







1.过拟合:过拟合是指为了得到一致假设而使假设变得过度严格。避免过拟合是分类器设计中的一个核心任务。通常采用增大数据量和测试样本集的方法对分类器性能进行评价。过分学习了训练集的特征。
2对于训练集何测试集的选取有:自留法,交叉检验法,自助法
评估方法
- 留出法:直接将数据集D划分为两个互斥的集合,其中一个是训练集S,另一个是测试机(准确说是验证集)T。训练集和验证集的划分要尽可能保持数据分布一致。常用作法将数据集的2/3 ~ 4/5用作训练集,其余的用作验证集。由于存在很多种把数据集进行划分的方法,所以,通常进行多次数据集的划分。最后返回多次划分集合结果的平均值。例如进行了100次集合数据的划分,则求100次结果的平均值。
- 交叉验证法(cross validation):将数据集D分成k个子集,互相独立,保证每个子集的数据分布一致。之后,每次使用K-1个子集合并作为训练集,剩下的一个子集作为验证集,这样可以得到k个训练集/验证集。从而进行k次训练和测试。最终返回k个测试结果的平均值。通常k为10,成为10折交叉验证。k也可以取5,20等。同样,对数据集进行k次划分有很多种方法,通常进行p次k折交叉验证,最后求均值。最常见的为10次10折交叉验证。当k=m(数据条数)时,叫做留一法。这样结果效果好,但计算量太大。
- 自助法(bootstrapping):无论是留出法还是交叉验证法,都要留出一部分作为验证数据,不能把所有数据用作训练,从而降低了训练集数据规模。自助法可以避免此种情况发生。给定m个样本的数据集D,我们对它进行采样产生数据集D’:每次随机从D中挑选一个样本,将其拷贝到D’中,然后将样本放回到D中,从复m次。通过自助法,D中36.8%的样本未出现在D’中。我们将D’当做训练集,D\D’当做验证集。自助法在数据集较小,难以有效划分时很有用。自助法产生的数据集改变了初始数据集的分布,会引入偏差。因此,在初始数据集足够时,留出法和交叉验证法更常用一些。
- 调参及最终模型:在模型选择完成后,学习算法和参数配置已选定,此时应用数据集D重新训练模型,将结果作为最终结果。
3均方误差: 在回归问题中,y1,y2实际结果和预测的结果进行对比
4
深度探讨机器学习中的ROC和PR曲线
性能度量(performance measure)
在对学习器的泛化能力进行评估是模型泛化的能力,即要用到机器学习的性能度量,不同的性能度量往往会导致不同的评判结果,这意味着模型的好坏事相对的,什么样的模型是好的,不仅取决于算法和数据,还决定于任务的需求。
最常见的的分类中所用的度量是:accuracy(准确度),error rate
上面两种度量方法非常的常用,但是有时并不能满足任务的要求,其准确度将每个类看得同等的重要,因此它可能不适合用来分析不平衡的数据集,不平衡的数据集即正类样本远远小于负类的样本,但是我们用对正类的样本比较关心,这样准确度就不适合这种度量了,因此引入了下面的几种度量方法。
假定下面一个例子,假定在10000个样本中有100个正样本,其余为负样本,其在分类器下的混淆矩阵(confusion matrix)为:

则,我们定义:
1. TN / True Negative: case was negative and predicted negative
2. TP / True Positive: case was positive and predicted positive
3. FN / False Negative: case was positive but predicted negative
4. FP / False Positive: case was negative but predicted positive
则定义一下度量:
真正率(true positive rate,TPR)或灵敏度(sensitivity),定义为被模型正确预测的正样本的比例:
真负率(true negative rate,TFR)或特指度(specificity),定义为被模型正确预测的负样本的比例:
同理,假正率(false positive rate,FPR)
假负率(flase negative rate,FNR)
重要的两个度量:
precision(精度),其与accuracy感觉中文翻译一致,周志华老师的书中称为:查准率:
recall(召回率),周志华老师的书中称为查全率,其又与真正率一个公式:
精度是确定分类器中断言为正样本的部分其实际中属于正样本的比例,精度越高则假的正例就越低,召回率则是被分类器正确预测的正样本的比例。两者是一对矛盾的度量,其可以合并成令一个度量,F1度量:
如果对于precision和recall的重视不同,则一般的形式:
可以从公式中看到 β=1 则退化成F1, β>1 则recall有更大影响,反之则precision更多影响。
维基百科中一个非常好的关于两者之间的例子:

有了上面的知识,就可以理解ROC,和PRC了。
ROC and PRC
ROC(receiver operating characteristic)接受者操作特征,其显示的是分类器的真正率和假正率之间的关系,如下图所示:
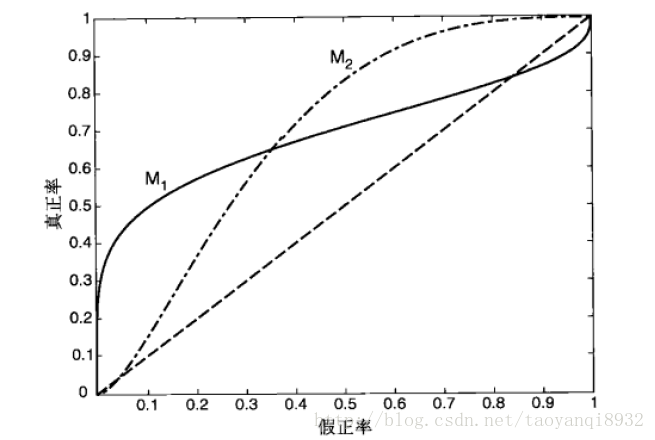
ROC曲线有助于比较不同分类器的相对性能,当FPR小于0.36时M1浩宇M2,而大于0.36是M2较好。
ROC曲线小猫的面积为AUC(area under curve),其面积越大则分类的性能越好,理想的分类器auc=1。
PR(precision recall)曲线表现的是precision和recall之间的关系,如图所示:

如何选择ROC,PR
下面节选自:What is the difference between a ROC curve and a precision-recall curve? When should I use each?
Particularly, if true negative is not much valuable to the problem, or negative examples are abundant. Then, PR-curve is typically more appropriate. For example, if the class is highly imbalanced and positive samples are very rare, then use PR-curve. One example may be fraud detection, where non-fraud sample may be 10000 and fraud sample may be below 100.
In other cases, ROC curve will be more helpful.
其说明,如果是不平衡类,正样本的数目非常的稀有,而且很重要,比如说在诈骗交易的检测中,大部分的交易都是正常的,但是少量的非正常交易确很重要。
Let’s take an example of fraud detection problem where there are 100 frauds out of 2 million samples.
Algorithm 1: 90 relevant out of 100 identified
Algorithm 2: 90 relevant out of 1000 identified
Evidently, algorithm 1 is more preferable because it identified less number of false positive.
In the context of ROC curve,
Algorithm 1: TPR=90/100=0.9, FPR= 10/1,999,900=0.00000500025
Algorithm 2: TPR=90/100=0.9, FPR=910/1,999,900=0.00045502275
The FPR difference is 0.0004500225
For PR, Curve
Algorithm 1: precision=0.9, recall=0.9
Algorithm 2: Precision=90/1000=0.09, recall= 0.9
Precision difference= 0.81
可以看到在正样本非常少的情况下,PR表现的效果会更好。
如何绘制ROC曲线
为了绘制ROC曲线,则分类器应该能输出连续的值,比如在逻辑回归分类器中,其以概率的形式输出,可以设定阈值大于0.5为正样本,否则为负样本。因此设置不同的阈值就可以得到不同的ROC曲线中的点。
下面给出具体的实现过程:
来源:数据挖掘导论

下面给出sklearn中的实现过程:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
运行的结果如下图所示:

- 代价敏感错误率和代价曲线:现实任务中,不同错误所造成的结果是不同的。为衡量不同类型错误所造成的不同损失,可为错误赋予“非均衡代价”(unequal cost)。例如二分类任务,
,现实任务中,把第0类错误的预测成第1类错误,代价为cost01。同样,把第1类错误的预测成第0类错误,代价为cost10。通常cost01 ≠ cost10。则代价敏感错误率为
在非均等代价下,ROC曲线不能直接反映出学习器的期望总体代价,而“代价曲线”(cost curve)可以达到该目的。代价曲线图横轴取值为[0,1]的正例概率代价
,其中p为样例的正例概率;纵轴是取值为[0,1]的归一化代价
,其中FPR为假正率,FNR = 1-TPR是假反率。代价曲线绘制方法:ROC曲线上的每一点对应了代价平面上的一条线段,设ROC曲线上的点的坐标为(TPR,FPR),则可以计算出FNR,然后在代价平面上绘制一条从(0,FPR)到(1,FNR)的直线,直线下的面积代表该条件下的期望总体代价;将ROC上的点全都转换为直线,然后取所有线段下界,围城的面积即为在所有条件下的学习器的期望总体代价。

参考资料:
1.《机器学习》周志华
2.《数据挖掘导论》
3. 21 Must-Know Data Science Interview Questions and Answers
4. What is the difference between a ROC curve and a precision-recall curve? When should I use each?
5. Receiver Operating Characteristic (ROC) with cross validation















 2447
2447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









