






0.前言
两年前开始接触深度学习,一直到现在都是处于一种又懂又懵的状态。学得一知半解了,准备做遥感图像分割,又因为种种原因,转成NLP做文本处理。Anyway,学什么不是学。
从此文开始,开始记录自己整个完整的学习过程,包括我学习的内容,我的理解以及我的不解,从零到项目完结。
1.循环神经网络(RNN)
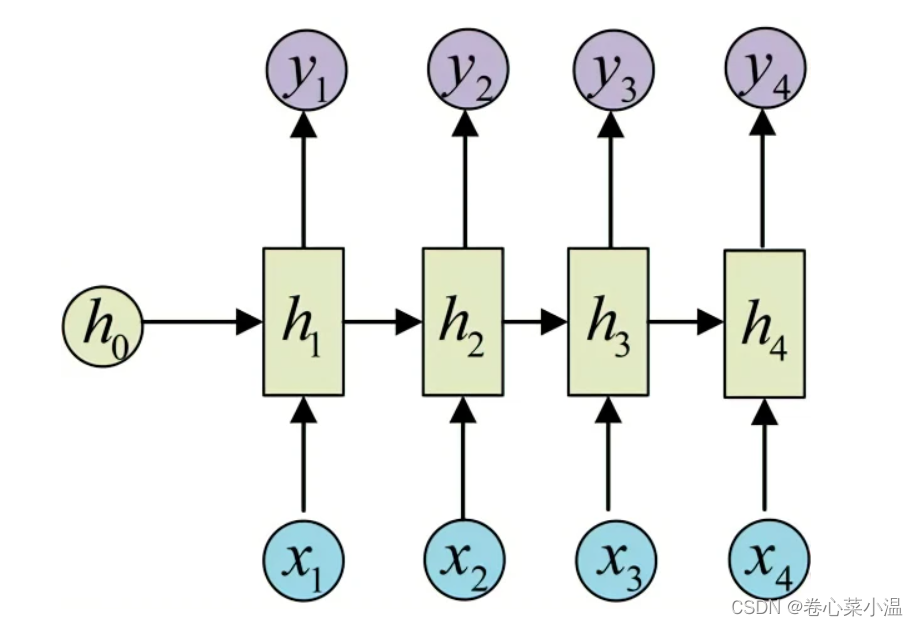
如上图所示,是典型的RNN结构,对此,我的理解为,其相较于其它网络而言,多了一个隐藏状态,yt时刻的输出,是由ht-1时刻数据与xt-1时刻输入共同决定的。
2.RNN应用于MNIST识别
这里提一句,一般RNN都是用于处理文本数据或者序列数据,为什么这里可以用来处理图像,是因为一张图像可以看作一组由很长的像素点组成的序列。
2.1导入所需要的包
##导入所需的包
import torch
from torch import nn
import torchvision
import torch.utils.data as Data
from torchvision import transforms2.2准备数据
这里我们直接利用torchvision.datasets加载MNIST数据集,加载训练集就将train设置为True,训练集则为False;如果是第一次加载数据集请设置download为True。
定义一个数据加载器,用于按设定好的批量(batch_size)读取MNIST数据,shuffle是问是否打乱来选取数据,num_workers是问用几个进程来读取,这边建议填0(因为我填2报错了)。
train_data = torchvision.datasets.MNIST(root="./data/MNIST",train=True,transform=transforms.ToTensor(),download=True)
train_loader = Data.DataLoader(dataset=train_data,batch_size=64,shuffle=True,num_workers=0)
test_data = torchvision.datasets.MNIST(root="./data/MNIST",train=False,transform=transforms.ToTensor(),download=True)
test_loader = Data.DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0)2.3搭建RNN分类器
首先我们搭建一个我们自己的RNNimc分类器,这个类继承了nn.Module这个父类,对此,我的理解是,继承了父类,很多父类定义的方法,属性在我们自己的类上也可以使用,比如初始化参数。这个类里需要我们输入的参数有四个:input_dim(输入的维度,图片中每行的数据像素点量),hidden_dim(隐藏状态的维度),layer_dim(RNN的层数),output_dim(输出的维度,在这里也就是要分成几类)。
整个模型包括两层:RNN层和全连接层。
class RNNimc(nn.Module):
def __init__(self,input_dim,hidden_dim,layer_dim,output_dim):
super(RNNimc,self).__init__() #对继承自nn.Module的属性进行初始化,并且用nn.Module的初始化方法初始化继承的属性
self.hidden_dim = hidden_dim
self.layer_dim = layer_dim
##RNN
self.rnn = nn.RNN(input_dim,hidden_dim,layer_dim,batch_first=True,nonlinearity="relu")
##全连接层
self.fc1 = nn.Linear(hidden_dim,output_dim)
def forward(self,x):
out,h_n = self.rnn(x,None) #None:初始的隐藏层输出为0
out = self.fc1(out[:,-1,:])
return out2.4模型实例化
设置好我们之前设定好的四个参数的值,实例化RNNimc。
input_dim = 28 #因为MNIST数据集里的图片是28×28的图,所以,输入为28,相当于每次的输入是图片的一行
hidden_dim = 128 #这个就随意了吧
layer_dim = 1 #模型的层数(除开最后的全连接层)
output_dim = 10 #因为最后识别的是0-9这10种数字,所以相当于分为10类
MyRNNimc = RNNimc(input_dim,hidden_dim,layer_dim,output_dim) #将上述参数传入RNNimc完成实例化实例化后,我们可以打印出来看一下。RNN层包含128个神经元,而全连接层也包含128个神经元,输出为10。

2.5训练模型
2.5.1前期准备
1.准备优化器,这里选用RMSprop,传入的是我们模型可学习的一些参数以及学习率。
2.准备损失函数,用于每次计算损失后更新我们的参数,这里选用交叉熵损失。
3.准备几个空列表用于存储训练集和测试级的损失和准确率。
4.设定好num_epochs,也就是我们需要训练几遍整个数据,我这里设定是20。
optimizer = torch.optim.RMSprop(MyRNNimc.parameters(),lr=0.0003) #优化器的选择
criterion = nn.CrossEntropyLoss() #使用交叉熵损失更新参数
train_loss_all = []
train_acc_all = []
test_loss_all = []
test_acc_all = []
num_epochs = 202.5.2正式训练模型
在一次训练里,将我们的模型设置为训练模式,从之前设置好的数据加载器train_loader里每次拿出b_x(输入)和b_y(标签),然后就是一套熟悉的操作,计算损失,再根据损失计算梯度,用优化器优化参数,然后将损失和精度累加,累加后除以训练的样本大小就得到了经过一个epoch训练后在训练集上的损失和精度。
(这部分我大概懂在做一件什么事,但是细看代码,还是有很多细节不太懂,懂的我都写了注释,当然也可能理解有错,剩下的关于损失和训练次数的累计还是有点麻,最后反正就返回了一次epoch的损失和精度。)
for epoch in range(num_epochs):
print("Epoch{}/{}".format(epoch,num_epochs - 1))
MyRNNimc.train() ##设置模型为训练模式
corrects = 0
train_num = 0
for step,(b_x,b_y) in enumerate(train_loader):
xdata = b_x.view(-1,28,28) #将我们的输入reshape,方便传入网络
output = MyRNNimc(xdata) #输出为x通过网络的结果
pre_lab = torch.argmax(output,dim=1) #找出这个一维向量(按行)里面最大值的索引。可以理解为,输出是一个1×10的向量,每个数值都是其是0-9数字的概率,找到概率最大的就是其预测的值
loss = criterion(output,b_y) #计算输出与真实值的损失函数
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss += loss.item()*b_x.size(0)
corrects += torch.sum(pre_lab == b_y.data)
train_num += b_x.size(0)
##计算经过一个epoch的训练后在训练集上的损失和精度
train_loss_all.append(loss/train_num)
train_acc_all.append(corrects.double().item()/train_num)
print("{} Train Loss:{:.4f} Train Acc:{:.4f}".format(epoch,train_loss_all[-1],train_acc_all[-1]))2.5.3在测试集上验证训练好的模型
将我们的模型设置为验证模式,依次从test_loader里取出b_x和b_y,在验证的时候我们就不再利用优化器进行优化,而是直接用我们的模型对输入进行预测后与标签对比计算损失就可以了。用相同的方法累计我们的损失和精度,然后求平均得到我们一次epoch在训练集上的损失和精度。
##设置为验证模式
MyRNNimc.eval()
corrects = 0
test_num = 0
for step,(b_x,b_y) in enumerate(test_loader):
xdata = b_x.view(-1,28,28)
output = MyRNNimc(xdata)
pre_lab = torch.argmax(output,1)
loss = criterion(output,b_y) #计算输出与真实值的损失函数
loss += loss.item()*b_x.size(0)
corrects += torch.sum(pre_lab == b_y.data)
test_num += b_x.size(0)
##计算经过一个epoch的训练后在训练集上的损失和精度
test_loss_all.append(loss / test_num)
test_acc_all.append(corrects.double().item() / test_num)
print("{} Test Loss:{:.4f} Test Acc:{:.4f}".format(epoch, test_loss_all[-1], test_acc_all[-1]))2.5.4训练过程及结果
首先打印的是:当前的epoch/总的epoch次数。
每次epoch打印一次在训练集上的损失和精度、测试集上的损失和精度。
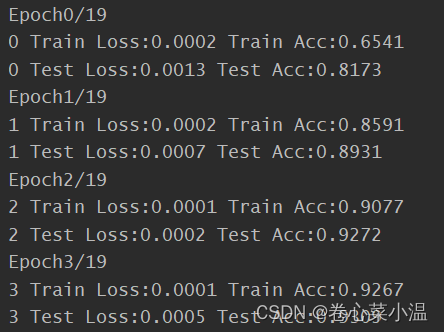
可以看到前三次epoch无论是在训练集还是测试集上,其精度都低于95%
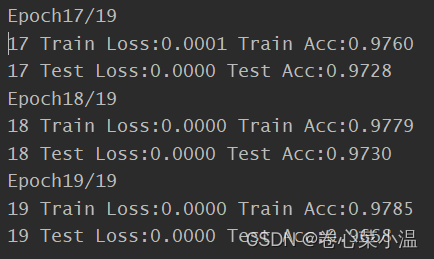
再看看最后三次,可以看出,随着训练次数的增多,损失都快接近于0了,精度也都提高到了97%。书上num_epoch设置为30次,其得到的精度比我的更高一点,几乎稳定在98%左右。
3.总结
ok,到这里也算差不多结束了。另外该教程中还有两个可视化的写法,我这里就没有再提及,我也没有试过(问就是,试过,但是好像因为版本不对要报错,我就懒得调试了,后面有时间和需求再做吧)















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









