






import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
import copy
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torch.utils.data as data
from torchvision import transforms
# import hiddenlayer as hl
'''
数据准备
每个batch包含64张图像
训练集中包括60000张28*28的灰度图像
测试集中包括10000张28*28的灰度图像
'''
train_data = torchvision.datasets.MNIST(
root = './mnist', train=True, transform= transforms.ToTensor(),
)
train_loader = data.DataLoader(
dataset=train_data, batch_size=64, shuffle= True,drop_last=True
)
test_data = torchvision.datasets.MNIST(
root= './mnist', train=False, transform= transforms.ToTensor()
)
test_loader = data.DataLoader(
dataset = test_data, batch_size=64, shuffle=True,drop_last=True
)
'''
搭建RNN分类器
'''
class RNN(nn.Module):
def __init__(self,input_dim,hidden_dim,layer_dim,output_dim):
super(RNN, self).__init__()
self.hidden_dim = hidden_dim #RNN神经元个数
self.layer_dim = layer_dim #RNN的层数
self.rnn = nn.RNN(input_dim,hidden_dim,layer_dim,batch_first=True,nonlinearity='relu')
self.fc1 = nn.Linear(hidden_dim,output_dim)
def forward(self,x):
## x:[batch,time_step,input_dim]
## 本例中time_step=图像所有像素数量/input_dim---就是28
## out:[batch,time_step,output_size]
## h_n:[layer_dim,batch,hidden_dim]
out,h_n = self.rnn(x,None) ##None表示h0会使用全0进行初始化
## 选取最后一个时间点的out输出
out = self.fc1(out[:,-1,:])
'''
这块需要debug好好了解一下out维度的变化和全连接层连接的是什么
'''
return out
input_dim = 28 #图片每行的像素数量
hidden_dim = 128 #RNN神经元个数
layer_dim = 1 #RNN的层数
output_dim = 10 #隐藏层的输出维度(10类图像)
my_RNN = RNN(input_dim, hidden_dim, layer_dim, output_dim)
print(my_RNN)
'''
RNN分类器的训练与预测
对定义好的网络模型使用训练集进行训练,需要定义优化器和损失函数,优化器使用torch.optim.RMSprop()定义,
损失函数则使用交叉熵nn.Cross.EntropyLoss()函数定义,并且使用训练集对网络训练30个epochs
'''
optimizer = torch.optim.RMSprop(my_RNN.parameters(),lr=0.0001)
criterion = nn.CrossEntropyLoss()
train_loss_all = []
train_acc_all = []
test_loss_all = []
test_acc_all = []
num_epoch = 30
for epoch in range(num_epoch):
print('Epoch{}/{}'.format(epoch,num_epoch-1))
my_RNN.train() #设置模型为训练模式
corrects = 0
train_num = 0
for step,(b_x,b_y) in enumerate(train_loader):
##input:[batch, time_step, input_dim] b_x:[64,1,28,28] b_y:[64] 是为什么,为什么要分成两个 b_x是特征,b_y是标签
xdata = b_x.view(-1,28,28)
# xdata:[64,28,28],view可以把四维转化为三维吗。 当然可以
output = my_RNN(xdata)
#output:[64,10] 二维
pre_lab = torch.argmax(output,1)
'''对于max这一步还是不懂 ,argmax得到的是最大值的序号索引,与max的区别是只返回索引,max都返回''' #pre_lab Tensor:64 torch.argmax(input,dim)
## dim=1 意味着要求每行最大的列标号
loss = criterion(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss += loss.item() * b_x.size(0)
corrects += torch.sum(pre_lab == b_y.data)
train_num += b_x.size(0) #size(0)的意思是第0维的数据总量,b_x.size(0) : 64
##计算经过一个epoch的训练集上的损失和精度
train_loss_all.append((loss / train_num).detach().numpy())
train_acc_all.append((corrects/train_num).detach().numpy())
print('{}Train Loss:{:.4f} Train Acc:{:.4f}'.format(
epoch, train_loss_all[-1], train_acc_all[-1]
))
###[-1]的原因是要显示每一轮最新的loss和acc
##设置模型为验证模式
my_RNN.eval()
corrects = 0
test_num = 0
for step,(b_x,b_y) in enumerate(test_loader):
## input : [batch,time_step,input_dim]
xdata = b_x.view(-1,28,28)
output = my_RNN(xdata)
pre_lab = torch.argmax(output,1)
loss = criterion(output,b_y)
loss += loss.item() * b_x.size(0)
corrects += torch.sum(pre_lab == b_y.data)
test_num += b_x.size(0)
##计算经过一个epoch的训练后在测试集上的损失和精度
test_loss_all.append((loss / test_num).detach().numpy())
test_acc_all.append((corrects/test_num).detach().numpy())
print('{} Test Loss {:.4f} Test Acc:{:.4f}'.format(
epoch, test_loss_all[-1], test_acc_all[-1]
))
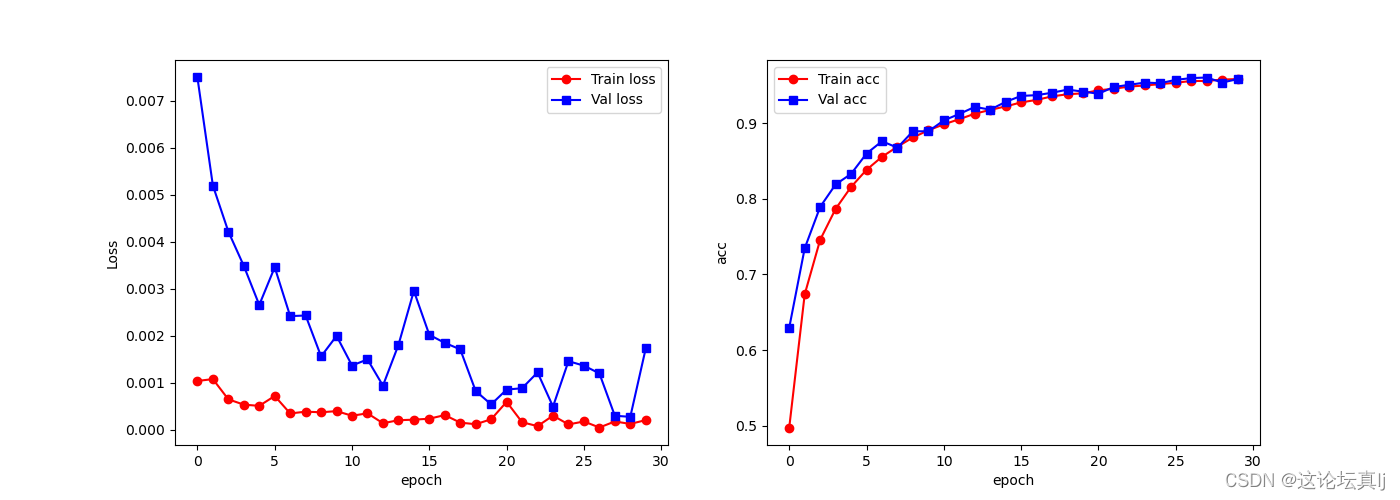
plt.figure(figsize=(14,5))
plt.subplot(1,2,1)
plt.plot(train_loss_all,'ro-',label = 'Train loss')
plt.plot(test_loss_all,'bs-',label = 'Val loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('Loss')
plt.subplot(1,2,2)
plt.plot(train_acc_all,'ro-',label = 'Train acc')
plt.plot(test_acc_all,'bs-',label = 'Val acc')
plt.xlabel('epoch')
plt.ylabel('acc')
plt.legend()
plt.show()
通过这个实验,搞清楚了RNN神经网络的输入和输出维度的变化,掌握了训练过程。
下一步工作:
1、应该掌握如何构建dataset,把想要输入神经网络的数据维度捋清楚。搞清楚dataset类和dataloader,这是神经网络最核心的东西。
2、搞清楚模型的保存和加载,因为在大模型训练的时候需要经过一些epoch后将模型和参数进行保存。
3、找一个好的模板将训练、验证过程打包成函数,直接调用。画图函数也需要打包成函数。
总结收获:
1、搞清楚了rnn的内部运算

2、搞清楚了rnn的数据是怎么流动的,层与层是怎么连接的
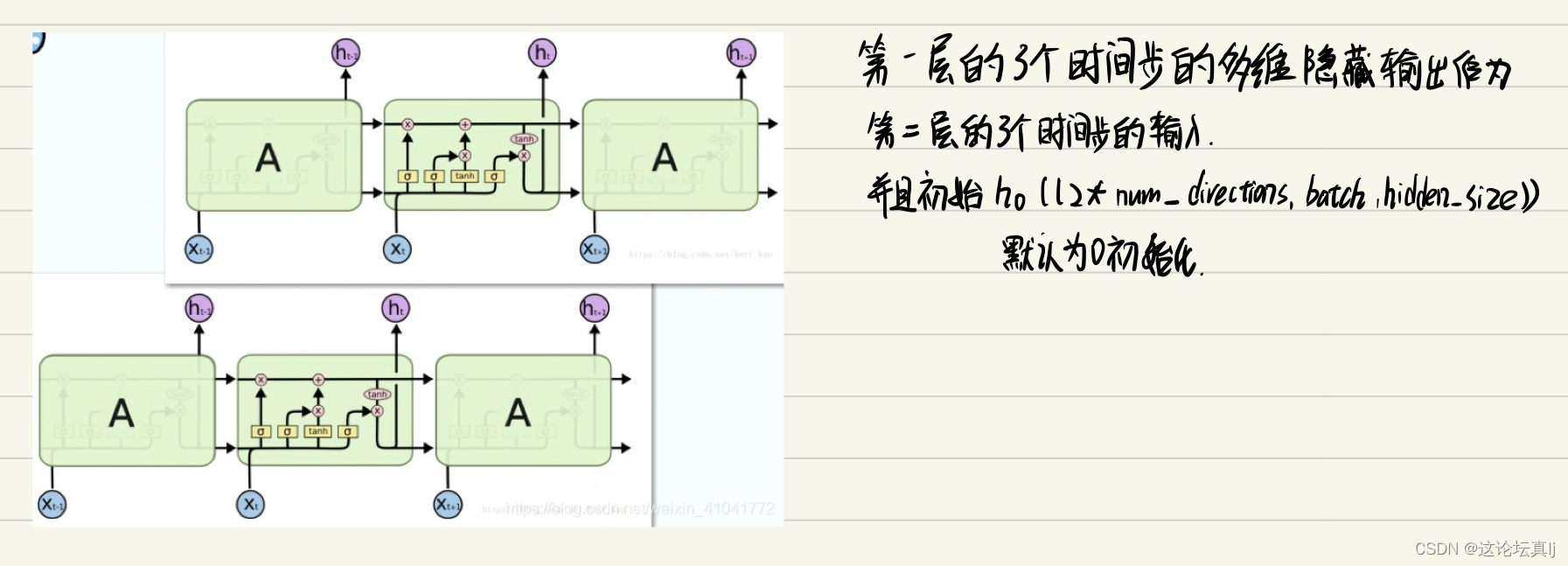
3、训练过程中的loss和acc怎么求,之前一直有几句代码没有搞懂,尤其是argmax那里。 














 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









