




 文章介绍了一种名为TinyViT的模型,通过在IN-21K上进行预训练并利用快速蒸馏方法,提高了小模型处理大规模数据的能力。它还提出了一种分层Vit-block设计,以解决小模型拟合难题。蒸馏技术帮助学生模型学习教师的知识,尤其是处理复杂样本。研究强调了更强教师模型和有效设计在提升小模型表现中的作用。
文章介绍了一种名为TinyViT的模型,通过在IN-21K上进行预训练并利用快速蒸馏方法,提高了小模型处理大规模数据的能力。它还提出了一种分层Vit-block设计,以解决小模型拟合难题。蒸馏技术帮助学生模型学习教师的知识,尤其是处理复杂样本。研究强调了更强教师模型和有效设计在提升小模型表现中的作用。
PaperLink: https://arxiv.org/pdf/2207.10666.pdf
code: https://github.com/microsoft/Cream/tree/main/TinyViT
概要
1.基于IN-21K预训练TinyVit时使用快速蒸馏的方法,然后在IN-1K上微调,间接提高小模型对大数据的拟合能力;
2.不同于传统vit-block的设计,提出分层vit-block模块: 特征分辨率随着stage的增加逐步减少
技术名词解释
- Large-scale pretraining:使用大规模数据预训练的基础大模型,在多种下游任务中表现出色,eg: CLIP, Align,Florence.
- Small vision transformers: vit-tiny, tiny-vit-5m(vit+MB混合结构)
- Knowledge distillation:1)DeiT,使用CNN蒸馏Vit(引入可蒸馏的token);2)在image与patch间使用跳层连接;3)基于 pretraining的蒸馏正在研究中。
技术细节
-
Fast Pretraining Distillation
提前存储好数据增强+教师模型Florence的预测输出logits(TopK,稀疏的标签),蒸馏时直接load,如下图所示
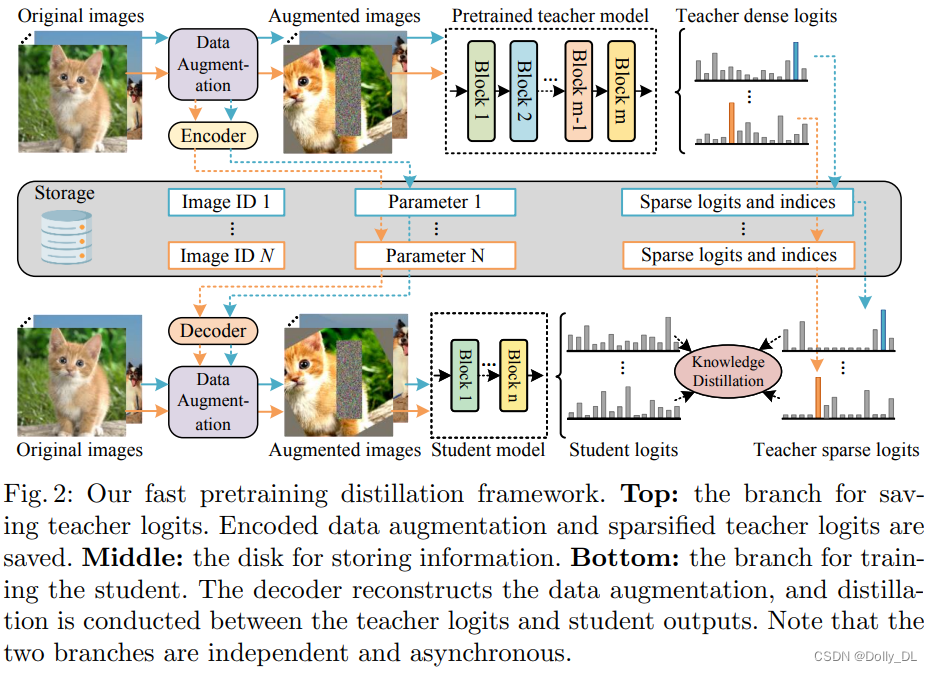
-
Model Architectures


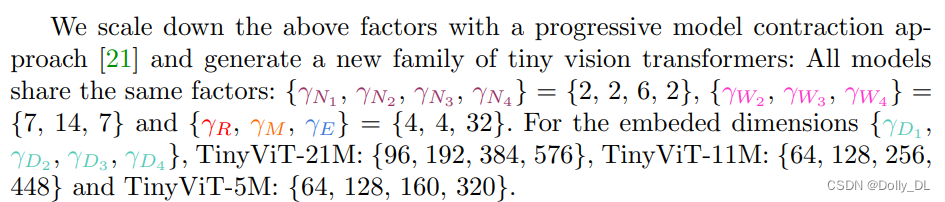
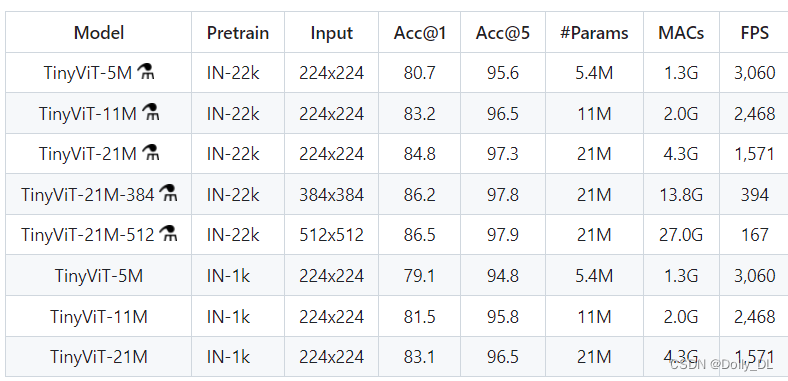
指标见下图:
分析
- 限制小模型拟合大规模数据的潜在因素是什么?
IN-21K中含有约10%的困难样本,如:1)标签错误;2)相似的图像是不同的标签(同一幅图像中显著性较强的目标不止1个),小模型很难拟合困难样本。清除部分困难样本后,小模型精度+;蒸馏(使用软标签)可避免这些困难样本带来的阻碍 - 为什么蒸馏可以解锁/促进小模型拟合大规模数据的能力?
学生可以直接学习教师的domain知识:训练时,教师将类别间的关系注入到学生中,过滤掉了学生模型的噪音样本
如图3所示,蒸馏后的TinyViT的Pearson关系更接近教师模型
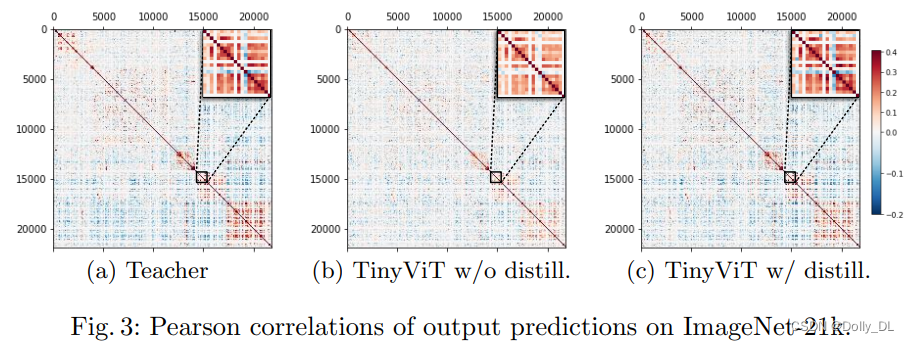
小结
- 使用更强的教师模型+更多的数据,解锁小模型的特征表达力 + 设计具有更高效的尺度下降模块的小模型(兼顾精度与性能)可研究;
- 文中tiny-vit中使用了DW,带bias(使用bias代替pos_emb,无cls_token,含window-size)的att/LeAttention,不知是否便于部署。
- IN-21k的数据说明+处理 戳这里
复现
- Teacher=clip-vit-l-14, Student=vit-t(原始论文为tinyvit-5m),使用in21k蒸馏预训练+in1k微调
相比timm中的开源的vit-t,在IN-1k测试集上指标上升1.62%(75.45%->77.068%)
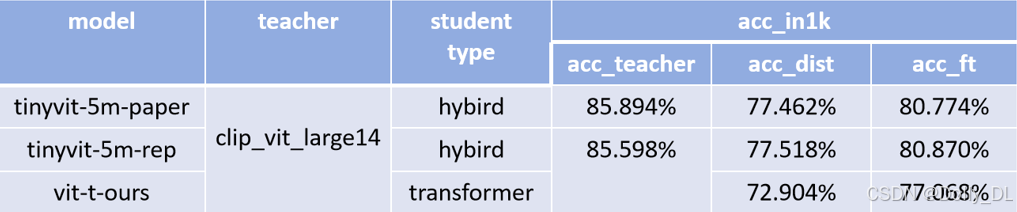
- timm中开源的vit-t训练方法为: IN21k-pretrain+IN1k-finetune
- 复现时,将原始代码中预先保存teacher的logits的两阶段方法,修改为在线蒸馏预训练
- 由于21k输出的logit非常稀疏(21k类),因此仅保留top100的logits,其余平均分配,有利于蒸馏loss的收敛
- 在下游分类任务的微调上,也验证了vit-t的有效性

















 2908
2908






 到【灌水乐园】发言
到【灌水乐园】发言







