









参考代码:https://github.com/Lam1360/YOLOv3-model-pruning
https://github.com/coldlarry/YOLOv3-complete-pruning,剪枝代码解读
https://github.com/tanluren/yolov3-channel-and-layer-pruning
无人机数据集案例:https://blog.csdn.net/weixin_41397123/article/details/103828931
yolov5剪枝:https://github.com/ZJU-lishuang/yolov5_prune
剪枝原理:https://openaccess.thecvf.com/content_iccv_2017/html/Liu_Learning_Efficient_Convolutional_ICCV_2017_paper.html
论文解读:https://blog.csdn.net/h__ang/article/details/89376079
剪枝原理
模型部署的三大挑战
1.模型大小:CNN优异的性能表现来源于上百万可训练的参数。那些参数和网络结构信息需要被存储到硬盘,然后在推理期间加载到内存中。模型较大对于嵌入式设备来说是一个很大的负担;
2.运行时占用内存:在推理期间,CNN的中间激活值/响应存储空间甚至需要比存储模型参数的大,即使batchsize是1.这对于高性能的GPU来说不是问题,但对于低计算能力的许多应用来说这是不可承担的;
3.计算量:在高分辨率图片上卷积操作可能会计算密集,一个大的CNN在嵌入式设备上可能要花费几分钟来处理一张单个图片,这使得在真实应用中采用很不现实;
剪枝相关解决方法
1.权重剪枝/稀疏化
“Learning both weights and connections for efficient neural network.”论文提出了在训练网络中剪枝掉不重要的连接关系,这样的话网络中的权重大多数变成了0,可以使用一种稀疏的模式存储模型。然而,这些方法需要专门的稀疏矩阵运算库或硬件来做加速,运行时的内存占用节省非常有限,因为产生的激活值仍然是密集的。
2.结构剪枝/稀疏化
"Pruning filters for efficient convnets"提出了在训练CNNs时剪枝通道,然后通过微调来恢复精度;"The power of sparsity in convolutional neural networks"在训练之前,通过随机抛弃channel-wise的连接引入稀疏化,也得到了一个更小的网络,我们的方法将简单的L1稀疏化强加到channel-wise的缩放因子上,优化目标更加简单。
由于这些方法都是对网络结构的(channels,neurons等)一部分做剪枝或稀疏化,而不是对个别权重,因此它们不太需要特别的库来实现推理加速和运行时的内存节省。我们的网络瘦身就属于这个类别,完全不需要其他的特定库支撑。
channel-wise稀疏化的优势
稀疏化可以在不同级别实现(weight-level,kernel-level,channel-level,layer-level)。细粒度的稀疏化(weight-level)由最高的灵活性和泛化性能,也能获得更高的压缩比率,但是它通常需要特殊的软硬件加速器才能在稀疏模型上快速推理。相反,粗粒度 layer-level稀疏化不需要特殊的包做推理加速,但是它灵活性上不如细粒度。事实上,只有深度足够深(超过50层),移除某些层才会很高效。相比之下,channel-wise稀疏化在灵活性和实现上做了一个平衡,它可以被应用到任何典型的CNN或者全连接层(将每个神经元看作一个通道),由此得到的网络本质上也是一个瘦的网络,可以在卷积CNN平台上快速推理。
缩放因子和稀疏性惩罚
我们的注意是对每一个通道都引入一个缩放因子γ,然后与通道的输出相乘。接着联合训练网络权重和这些缩放因子,最后将小缩放因子的通道直接剪除,微调剪枝后的网络。特别地,我们的方法的目标函数定义为,g(s)=|s|,即L1正则化:
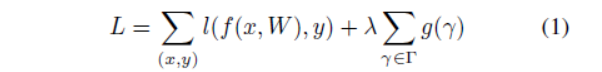
利用BN层的缩放因子

BN之所以称之为batch,就是因为normalization只沿batchsize维度进行,即N维。具体而言,就是针对每一个channel(也可以认为是对每一个神经元的输出),对batchsize求均值方差,对MLP而言,均值方差的求解是显而易见的;对2D CNN而言,就是将该channel对应的batchsize个维度为(H, W)的tensor求解出一对均值方差,对这batchsize个(H, W)的tensor,其每一个pixel value减去该均值并除以该方差。总而言之,就是normalization只在batch维进行,相应的gamma和beta也都是长度为channel_num的向量。

剪枝和微调
通道剪枝和微调:引入缩放因子正则项之后,我们得到的模型中许多缩放因子都会趋于0。然后我们剪掉接近零的缩放因子对应的通道,剪掉小的γ对应的通道实质上就是直接剪掉这个feature map对应的卷积核。至于什么样的γ算小的呢?这个取决于我们为整个网络所有层设置的一个全局阈值,它被定义为所有缩放因子值的一个比例,比如我们将剪掉整个网络中70%的通道,那么我们先对缩放因子的绝对值排个序,然后取从小到大排序的缩放因子中70%的位置的缩放因子为阈值,通过这样做,我们就可以得到一个较少参数、运行时占内存小、低计算量的紧凑网络。
为什么L1比L2更有稀疏的作用
https://baijiahao.baidu.com/s?id=1621054167310242353&wfr=spider&for=pc
1.数据计算角度
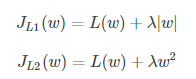
假设L(w)在0处的倒数为d0
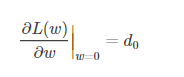
L1在0出的导数
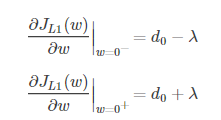
L2在0处的导数
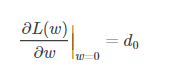
引入L2正则时,代价函数在0处的导数仍是d0,无变化。而引入L1正则后,代价函数在0处的导数有一个突变。从d0+λ到d0−λ,若d0+λ和d0−λ异号,则在0处会是一个极小值点。因此,优化时,很可能优化到该极小值点上,即w=0处
2.数据先验角度
当先验分布是拉普拉斯分布时,正则化项为L1范数;当先验分布是高斯分布时,正则化项为L2范数。

三个项目小结
yolov3结构

darknet结构

v1
https://github.com/Lam1360/YOLOv3-model-pruning
在oxford hand数据集上,对yolov3通道裁剪,其中Darknet53上的shortcut结构不裁剪
v2
https://github.com/coldlarry/YOLOv3-complete-pruning
1.在v1项目的基础上增加裁剪方式,支持Tiny版本的裁剪:

2.支持多卡训练
3.支持apex混合精度加速
4.支持任意bit量化
v3
https://github.com/tanluren/yolov3-channel-and-layer-pruning
1.增加对yolov3-spp结构的支持
2.增加多尺度推理
3.增加知识蒸馏一:蒸馏是用高精度的大模型指导低精度的小模型,在结构相似的情况下效果尤为明显。而剪枝得到的小模型和原模型在结构上高度相似,非常符合蒸馏的应用条件。这里更新了一个参考Hinton大神Distilling the Knowledge in a Neural Network的蒸馏策略,原策略是针对分类模型的,但在这里也有不错的表现。
4.增加了针对蒸馏的混合精度训练支持,项目中各项训练都可以使用apex加速,但需要先安装。使用混合精度可以加速训练,同时减轻显存占用,但训练效果可能会差一丢丢。代码默认开启了混合精度,如需关闭,可以把train.py中的mixed_precision改为False.
5.增加知识蒸馏二,参考了论文"Learning Efficient Object Detection Models with Knowledge Distillation",相比策略一,对分类和回归分别作了处理,分类的蒸馏和策略一差不多,回归部分会分别计算学生和老师相对target的L2距离,如果学生更远,学生会再向target学习,而不是向老师学习。调用同样是指定老师的cfg和权重即可。需要强调的是,蒸馏在这里只是辅助微调,如果注重精度优先,剪枝时尽量剪不掉点的比例,这时蒸馏的作用也不大;如果注重速度,剪枝比例较大,导致模型精度下降较多,可以结合蒸馏提升精度。
6.更新了两种稀疏策略:恒定s,全局s衰减,局部s衰减。
7.[无人机数据集visdrone案例]。(https://blog.csdn.net/weixin_41397123/article/details/103828931)
8.增加支持yolov4、yolov4-tiny剪枝。
9.支持负样本训练。
10.剪枝策略:①对shortcut直连的层不进行剪枝②对涉及shortcut的卷积层也进行了剪枝③改进对涉及shortcut的卷积层的改进策略,先以全局阈值找出各卷积层的mask,然后对于每组shortcut,它将相连的各卷积层的剪枝mask取并集,用merge后的mask进行剪枝,这样对每一个相关层都做了考虑,同时它还对每一个层的保留通道做了限制,实验中它的剪枝效果最好。在本项目中还对激活偏移值添加了处理,降低剪枝时的精度损失。
11.层剪枝
这个策略是在之前的通道剪枝策略基础上衍生出来的,针对每一个shortcut层前一个CBL进行评价,对各层的Gmma均值进行排序,取最小的进行层剪枝。为保证yolov3结构完整,这里每剪一个shortcut结构,会同时剪掉一个shortcut层和它前面的两个卷积层。是的,这里只考虑剪主干中的shortcut模块。但是yolov3中有23处shortcut,剪掉8个shortcut就是剪掉了24个层,剪掉16个shortcut就是剪掉了48个层,总共有69个层的剪层空间;实验中对简单的数据集剪掉了较多shortcut而精度降低很少。
12.同时剪层和剪通道
个人小结
1训练
①稀疏化训练,tensorboard可视化BN的γ数值,便于观察稀疏化。
②大的s一般稀疏较快但精度掉的快,小的s一般稀疏较慢但精度掉的慢;配合大学习率会稀疏加快,后期小学习率有助于精度回升。
③稀疏策略:恒定的稀疏因子;全局衰减的稀疏因子;局部衰减的稀疏因子。
2剪枝
①全局阈值(BN层γ阈值)选取需要注意的:对于仅剪枝不剪层的,上述所提到全局阈值需要考虑是否会减掉某一层的全部通道,即要求每一层的每个通道的最大值的最小值。
②对于不剪层的方法,可以设置每一层最少保留的通道数,避免全部层被剪掉。
③对于剪层的模型,可以对需要剪得每一层每个通道BN的γ求平均,对整体层进行排序,剪切掉N个不用的层,以达到剪枝的目的。
④剪层和剪模型可以同时进行,剪层可以指定剪某一类别的层,剪枝可以剪特定类别的层,如可以剪yolov3中的shortcut部分。
3最优模型选择:
优先调剪枝比例,再调layer_keep0,最后调剪层个数(可选),如果剪层掉点太多可以不剪层
实践中难点
1.网络设计:如果是通过配置文件设计网络,可以比较容易得到BN层的index,便于后面剪枝
2.网络本身,如果出现shortcut、concat、其他连接比较复杂的网络结构,需要考虑的比较多,有些能剪有些不能剪(或者不容易剪)
3.定义哪些层的通道可以剪,哪些层的通道不可以剪。















 6085
6085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









