






PaperLink:https://arxiv.org/pdf/2305.17007.pdf
code:https://github.com/WangYZ1608/Knowledge-Distillation-via-ND
概要
为了对齐教师模型与学生模型的特征,通常采用最小化logits与中层特征之间的KL散度的策略,但这种强制对齐并没有很直接地作用于学生模型的性能。本文提出使用教师特征的类均值(等效为分类器)对齐学生特征,同时提出ND-loss:1)鼓励学生输出large-norm特征;2)对齐老师与学生class-mean。
BaseModel
如下图所示,ND-loss可作用于不同的知识蒸馏中。如1)左图中logits蒸馏(通过约束logits或者softmax的输出分数,KD/DKD);2)右图中,特征蒸馏,约束特征输出/ReviewKD。本文则将其应用于embedding feature(中后层特征输出)的蒸馏中。
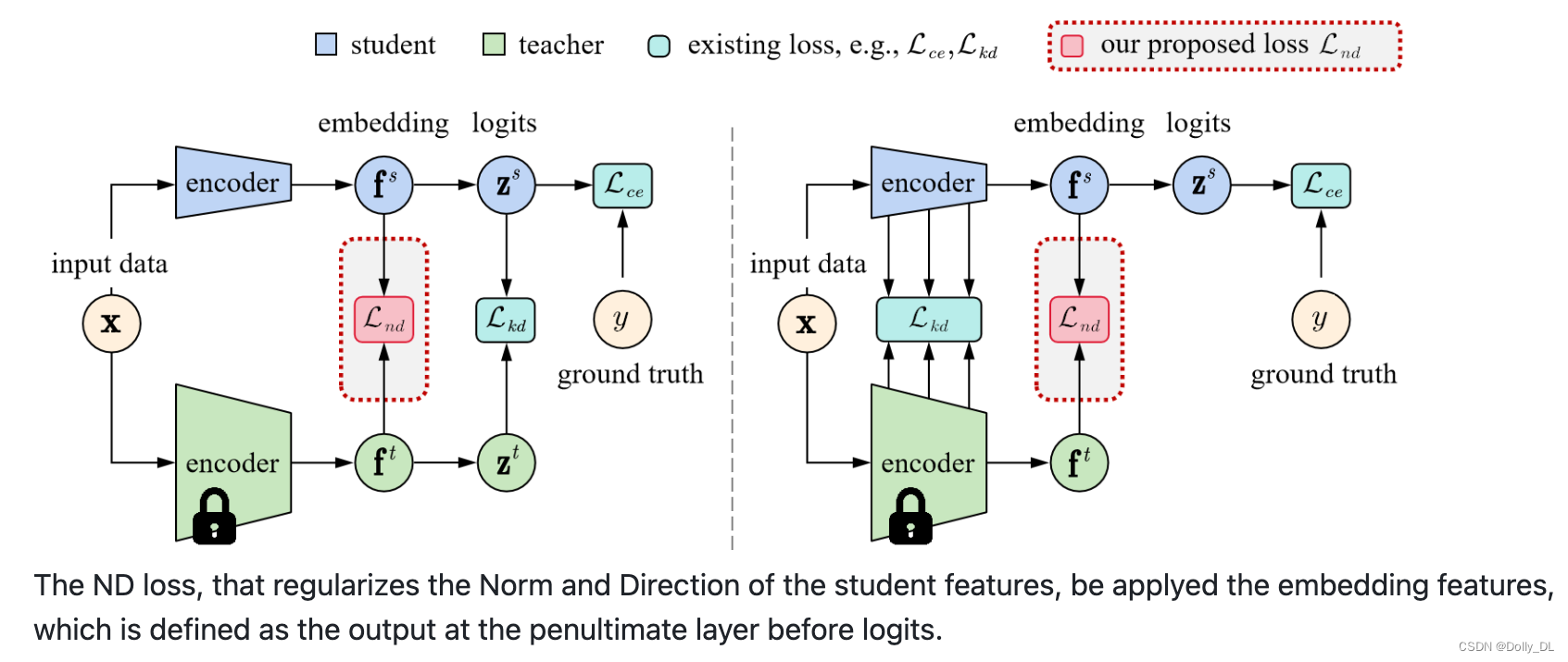
技术细节
- 特征Norm正则化
通过最小化特征的L2距离,使小模型学习到老师模型的larger-norm特性;同时在训练过程中我们逐渐增加特征的Norm,即Stepwise increasing feature norms (SIFN) - 特征Direction正则化
计算特征与class-mean的Cosine similarity;并借鉴InfoNCE,我们提出的Direction Loss也考虑了类间样本及其class-mean - ND Loss
fs与ft分别表示样本x(gt=y, class-mean=c)的student与teacher的特征输出
fs在c方向上的映射表示为:ps=fs*cos(fs, c)
e为c对应的单位向量;pt为ft在c上面的映射
各变量的物理意义见下图
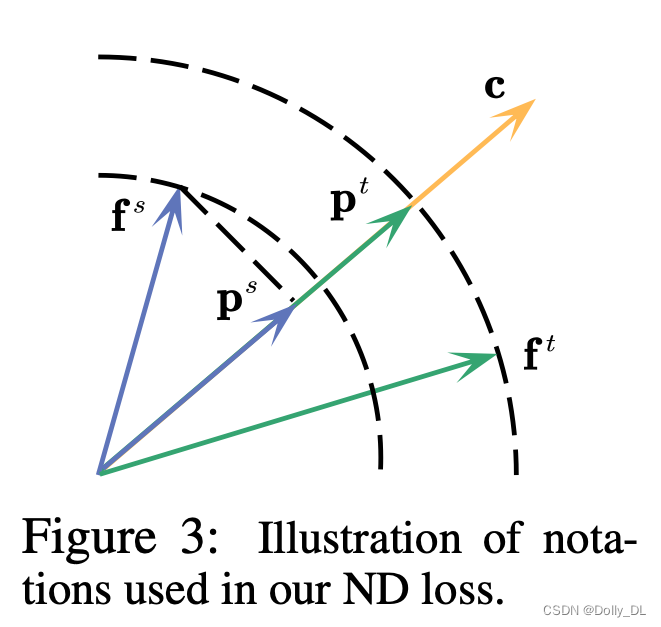
ND-Loss旨在最小化pt与ps之间的距离,定义为6式:1)增加fs的norm; 2)减少fs与c之间的角度距离。在所有训练样本上,ND-loss进一步表示为8式。
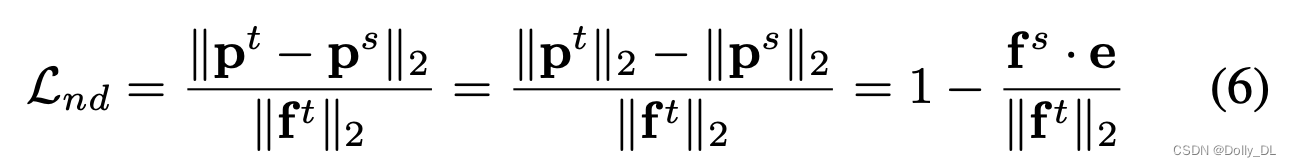
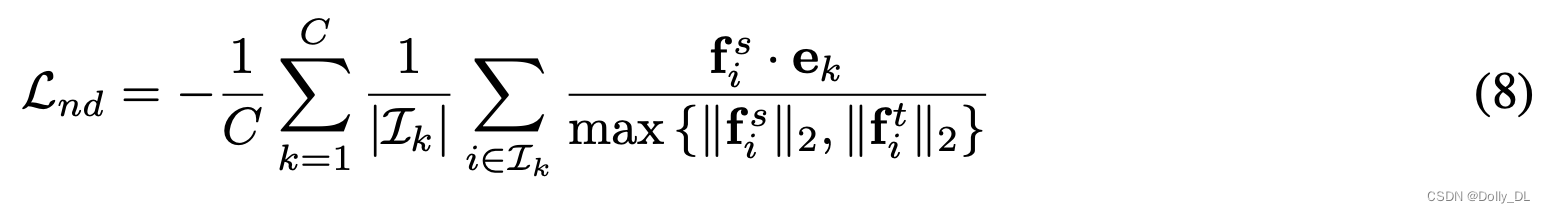
代码实现戳这里
class DirectNormLoss(nn.Module):
def __init__(self, num_class=1000, nd_loss_factor=1.0):
super(DirectNormLoss, self).__init__()
self.num_class = num_class
self.nd_loss_factor = nd_loss_factor
# s_emd:student feature; t_emb: teacher feature
# T_EMB: teacher class-means
def project_center(self, s_emb, t_emb, T_EMB, labels):
assert s_emb.size() == t_emb.size()
assert s_emb.shape[0] == len(labels)
loss = 0.0
for s, t, i in zip(s_emb, t_emb, labels):
i = i.item()
center = torch.tensor(T_EMB[str(i)]).cuda()
e_c = center / center.norm(p=2)
max_norm = max(s.norm(p=2), t.norm(p=2))
loss += 1 - torch.dot(s, e_c) / max_norm
return loss
def forward(self, s_emb, t_emb, T_EMB, labels):
nd_loss = self.project_center(s_emb=s_emb, t_emb=t_emb, T_EMB=T_EMB, labels=labels) * self.nd_loss_factor
return nd_loss / len(labels)
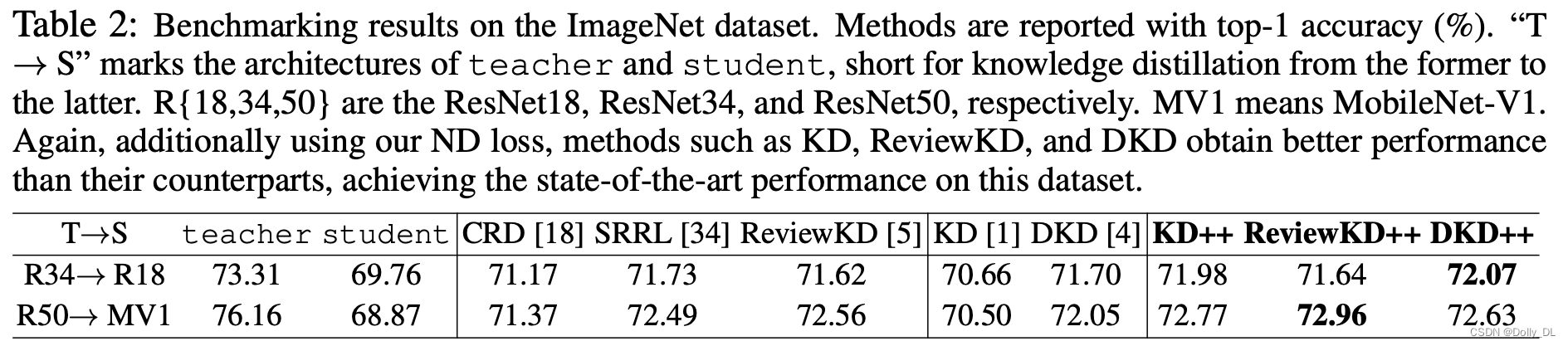
- 在IN-1K上的表现
小结
- Norm可理解为数学中的模或者幅值
- ND-loss的解释性还可以















 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









