






IBM Model1
IBM Model 是统计机器翻译中的经典翻译模型
IBM Model1仅考虑了词和词之间的互译概率
记录学习lecture-ibm-model1的过程
学习
- 外来句子, foreign sentence f = ( f 1 , . . . f l f ) f=(f_1,...f_{l_f}) f=(f1,...flf),长度为 l f l_f lf
- 英文句子, english sentence e = ( e 1 , . . . , e l e ) e =(e_1,...,e_{l_e}) e=(e1,...,ele),长度为 l e l_e le
- a, alignment 外来句子中的词和英文句子中的词的对应关系,假设英文句子中的 e j e_j ej对应外来句子中的 f i f_i fi(相同意思),则对应关系为 a : j → i a:j\rightarrow i a:j→i
- 目标函数, P ( a ∣ e , f ) P(a|e,f) P(a∣e,f),以给定的外来和英语为条件,找出其alignment
- 参数估计,EM算法
假设是需要将外来句子翻译成英文句子
目标函数
pdf中先给出了一个公式
p
(
e
,
a
∣
f
)
=
ϵ
(
l
f
+
1
)
l
e
∏
j
=
1
l
e
t
(
e
j
∣
f
a
(
j
)
)
p(e,a|f)=\frac{\epsilon}{(l_f+1)^{l_e}}\prod_{j=1}^{l_e}t(e_j|f_{a(j)})
p(e,a∣f)=(lf+1)leϵj=1∏let(ej∣fa(j))
一开始看,懵了,怎么突然来这么一个公式,这公式什么意思
很多地方都是直接这样一个公式都不知道为什么,也不知道什么是什么,增加了小白我学习的难度,唉,泪啊
目标是要翻译成英文句子,那么每个英文单词有其对应的外文单词
a
=
(
a
1
,
a
2
,
.
.
.
,
a
l
e
)
a = (a_1, a_2, ..., a_{l_e})
a=(a1,a2,...,ale) , a_1 表示第1个英文单词对应的外文句子中对应单词的位置,每个值的范围为
(
0
,
l
f
)
(0, l_f)
(0,lf)
从0开始的原因是因为,万一有个英文词找不到对应的外文词,比如语气词之类的,可以在外文句前加个NULL使得外文句长为
l
f
+
1
l_f+1
lf+1
英文单词有
l
e
l_e
le个,所以有
l
e
l_e
le个对应关系
t
(
e
j
∣
f
a
(
j
)
)
t(e_j|f_{a(j)})
t(ej∣fa(j))相当于给定
f
a
j
f_{aj}
faj翻译成
e
j
e_j
ej的概率,可以看这篇
对于pdf中的图

p
(
e
,
a
∣
f
)
=
0.56
=
0.7
∗
0.8
=
p
(
t
h
e
∣
l
a
)
∗
p
(
h
o
u
s
e
∣
m
a
i
s
o
n
)
p(e,a|f)=0.56 = 0.7*0.8=p(the|la)*p(house|maison)
p(e,a∣f)=0.56=0.7∗0.8=p(the∣la)∗p(house∣maison)
la翻译成the的可能性为0.7
masion翻译成house的可能性为0.8
那么第一种情况是这两者同时翻译
根据贝叶斯定理
p
(
a
∣
e
,
f
)
=
p
(
e
,
a
∣
f
)
p
(
e
∣
f
)
p(a|e,f)=\frac{p(e,a|f)}{p(e|f)}
p(a∣e,f)=p(e∣f)p(e,a∣f)
那么需要计算
p
(
e
∣
f
)
p(e|f)
p(e∣f)
根据pdf
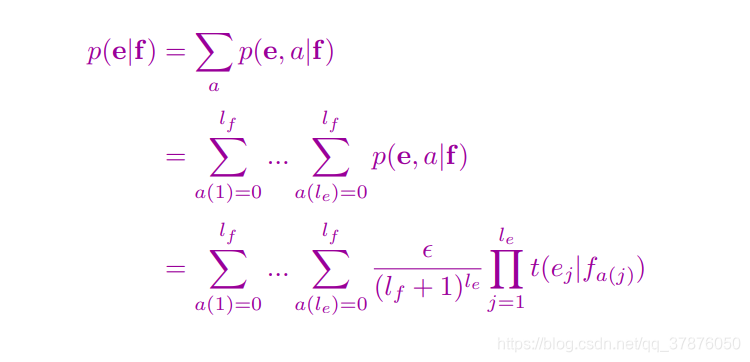
因为英文单词有
l
e
l_e
le个,所以a的对应有
l
e
l_e
le个
所以第二个等式中每一个
∑
\sum
∑表示每个外文单词翻译到第i个英文单词的概率和,然后再乘起来
然后等式可以继续化下去
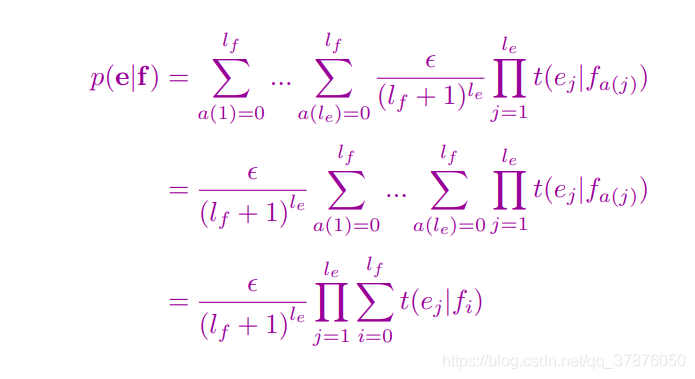
然后在看第二个等式到第三个等式
拿上面翻译的例子推了下,嗯,是正确的

可以按照写的式子
p
(
e
∣
f
)
=
0.035
+
0.56
+
0.005
+
0.08
=
0.68
p(e|f)=0.035+0.56+0.005+0.08=0.68
p(e∣f)=0.035+0.56+0.005+0.08=0.68
然后有了目标式子
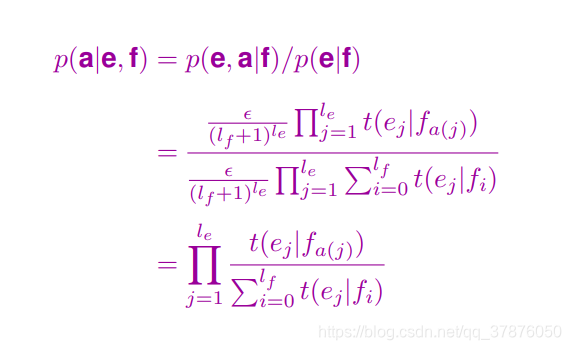
则第一种对应关系
p
(
a
∣
e
,
f
)
=
0.56
0.68
=
0.824
p(a|e,f)=\frac{0.56}{0.68}=0.824
p(a∣e,f)=0.680.56=0.824
计算正确
到这里,目标函数的推导应该差不多了
参数估计
接着是这么一个公式,这公式又是啥?



查了一些资料
c
(
e
∣
f
)
c(e|f)
c(e∣f)是训练数据中,外语单词f与英文单词e正确匹配的概率
c
(
e
)
c(e)
c(e)表示不同的外文词f翻译成词e的概率和
δ
(
e
,
e
j
)
\delta(e,e_j)
δ(e,ej)表示
e
j
e_j
ej在句子e中的期望次数
δ
(
f
,
f
j
)
\delta(f,f_j)
δ(f,fj)表示
f
j
f_j
fj在句子e中的期望次数
δ
(
e
,
e
j
)
δ
(
f
,
f
j
)
\delta(e,e_j)\delta(f,f_j)
δ(e,ej)δ(f,fj)表示词f到词e的个数(好吧,不懂)
举个例子
初始情况下,一个外语单词对所有英语单词的翻译的可能性是相同的
假设中文为外语f,需要翻译成英语e。免得把一些符号搞晕


然后按照公式推了下,拍的图片可能有点糊,但不影响
忘记写c(e)了。在语料1,a1的情况下, c(a)就相当于分母
c
(
a
)
=
t
(
a
∣
一
本
)
+
t
(
a
∣
书
)
=
1
3
+
1
3
=
2
3
c(a) = t(a|一本)+t(a|书)=\frac1 3 + \frac 1 3=\frac 2 3
c(a)=t(a∣一本)+t(a∣书)=31+31=32
然后继续计算下去,虽然不知道这些公式是怎么来的,但概率矩阵也的确按照理想的变化在变化
代码
伪代码

python 代码
# 语料库
corpus = [[['一本','书'],['a','book']],[['一本', '杂志'],['a', 'magazine']]]
# 设置英文外文词汇表
english_vocab = []
foreign_vocab = []
for sp in corpus:
for fw in sp[0]:
foreign_vocab.append(fw)
for ew in sp[1]:
english_vocab.append(ew)
english_words = sorted(list(set(english_vocab)), key=lambda s:s.lower())
foreign_words = sorted(list(set(foreign_vocab)), key=lambda s:s.lower())
print('English words:\n', english_vocab)
print('Foreign words:\n', foreign_vocab)
# 给定e,f句子和t,计算p(e|f)
def probability_e_f(e, f, t, epsilon=1):
l_e = len(e)
l_f = len(f)
p_e_f = 1
for ew in e:
t_ej_f = 0
for fw in f:
t_ej_f += t[fw][ew]
p_e_f = t_ej_f * p_e_f
p_e_f = p_e_f * epsilon / ((l_f+1)**l_e)
return p_e_f
# 输入语料库计算perplexity
def perplexity(corpus, t, epsilon=1):
log2pp = 0
for sp in corpus:
prob = probability_e_f(sp[1], sp[0], t)
log2pp += math.log(prob, 2)
pp = 2.0 **(-log2pp)
return pp
t = {} # 用来保存不同外文单词翻译成不同英文单词的概率
init_val = 1.0/len(english_words) # 初始情况下,一个外文单词翻译成不同英文单词的概率是相同的
for fw in foreign_words:
for ew in english_words:
if fw not in t:
t[fw] = {}
t[fw][ew] = init_val
print('\nInit t ')
for fw in t:
print('Foreign word: ', fw)
sorted_list = sorted(t[fw].items(), key=lambda x:x[1], reverse=True)
for (ew, p) in sorted_list:
print('prob to %s \tis %f'%(ew, p))
print('')
num_epochs = 10
s_total = {}
perplexities = []
for epoch in range(num_epochs):
print("--------epoch % s--------" % (epoch + 1))
perplexities.append(perplexity(corpus, t))
count = {}
total = {}
for fw in foreign_words:
total[fw] = 0.0
for ew in english_words:
if fw not in count:
count[fw] = {}
count[fw][ew] = 0.0
for sp in corpus:
# s_total[a]相当于上面手工推演中的t(a|一本)+t(a|书)
# s_total也就相当于c(e)
for ew in sp[1]:
s_total[ew] = 0.0
for fw in sp[0]:
s_total[ew] += t[fw][ew]
# 此时计算出的count[一本][a]相当于c(a|一本),在不同语料中继续相加相同对应的概率
# total[一本]相当于一本翻译成不同英文词的概率和
# 还要考虑不同语料,主要用于t概率矩阵的归一化
for ew in sp[1]:
for fw in sp[0]:
count[fw][ew] += t[fw][ew] / s_total[ew]
total[fw] += t[fw][ew] / s_total[ew]
# 概率的归一化,使得一个外文单词翻译成不同英文单词的概率和为1
for fw in foreign_words:
for ew in english_words:
t[fw][ew] = count[fw][ew] / total[fw]
for fw in t:
print('foreign word: ', fw)
sorted_list = sorted(t[fw].items(), key=lambda x:x[1], reverse=True)
for (ew, p) in sorted_list:
print('prob to %s \tis %f'%(ew, p))
print('')
plt.plot(perplexities) # 需要matplotlib库
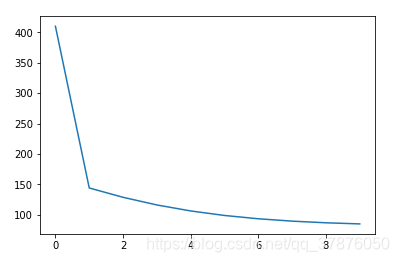
嗯~ ,貌似这样就完成了model1
按照代码我又推了一遍,很好的符合了上面手推的过程
至于那些个公式是怎么来的,不知道
听从pdf的指示(我是小白)
至于如何衡量模型,那么就是困惑度 perplexity
pdf中给出了公式 ,并且写在了代码中
l
o
g
2
P
P
=
−
∑
s
l
o
g
2
p
(
e
s
∣
f
s
)
log_2PP=-\sum_slog_2p(e_s|f_s)
log2PP=−s∑log2p(es∣fs)
参考资料
- lecture-ibm-model1
- mt2
- https://zhuanlan.zhihu.com/p/72160554
- http://blog.sina.com.cn/s/blog_6335d3b00100w4ch.html
- https://zhuanlan.zhihu.com/p/72640549
- 应该还有一些,忘记保存了














 8875
8875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









