







【多模态】qwen2-vl模型代码技术学习
1.前言
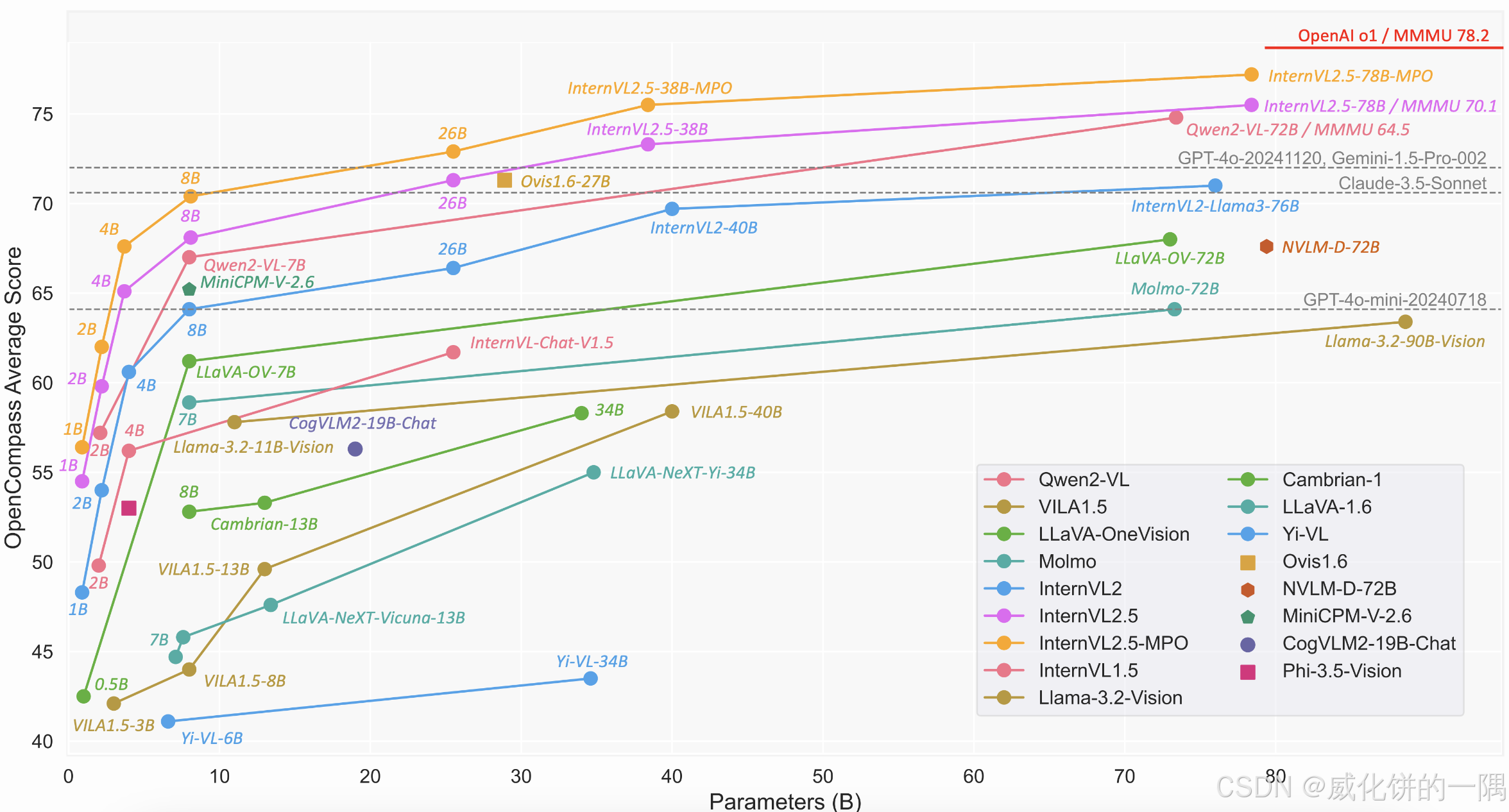
qwen2-vl在2024年9月发布,在现在榜单上也是属于top级别,在一些数据上测试下来不比最新的internvl2.5和minicpm-o-2.6差
2.qwen2-vl架构
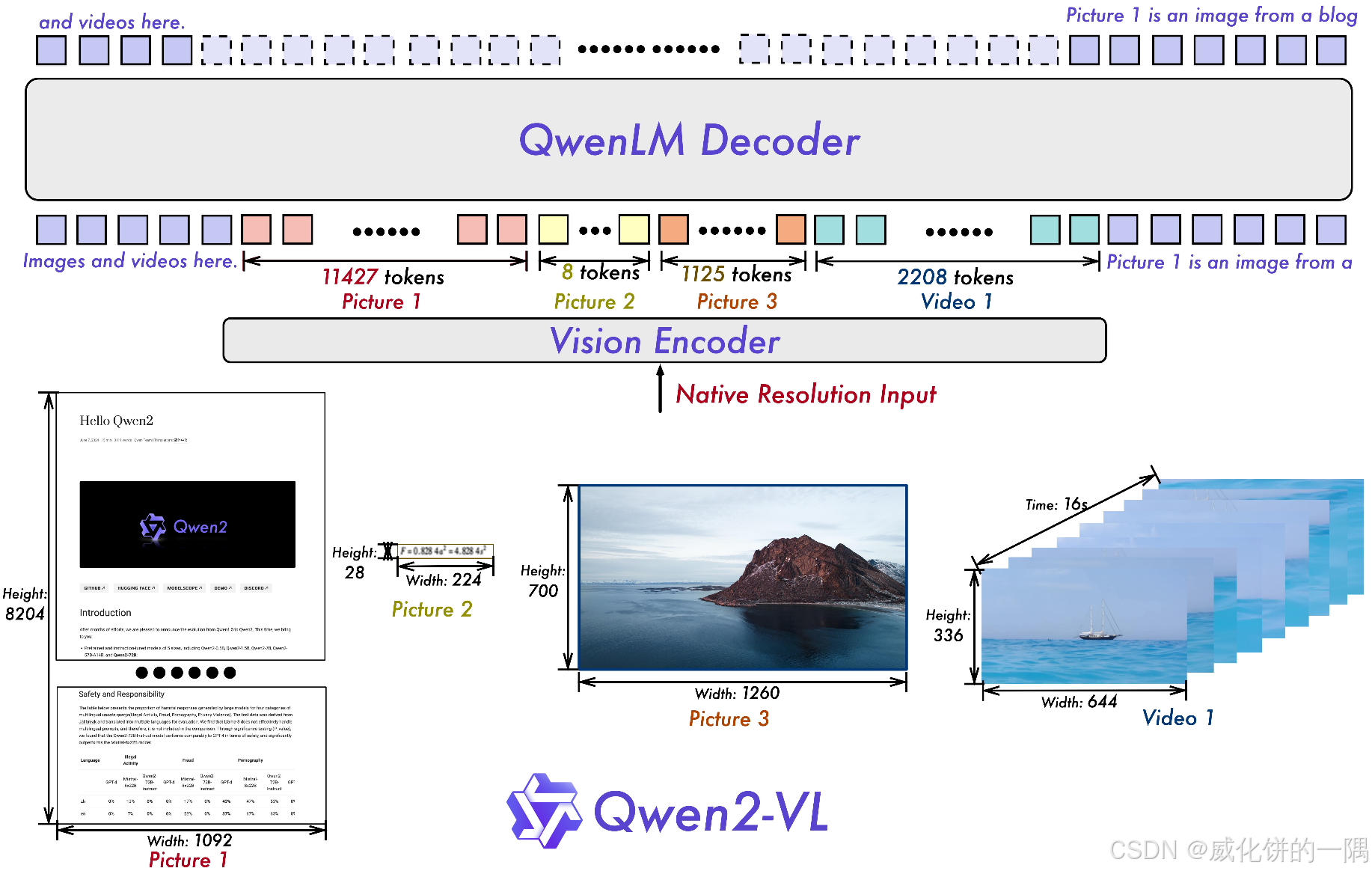
qwen2-vl的架构和大部分多模态模型一样,由ViT+merger+LLM这三部分构成,之前的不少模型是只训练了merger,例如BLIP系列,qwen2-vl在ViT中使用2D-rope编码方式,重新训了ViT。
3.图片推理流程
以这样的调用方式为例:
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "demo.jpeg",
},
{"type": "text", "text": "What can you see in the image?"},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
假如输入图片的原始输入图片大小为(2300, 1200)
3.1 图片预处理
(1)process_vision_info,里面有fetch_image函数,fetch_image里面也先稍微放缩了一下处理图片大小,处理之后图片大小,变成能除以28的,变成方便后续能处理的大小( 14 ∗ 14 ∗ 2 ∗ 2 14*14*2*2 14∗14∗2∗2的倍数,后面每 2 ∗ 2 2 *2 2∗2 会被merger压缩掉,压缩为1/4,这也是28的倍数的由来)【此时image.shape=(2296,1204)】
(2)会在image_processing_qwen2_vl.py中定义的Qwen2VLImageProcessor函数下,调用_process进一步处理图片 ,主要是关注smart_resize,在这里会对超过尺寸的图片进行放缩,这里面的max_pixels定义了最大的像素值,例如 m a x _ p i x e l s = 28 ∗ 28 ∗ 768 = 602112 max\_pixels=28*28*768=602112 max_pixels=28∗28∗768=602112。【经过smart_resize后,resized_height=560, resized_width=1064, 560 ∗ 1064 = 595840 < 602112 560*1064=595840<602112 560∗1064=595840<602112】
# image_processing_qwen2_vl.py
# Qwen2VLImageProcessor函数调用
# _process函数
resized_height, resized_width = smart_resize(
height,
width,
factor=self.patch_size * self.merge_size, # 14*2=28
min_pixels=self.min_pixels,
max_pixels=self.max_pixels, # 28*28的倍数
)
(3) 在smart_resize后,_process函数还进行了一个处理,如果图片只有1张,还会复制一份,让第一个维度为2,变成(2, 3, 560, 1064),qwen2-vl的每个时间步有2张图(temporal_patch_size=2),统一图片和视频处理。
# image_processing_qwen2_vl.py
# Qwen2VLImageProcessor函数调用_process
# _process函数
.............
patches = np.array(processed_images)
if data_format == ChannelDimension.LAST:
patches = patches.transpose(0, 3, 1, 2)
if patches.shape[0] % self.temporal_patch_size != 0:
repeats = np.repeat(patches[-1][np.newaxis], self.temporal_patch_size - 1, axis=0)
patches = np.concatenate([patches, repeats], axis=0)
channel = patches.shape[1]
# grid_t,grid_h,grid_w=(1, 40, 76)
grid_t = patches.shape[0] // self.temporal_patch_size
grid_h, grid_w = resized_height // self.patch_size, resized_width // self.patch_size
patches = patches.reshape(
grid_t, # 1
self.temporal_patch_size, # 2
channel, # 2
grid_h // self.merge_size, # 40 // 2
self.merge_size, # 2
self.patch_size, # 14
grid_w // self.merge_size, # 76 // 2
self.merge_size, # 2
self.patch_size, # 14
)
patches = patches.transpose(0, 3, 6, 4, 7, 2, 1, 5, 8)
flatten_patches = patches.reshape(
grid_t * grid_h * grid_w, channel * self.temporal_patch_size * self.patch_size * self.patch_size
)
# flatten_patches形状为(3040, 1176) grid_t,grid_h,grid_w=(1, 40, 76)
return flatten_patches, (grid_t, grid_h, grid_w)
3.2 位置预留
(1) 调用回到main,inputs[‘input_ids’].shape为(1, 794),可以把input_ids解码打印,会发现它的结构是:
<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nPicture 1: <|vision_start|><|image_pad|><|image_pad|>....
<|image_pad|><|vision_end|>What can you see in the image?<|im_end|>\n<|im_start|>assistant\n
里面<|image_pad|>只有760个,因为3040/4=760,也就是文本上只留了1/4的位置,图片里面有个地方会把3040压缩到1/4。
(2)然后调用generate,在modeling_qwen2_vl.py的Qwen2VLForConditionalGeneration里面,首先是进行文本编码,文本的向量维度是3584
# modeling_qwen2_vl.py
# Qwen2VLForConditionalGeneration的forward函数
if inputs_embeds is None:
inputs_embeds = self.model.embed_tokens(input_ids) # (1,794,3584)
if pixel_values is not None:
pixel_values = pixel_values.type(self.visual.get_dtype())
image_embeds = self.visual(pixel_values, grid_thw=image_grid_thw)
n_image_tokens = (input_ids == self.config.image_token_id).sum().item()
n_image_features = image_embeds.shape[0]
if n_image_tokens != n_image_features:
raise ValueError(
f"Image features and image tokens do not match: tokens: {n_image_tokens}, features {n_image_features}"
)
image_mask = (
(input_ids == self.config.image_token_id)
.unsqueeze(-1)
.expand_as(inputs_embeds)
.to(inputs_embeds.device)
)
image_embeds = image_embeds.to(inputs_embeds.device, inputs_embeds.dtype)
inputs_embeds = inputs_embeds.masked_scatter(image_mask, image_embeds) # 类似minicpm-v的方式
3.3 图片编码
(1)上面self.visual进入vit,先做图片的embedding,大小从(3040, 1176)变成(3040, 1280),图片的向量维度是1280,长度为3040。首先调用Qwen2VisionTransformerPretrainedModel下的函数。grid_thw大小为(1,40,76),cu_seqlens为[3040],然后pad之后cu_seqlens为[0, 3040],表示下标0到下标3040间是第一张图片,cu_seqlens用于控制attention时,本图只会和本图计算attention,这是qwen2vl的机制。
# modeling_qwen2_vl.py
# Qwen2VisionTransformerPretrainedModel下forward函数
def forward(self, hidden_states: torch.Tensor, grid_thw: torch.Tensor) -> torch.Tensor:
hidden_states = self.patch_embed(hidden_states)
rotary_pos_emb = self.rot_pos_emb(grid_thw) # (3040, 40)
cu_seqlens = torch.repeat_interleave(grid_thw[:, 1] * grid_thw[:, 2], grid_thw[:, 0]).cumsum(
dim=0,
# Select dtype based on the following factors:
# - FA2 requires that cu_seqlens_q must have dtype int32
# - torch.onnx.export requires that cu_seqlens_q must have same dtype as grid_thw
# See https://github.com/huggingface/transformers/pull/34852 for more information
dtype=grid_thw.dtype if torch.jit.is_tracing() else torch.int32,
) # [3040]
cu_seqlens = F.pad(cu_seqlens, (1, 0), value=0) # [0,3040]
for blk in self.blocks:
if self.gradient_checkpointing and self.training:
hidden_states = self._gradient_checkpointing_func(
blk.__call__, hidden_states, cu_seqlens, rotary_pos_emb
)
else:
hidden_states = blk(hidden_states, cu_seqlens=cu_seqlens, rotary_pos_emb=rotary_pos_emb)
return self.merger(hidden_states)
(2) 进入vit里面的block可以看到,attention_mask初始化为负无穷,只有这张图片里面的可以计算attention
# VisionAttention里面forward函数
attention_mask = torch.full(
[1, seq_length, seq_length], torch.finfo(q.dtype).min, device=q.device, dtype=q.dtype
)
for i in range(1, len(cu_seqlens)):
attention_mask[..., cu_seqlens[i - 1] : cu_seqlens[i], cu_seqlens[i - 1] : cu_seqlens[i]] = 0
q = q.transpose(0, 1)
k = k.transpose(0, 1)
v = v.transpose(0, 1)
attn_weights = torch.matmul(q, k.transpose(1, 2)) / math.sqrt(self.head_dim)
attn_weights = attn_weights + attention_mask
(3)经过ViT的块blk是不会改变输出维度的,还是(3040, 1280)大小,进入merger后,由merger完成压缩,长度被压缩为1/4,得到的merger之后的图片向量大小为torch.Size(760, 3584),然后填充到之前预留的padding位置上即可。
class PatchMerger(nn.Module):
def __init__(self, dim: int, context_dim: int, spatial_merge_size: int = 2) -> None:
super().__init__()
self.hidden_size = context_dim * (spatial_merge_size**2)
self.ln_q = LayerNorm(context_dim, eps=1e-6)
self.mlp = nn.Sequential(
nn.Linear(self.hidden_size, self.hidden_size),
nn.GELU(),
nn.Linear(self.hidden_size, dim),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.mlp(self.ln_q(x).view(-1, self.hidden_size))
return x
#例如,一开始x为(1,8,4)
x=[[[1,2,3,4],
[5,6,7,8],
....,
[29,30,31,32,],]]
# 最后的x为(2,16)
x = [[1,2,3,4,....,13,14,15,16],
[17,18,....,31,32]]
4. qwen2-vl实践
4.1 环境安装
使用最新版本的swift3来进行微调和推理,会非常方便。
# 首先安装conda python3.10
conda create -n swift3 python==3.10
# 然后安装torch和torchvision,python3.10下会安装2.5.0的torch
pip install torch torchvision
# 安装flash-attn,如果安装失败像前一篇一样安装,注意qwen2-vl需要这个版本的transformer,以及需要安装qwen_vl_utils
# 如果网络不好,flash-attn先wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.2.post1/flash_attn-2.7.2.post1+cu12torch2.5cxx11abiFALSE-cp310-cp310-linux_x86_64.whl,然后在pip install 这个whl【需要在这个仓库里面找符合本机的whl版本】
pip install flash-attn qwen_vl_utils transformers==4.46.1
# 安装timm
pip install auto_gptq optimum bitsandbytes timm
# 下载仓库安装swift3,网络不好上github官网下载解压,最好拉取最新的不然可能有各种bug,当然新的也会有,有问题可以取官方群里面问,解决会比较快
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
# 如果有需要,安装vllm
pip install vllm
在安装完之后,可以在命令行里面激活这个conda环境输入swift回车看看,如果报错说swift缺少arg参数说明安装成功了,如果说swift不存在not found说明没装好。
4.2 SFT
4.2.1 数据准备
微调模型最重要的步骤是准备好数据集,和数据对应的jsonl文件,训练数据可以是query-response-images格式的,其中"<image>“表示这个位置是一张图片,图片的位置在后面images的列表里面,有多少个”<image>"标签,“images“列表里面就多少个地址,报错一般就是地址不对,以及注意地址是一个列表。
#jsonl格式的数据
{"query": "<image>55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee<image>eeeee<image>eeeee", "response": "fffff", "history": [], "images": ["image_path1", "image_path2"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["query1", "response2"], ["query2", "response2"]], "images": []}
4.2.2 模型训练
训练的时候对于单卡GPU可以运行下面脚本,多卡的看文档。MAX_PIXELS指定了最大像素,不指定的话默认是非常大的值会爆显存。 M A X _ P I X E L S = 1280 ∗ 28 ∗ 28 MAX\_PIXELS=1280*28*28 MAX_PIXELS=1280∗28∗28,也就是模型看到的图最大会是这么大。swift3里面学习率等很多参数默认都是none的,需要自己设置。
# 训练internvl2.5时去掉下面第一行的"NPROC_PER_NODE=1"
# qwen2-vl的时候可以保留NPROC_PER_NODE=1,打印日志看着不会错位
NPROC_PER_NODE=1 CUDA_VISIBLE_DEVICES=0 MAX_PIXELS=1003520 swift sft \
--model_type qwen2_vl \ # 模型名字,可以在swift文档里面支持的模型里面找model_type
--model_id_or_path 模型路径 \ # 本地模型路径,填写绝对路径,例如/xxx/xxx/
--dataset train_data.jsonl \ # 训练数据集
#-- val_dataset eval_data.jsonl \ # 验证集
--sft_type lora \ # lora微调/full为全参微调
--attn_impl flash_attn \ # 使用flash-attn提速
--freeze_vit false \ # 如果为true,不微调vit模块
--freeze_aligner false \ # 如果为true,不微调merger模块
--freeze_llm false \ # 如果为true,不微调llm模块
#--freeze_parameters_ratio 0. \ # freeze参数的比例,sft_type=full的时候可以设置
--per_device_train_batch_size 1 \ # 训练数据上的batch_size
--per_device_eval_batch_size 4 \ # eval_set上的batch_size
--split_dataset_ratio 0.1 \ # 训练集里面多大比例作为验证集,如果没有输入验证集的话
--acc_strategy seq \ # 如果为seq,验证集上显示的是模型语句上的准确率(完全一样才算对),不然默认是token,是token级别准确率
--output_dir /home/xxx/output_dir/ \
#--max_steps 1500 \ # 最大训练步数,以step为单位时
--num_train_epochs 6 \ # epoch数,完整见过训练集的次数,以epoch为单位,收敛即可
--save_steps 100 \
--eval_steps 100 \
--save_total_limit 2 \ # 最大保存模型次数,为2时会保存验证集loss最小的模型和最后一个模型,不一定loss最小的模型最好,收敛情况下最后一个模型可能更好
--logging_steps 10 \
--seed 42 \
--learning_rate 1e-4 \ # 学习率
--init_weights true \
--lora_rank 8 \ # lora的r
--lora_alpha 32 \
--adam_beta1 0.9 \
--adam_beta2 0.95 \
--adam_epsilon 1e-08 \
--weight_decay 0.1 \
--gradient_accumulation_steps 16 \ # 每一个step模型见过的数据是per_device_train_batch_size*gradient_accumulation_steps,这两个相乘为16比较好
--max_grad_norm 1 \
--lr_scheduler_type cosine \
--warmup_ratio 0.05 \
--warmup_steps 0 \
--gradient_checkpointing false # 开启梯度检查点为true时训练会变慢
4.3 模型推理
推理时,记得一定要确认swift3是最新版本的没有推理bug的版本。以及推理时,待推理的数据集的/data/coding/content_test.jsonl里面的格式和训练集一样,query-response-images,记住response不能为空,里面随便填个字符串就行,比如填个序号"1"、"2"这样。
4.3.1 vllm后端推理
如果是模型回复很长的,用vllm会快很多。如果图片数量超过1,需要设置limit_mm_per_prompt,控制vllm使用多图, 默认为None。
#单卡vllm推理脚本(前面不要有NPROC_PER_NODE参数,否则会挂起)
#如果运行时突然exit,可能是内存炸了,显存没炸(vllm推理时把整个数据集读到内存里面了),这时更新最新的ms-swift版本有修复
CUDA_VISIBLE_DEVICES=0 MAX_PIXELS=1003520 swift infer \
--ckpt_dir /data/coding/checkpoint-3000-merged \ # 模型地址,推理时不要写model_type
--attn_impl flash_attn \ # 使用flash_attn,vllm本身默认也会使用vllm-flash-attn
--max_new_tokens 300 \ # 最大生成的token数量,防止超长语句出现
--temperature 0 \ # 表示do_sample=false,不采样
--val_dataset /data/coding/content_test.jsonl \ # 要推理的数据集
--result_path output_3000.jsonl \ # 推理结果保存路径
--max_num_seqs 256 \ # 爆显存降低这个值
--gpu_memory_utilization 0.9 \ # 爆显存降低这个值
--infer_backend vllm \
##--–limit_mm_per_prompt '{“image”: 10, “video”: 5}' # 如果会有输入是多图的,这个参数表示最多10张图,5个视频,否则多图会报错
4.3.2 pt后端推理
如果是模型回复很短的,用这个就行
# pt推理
NPROC_PER_NODE=1 MAX_PIXELS=1003520 swift infer \
--ckpt_dir /data/coding/checkpoint-3000-merged \
--attn_impl flash_attn \
--max_new_tokens 300 \
--temperature 0 \
--val_dataset /data/coding/content_test.jsonl \
--result_path output_3000.jsonl \
--max_batch_size 16 \ # 爆显存降低这个值
--infer_backend pt
5. TODO
最近参加了天池的WWW多模态比赛,分数不高,但是参加下来还是学到了不少东西的,有时间写写这些内容,踩过的坑可以让大家少踩。各种位置编码的原理和代码之后有时间慢慢看看这个应该也挺有意思的。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









