






本文要做的是预测一条二元一次的直线:
y = 0.1x + 0.3
预测过程中输出每隔一定训练次数时的b和a的值。
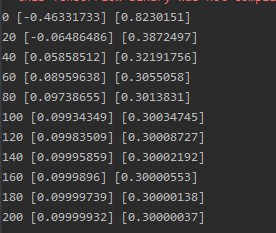
下面是本例子的代码:
import tensorflow.compat.v1 as tf#这是一个机器学习框架
tf.disable_v2_behavior()
import numpy as np
#create data
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
#create tensorflow structure start
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
biases = tf.Variable(tf.zeros([1]))
y = Weights * x_data + biases
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
init = tf.initialize_all_variables()
#create tensorflow structure end
sess = tf.Session()
sess.run(init)
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(Weights), sess.run(biases))
- 导入tensorflow库并简写为tf,tf是一个深度学习框架
- 导入numpy库并简写为np,np是一个进行科学计算的模块,是一个可以在多维数组和矩阵上执行高级数学函数的库
- 创造数据x_data,随机产生100个范围在[0,1)之间,类型为float32的数。在tensorflow中,其大部分的数据类型都是float32。 y_data = x_data * 0.1 + 0.3 开始创建tensorflow神经网络结构
- Weights相当于参数b,biases相当于参数a
- tf.Variable()中的Variable是‘变量’的意思,tf.Variable()可以理解为生成参数变量tf.random_uniform()是生成随机数列的意思。[1]指的是一个一维的结构,因为参数b是一个一维的数据。-1,1是随机数的范围
- tf.zero()指生成数值为‘0’的数据,其中[1]也是指一个一维结构 y指的是预测得到的因变量的值
- 7计算loss为的是能在接下来的训练中提升y的准确度,loss等于预测值y和真实值y_data的均方差
- 8optimizer是神经网络需要建立的一个优化器, 0.5指的是learningrate(学习率),学习率一般是一个小于1的数并且用这个优化器optimizer使得误差loss到最小。提升参数的准确度,使得下次训练得到的误差更小,这是训练神经网络非常重要的一点
- initialize_all_variables()可以理解为初始化神经网络。因为虽然我们之前已经建立了变量Weights,biases,但是在神经网络中却还没有初始化这些变量
- sess.run(init)是激活神经网络,run就像一个指针,它的参数init就是指针指向的位置.
博客内容通过整理莫烦tensorflow教学视频,如果觉得对你有用,请留下你的赞。















 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









