要更改部分参数
"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
attention_size, drop_prob=0):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.attention = attention_model(2*num_hiddens, attention_size)
# GRU的输入包含attention输出的c和实际输入, 所以尺寸是 num_hiddens+embed_size
self.rnn = nn.GRU(num_hiddens + embed_size, num_hiddens,
num_layers, dropout=drop_prob)
self.out = nn.Linear(num_hiddens, vocab_size)
def forward(self, cur_input, state, enc_states):
"""
cur_input 形状为: (batch, )
state 形状为: (num_layers, batch, num_hiddens)
"""
# 使用注意力机制计算背景向量
c = attention_forward(self.attention, enc_states, state[-1])
# 将嵌入后的输入和背景向量在特征维连结, (批量大小, num_hiddens+embed_size)
input_and_c = torch.cat((self.embedding(cur_input), c), dim=1)
# 为输入和背景向量的连结增加时间步维,时间步个数为1
output, state = self.rnn(input_and_c.unsqueeze(0), state)
# 移除时间步维,输出形状为(批量大小, 输出词典大小)
output = self.out(output).squeeze(dim=0)
return output, state
def begin_state(self, enc_state):
# 直接将编码器最终时间步的隐藏状态作为解码器的初始隐藏状态
return enc_state
编码器和解码器构建完毕,就可以开始训练了。
4.4 训练过程
由于词汇表的存在,编码器-解码器结构的训练过程有点类似于很多个分类任务的叠加:对于每个单词的预测结果,都存在一个实际的对应的标签。例如,输入序列["Ils", "regardent", ".", <eos>, <pad>, <pad>]就有对应的等长的标签序列 ["they", "are", "watching", ".", <eos>, <pad>]。因此,在计算的过程中,最底层的损失函数逻辑使用交叉熵损失函数即可。
我们在训练的过程中会要求一定要将输入和输出完整遍历出来,所以哪怕输入和输出都已经到了<pad>也就是空标识符,也必须继续循环,直到设定的最大长长度。
训练的过程和实际预测的过过程是一样的,由数据输入编码器先计算中间状态c,再将中间状态输入解码器然后循环输出结果。不过在训练阶段,我们并不会直接将预测结果作为上一个解码器时间步的输出,而是直接使用上一个时间步的标签,这叫强制教学。这样的好处就是避免一些容易不收敛的情况,以及增加一定的训练效率。
def batch_loss(encoder, decoder, X, Y, loss, out_vocab):
"""
训练过程中计算损失的函数
:param encoder: 编码器
:param decoder: 解码器
:param X: 输入
:param Y: 输出
:param loss: 损失函数
:param out_vocab: 翻译任务目标语言的词汇表
:return: 损失大小
"""
# 读取数据集大小
batch_size = X.shape[0]
# 初始化编码器隐藏状态
enc_state = encoder.begin_state()
# 编码
enc_outputs, enc_state = encoder(X, enc_state)
# 初始化解码器的隐藏状态
dec_state = decoder.begin_state(enc_state)
# 解码器在最初时间步的输入是BOS
dec_input = torch.tensor([out_vocab.stoi[BOS]] * batch_size).to(device)
# 我们将使用掩码变量mask来忽略掉标签为填充项PAD的损失, 初始全1
mask, num_not_pad_tokens = torch.ones(batch_size,), 0
l = torch.tensor([0.0])
# 根据需在对应的设备上进行运算
mask = mask.to(device)
l = l.to(device)
for y in Y.permute(1,0): # Y shape: (batch, seq_len)
dec_output, dec_state = decoder(dec_input, dec_state, enc_outputs)
l = l + (mask * loss(dec_output, y)).sum()
dec_input = y # 使用强制教学
num_not_pad_tokens += mask.sum().item()
# EOS后面全是PAD. 下面一行保证一旦遇到EOS接下来的循环中mask就一直是0
mask = mask * (y != out_vocab.stoi[EOS]).float()
return l / num_not_pad_tokens
def train(encoder, decoder, dataset, lr, batch_size, num_epochs, out_vocab):
"""
训练模型的过程
:param encoder: 编码器
:param decoder: 解码器
:param dataset: 数据集
:param lr: 学习率
:param batch_size: 批次大小
:param num_epochs: 训练轮数
:param out_vocab: 目标语言词汇表
"""
# 处理设备问题
encoder.to(device)
decoder.to(device)
# 设置对应优化器
enc_optimizer = torch.optim.Adam(encoder.parameters(), lr=lr)
dec_optimizer = torch.optim.Adam(decoder.parameters(), lr=lr)
# 设置损失函数
loss = nn.CrossEntropyLoss(reduction='none')
for epoch in range(num_epochs):
# 数据集包装为数据加载器
data_iter = Data.DataLoader(dataset, batch_size, shuffle=True)
l_sum = 0.0
# 包装为进度条
tqdm_bar = tqdm(data_iter,
desc=f'epoch {epoch + 1}/{num_epochs}',
total=len(data_iter),
position=0,
leave=True,
colour='green'
)
# 打开训练模式
encoder.train()
decoder.train()
for i, data in enumerate(tqdm_bar):
# 处理训练数据(解包+分配设备)
X, Y = data
X = X.to(device)
Y = Y.to(device)
# 通用训练过程---
# 梯度清零
enc_optimizer.zero_grad()
dec_optimizer.zero_grad()
# 计算损失
l = batch_loss(encoder, decoder, X, Y, loss, out_vocab)
# 反向传播
l.backward()
# 优化器迭代
enc_optimizer.step()
dec_optimizer.step()
# 计算损失用于显示
l_sum += l.item()
tqdm_bar.set_postfix(loss=f"{l_sum / (i + 1):.3f}")
# time.sleep(0.1)其实真正的训练过程的循环多少大同小异,只需要按照对应的模型改动即可。总体的几个步骤是一致的。(至少对于 MLP 为基础架构的网络是这样)
之后就可以进行训练了:
# 定义模型相关的参数
# 词嵌入之后向量空间维数,隐藏层 h 特征大小,GRU 层数
embed_size, num_hiddens, num_layers = 64, 64, 5
attention_size, drop_prob, lr, batch_size, num_epochs = 50, 0.3, 2e-4, 64, 50
#按照参数定义模型
encoder = Encoder(len(in_vocab), embed_size, num_hiddens, num_layers,
drop_prob)
decoder = Decoder(len(out_vocab), embed_size, num_hiddens, num_layers,
attention_size, drop_prob)
# 开始训练
train(encoder, decoder, dataset, lr, batch_size, num_epochs, out_vocab)
# 保存模型
def save_model(model, dirpath):
"""
保存模型到对应路径
路径不存在则会先创建路径
:param model: 需要保存的 nn.Moudle 模型
:param dirpath: 保存路径
"""
if not os.path.exists(dirpath):
fd = os.open(dirpath, os.O_CREAT)
os.close(fd)
torch.save(model, dirpath)
save_model(encoder, "model/encoder.pt")
save_model(decoder, "model/decoder.pt")训练过程就只有显示了训练的损失大小的进度条,大概是这样:
epoch 1/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.21it/s, loss=4.995]
epoch 2/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.72it/s, loss=3.853]
epoch 3/50: 100%|██████████| 1637/1637 [00:48<00:00, 33.84it/s, loss=3.490]
epoch 4/50: 100%|██████████| 1637/1637 [00:48<00:00, 33.85it/s, loss=3.289]
epoch 5/50: 100%|██████████| 1637/1637 [00:48<00:00, 34.01it/s, loss=3.147]
epoch 6/50: 100%|██████████| 1637/1637 [00:48<00:00, 33.72it/s, loss=3.033]
epoch 7/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.16it/s, loss=2.928]
epoch 8/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.40it/s, loss=2.840]
epoch 9/50: 100%|██████████| 1637/1637 [00:46<00:00, 34.86it/s, loss=2.762]
epoch 10/50: 100%|██████████| 1637/1637 [00:46<00:00, 34.90it/s, loss=2.694]
epoch 11/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.44it/s, loss=2.634]
epoch 12/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.82it/s, loss=2.580]
epoch 13/50: 100%|██████████| 1637/1637 [00:46<00:00, 35.20it/s, loss=2.532]
epoch 14/50: 100%|██████████| 1637/1637 [00:46<00:00, 35.06it/s, loss=2.488]
epoch 15/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.24it/s, loss=2.449]
epoch 16/50: 100%|██████████| 1637/1637 [00:48<00:00, 34.08it/s, loss=2.412]
epoch 17/50: 100%|██████████| 1637/1637 [00:48<00:00, 34.06it/s, loss=2.380]
epoch 18/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.41it/s, loss=2.350]
epoch 19/50: 100%|██████████| 1637/1637 [00:48<00:00, 33.85it/s, loss=2.320]
epoch 20/50: 100%|██████████| 1637/1637 [00:48<00:00, 33.74it/s, loss=2.294]
epoch 21/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.22it/s, loss=2.268]
epoch 22/50: 100%|██████████| 1637/1637 [00:48<00:00, 34.08it/s, loss=2.246]
epoch 23/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.45it/s, loss=2.224]
epoch 24/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.30it/s, loss=2.201]
epoch 25/50: 100%|██████████| 1637/1637 [00:49<00:00, 33.35it/s, loss=2.183]
epoch 26/50: 100%|██████████| 1637/1637 [00:49<00:00, 32.79it/s, loss=2.162]
epoch 27/50: 100%|██████████| 1637/1637 [00:50<00:00, 32.11it/s, loss=2.144]
epoch 28/50: 100%|██████████| 1637/1637 [00:49<00:00, 32.95it/s, loss=2.126]
epoch 29/50: 100%|██████████| 1637/1637 [00:50<00:00, 32.43it/s, loss=2.110]
epoch 30/50: 100%|██████████| 1637/1637 [00:48<00:00, 33.88it/s, loss=2.094]
epoch 31/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.68it/s, loss=2.078]
epoch 32/50: 100%|██████████| 1637/1637 [00:46<00:00, 35.08it/s, loss=2.063]
epoch 33/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.62it/s, loss=2.048]
epoch 34/50: 100%|██████████| 1637/1637 [00:48<00:00, 34.03it/s, loss=2.035]
epoch 35/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.61it/s, loss=2.021]
epoch 36/50: 100%|██████████| 1637/1637 [00:46<00:00, 35.43it/s, loss=2.008]
epoch 37/50: 100%|██████████| 1637/1637 [00:46<00:00, 35.43it/s, loss=1.995]
epoch 38/50: 100%|██████████| 1637/1637 [00:49<00:00, 33.11it/s, loss=1.983]
epoch 39/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.56it/s, loss=1.972]
epoch 40/50: 100%|██████████| 1637/1637 [00:48<00:00, 33.55it/s, loss=1.960]
epoch 41/50: 100%|██████████| 1637/1637 [00:46<00:00, 34.99it/s, loss=1.948]
epoch 42/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.51it/s, loss=1.936]
epoch 43/50: 100%|██████████| 1637/1637 [00:46<00:00, 35.04it/s, loss=1.927]
epoch 44/50: 100%|██████████| 1637/1637 [00:46<00:00, 34.88it/s, loss=1.916]
epoch 45/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.66it/s, loss=1.906]
epoch 46/50: 100%|██████████| 1637/1637 [00:46<00:00, 35.24it/s, loss=1.895]
epoch 47/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.76it/s, loss=1.884]
epoch 48/50: 100%|██████████| 1637/1637 [00:46<00:00, 34.86it/s, loss=1.876]
epoch 49/50: 100%|██████████| 1637/1637 [00:47<00:00, 34.64it/s, loss=1.866]
epoch 50/50: 100%|██████████| 1637/1637 [00:46<00:00, 35.26it/s, loss=1.857]由于时间关系,这里没有进行非常细致的参数调节,因此结果可能不会特别好。感兴趣的读者可以调节参数部分的参数试试,看看训练的效果会不会更好一些。
4.5 结果检验
作为一个翻译模型,最重要的就是翻译的过程了。因此,需要一个函数能够利用训练的模型进行翻译结果的预测。原理很简单,就是数据格式处理之后,输入模型进行预测,最终按照词汇表进行结果的打印,因此就直接看代码吧。
def translate(encoder, decoder, input_seq, max_seq_len, in_vocab, out_vocab):
"""
翻译函数
将法语翻译成英语
:param encoder: 编码器
:param decoder: 解码器
:param input_seq: 需要翻译的法语句子
:param max_seq_len: 最大句长
:param in_vocab: 法语词汇表
:param out_vocab: 英语词汇表
:return: 翻译结果
"""
# 禁用 dropout,否则结果会飘忽不定
encoder.eval()
decoder.eval()
# 输入文本格式化
in_tokens = input_seq.split(' ')
in_tokens += [EOS] + [PAD] * (max_seq_len - len(in_tokens) - 1)
# 输入文本「索引」化
enc_input = torch.tensor([[in_vocab.stoi[tk] for tk in in_tokens]]) # batch=1
# 用编码器-解码器进行翻译
enc_state = encoder.begin_state()
enc_output, enc_state = encoder(enc_input, enc_state)
dec_input = torch.tensor([out_vocab.stoi[BOS]])
dec_state = decoder.begin_state(enc_state)
# 结果输出部分
output_tokens = []
for _ in range(max_seq_len):
dec_output, dec_state = decoder(dec_input, dec_state, enc_output)
pred = dec_output.argmax(dim=1)
pred_token = out_vocab.itos[int(pred.item())]
if pred_token == EOS: # 当任一时间步搜索出EOS时,输出序列即完成
break
else:
output_tokens.append(pred_token)
dec_input = pred
return output_tokens之后就可以对一些语句进行翻译了:
# 预测不需要 gpu,这里转变回来
encoder.to("cpu")
decoder.to("cpu")
# 查看翻译结果
input_seq = "reprise de la session"
target_seq = "resumption of the session"
print("Translating...")
print("Original Seq :", input_seq)
print("Target Seq :", target_seq)
print("Translated Seq:", ' '.join(translate(encoder, decoder, input_seq, max_seq_len, in_vocab, out_vocab)))
input_seq = "je le félicite de son excellent rapport ."
target_seq = "i congratulate him on his excellent report ."
print("Translating...")
print("Original Seq :", input_seq)
print("Target Seq :", target_seq)
print("Translated Seq:", ' '.join(translate(encoder, decoder, input_seq, max_seq_len, in_vocab, out_vocab)))
翻译的结果如下:
Translating...
Original Seq : reprise de la session
Target Seq : resumption of the session
Translated Seq: resumption of the session
Translating...
Original Seq : je le félicite de son excellent rapport .
Target Seq : i congratulate him on his excellent report .
Translated Seq: i congratulate the rapporteur for the rapporteur . 可以看到,对于较短的句子,预测结果还是比较可观的;但是对于长一些的句子,效果并不是很理想。这是由于解码器的工作方式为将上一个时间步的输出作为下一个时间步的输入,这就导致”一步错步步错“现象的发生影响最终的结果。
4.6 BLEU 评分
直接观察翻译结果固然有效,但是,比起这样观察得到的结果,我们需要一个能够为翻译结果评价的分数标准。因此,有人设计了 BLEU 评分标准,能够对不一定等长的两个句子之间的相似度进行评分。
实现方式按照原理进行编写即可:
def bleu(pred_tokens, label_tokens, k):
"""
bleu 评分标准
:param pred_tokens: 预测序列
:param label_tokens: 标签序列
:param k: 最长子序列长度
:return: 最终的 blue 评分标准下的评分
"""
# 预测序列和原本序列的长度
len_pred, len_label = len(pred_tokens), len(label_tokens)
# 原理中除了连乘的部分
score = math.exp(min(0, 1 - len_label / len_pred))
# 连乘部分
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[''.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[''.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[''.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
def score(input_seq, label_seq, k, encoder, decoder, in_vocab, out_vocab, max_seq_len):
"""
评分函数(包装后的 bleu 评分标准)
:param input_seq: 输入语句
:param label_seq: 标签语句
:param k: bleu 标准中最长子序列长度
:param encoder: 编码器
:param decoder: 解码器
:param in_vocab: 输入语言词汇表
:param out_vocab: 目标语言词汇表
:param max_seq_len: 最大句长
"""
# 计算翻译结果
pred_tokens = translate(encoder, decoder, input_seq, max_seq_len, in_vocab, out_vocab)
# 标签语句转化为标签序列
label_tokens = label_seq.split(' ')
print("\nOriginal Seq:", input_seq)
print("Label Seq :", label_seq)
print("Scoring...")
print('bleu %.3f, predict: %s' % (bleu(pred_tokens, label_tokens, k),
' '.join(pred_tokens)))下面利用评分为前面两次的翻译结果打分:
score(input_seq="je le félicite de son excellent rapport .",
label_seq="i congratulate him on his excellent report .",
k=2,
encoder=encoder,
decoder=decoder,
in_vocab=in_vocab,
out_vocab=out_vocab,
max_seq_len=max_seq_len
)
score(input_seq='reprise de la session',
label_seq='resumption of the session',
k=2,
encoder=encoder,
decoder=decoder,
in_vocab=in_vocab,
out_vocab=out_vocab,
max_seq_len=max_seq_len
)
最终得到下面的结果。
Original Seq: je le félicite de son excellent rapport .
Label Seq : i congratulate him on his excellent report .
Scoring...
bleu 0.343, predict: i congratulate the rapporteur for the rapporteur .
Original Seq: reprise de la session
Label Seq : resumption of the session
Scoring...
bleu 1.000, predict: resumption of the session可以看到,完全正确的结果得到了 1 的评分,也就是满分,另一个就略低。
五、小结
首先还是非常感谢各位能够读到这里的!
本文主要进行的是对于一个课程给定的代码进行微调以及讲解的过程,大部分代码并非笔者原创,对于这一点笔者还是比较愧疚的。
由于篇幅较大,读起来可能会费些时间,但是某些地方可能还是没有讲到小白的痛点上,依然看不懂的地方欢迎评论区或者私信留言。
如果遇到了文中哪些地方阅读有困难,觉得讲述的不够清晰的,或者觉得笔者哪里讲的存在问题的,欢迎在评论区讨论或批评指正,也欢迎私信交流讨论。笔者在这里谢过各位了!

















 1660
1660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









