










论文:https://www.cs.utexas.edu/~sniekum/classes/RL-F17/papers/Meta.pdf
代码:
tensorflow(官方):https://github.com/cbfinn/maml
pytorch:https://github.com/dragen1860/MAML-Pytorch、https://github.com/Miaotxy/my_pytorch_maml
解析:https://blog.csdn.net/weixin_37589575/article/details/93969335、https://www.zhihu.com/question/266497742
相关想法:目标跟踪≈目标检测+小样本学习:https://zhuanlan.zhihu.com/p/142217115
什么是元学习?
文章提出了一种新的元学习 (Meta-learning) 的算法,这种算法与模型无关,从某种意义上说,它可以直接应用于使用梯度下降过程训练的任何学习问题和模型,可以用于大量的学习问题,比如分类、回归和强化学习等。元学习的目标是使用大量的学习任务来学习模型,使得模型可以仅仅使用少量的训练样本就可以解决新的任务。模型的参数被显式的训练,目的是希望使用来自新任务的少量的训练数据然后进行几步梯度下降就可以在这个新任务上取得很好地泛化性能。实际上,目的是为模型学习一个易于微调的初始化参数。
介绍
模型的特点(优点):
MAML 不会大量增加学习的参数(其实理论上只增加一个参数 – 元学习率)
MAML 不会对模型进行任何限制,只限制训练的方法是梯度下降。
MAML 可以用于大量的损失函数,比如可微的监督损失,不可微的强化学习目标。
1.特征学习的角度:学习建立一个适应于各种不同任务的内在表示。如果这个内在表示可以适用于大量的任务,那么简单地微调这个参数就可以产生好的结果。实际上,就是想要模型的初始化参数易于快速微调。
2. 从动态系统的角度:最大化新任务的损失函数对于参数的灵敏度,这样如果灵敏度高,对参数的简单的局部调整可以大大改善任务的损失。
算法
一次梯度下降:
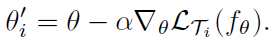
上面只是在一个任务上更新了参数,时时刻刻记住我们的想法:训练模型的初始化参数,使得模型在新的任务上使用很少的样本,进行一次或几次梯度下降就可以取得最大化的表现。学习的初始化参数(内在特征表示)应该适用于大量的各种的任务,而不是单单某一个任务。
元目标如下:
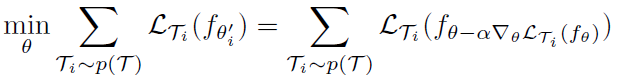
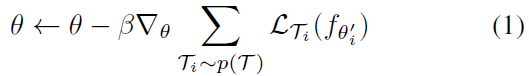

注意:这算法只是 meta-training 的算法,如果要进行 meta-testing 还需要在新任务上的 Support Set (支持集)进行微调 – 因为我们仅仅训练的一个适合于大量任务的初始化参数。你想得到适合这个新任务的某一特定参数,还需要用这个任务的支持集来微调。
















 659
659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









