







LightGBM主要改进点:
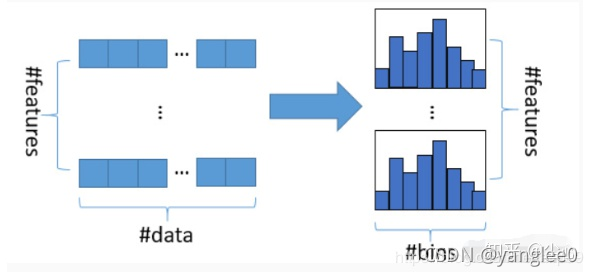
- 直方图算法: 其基本思想是先把连续的浮点特征值离散化成k个整数(其实又是分桶的思想,而这些桶称为bin,比如[0,0.1)→0, [0.1,0.3)→1),同时构造一个宽度为k的直方图。
在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。

-
带深度限制的Leaf-wise的叶子生长策略
在XGBoost中,树是按层生长的,称为Level-wise tree growth,同一层的所有节点都做分裂,最后剪枝,如下图所示xgboost生长: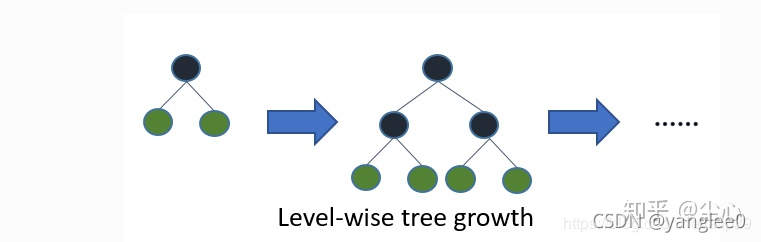
xgboost是按层生长的,同时分裂同一层的叶子,这样的好处是不容易过拟合;但是实际增加了很多不必要的开销,很多叶子的分裂增益较低,没有必要进行搜索和分裂。
而lightGBM在直方图算法的基础上,进一步优化,找到分裂增益最大的 一个叶子,然后分裂,如此循环。但是在这样容易导致树过深,产生过拟合,也因此LightGBM增加了一个最大深度的限制,保证高效的同时防止过拟合。

-
直方图差加速 右 直方图= 父-左
在树中,一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。 -
直接支持类别特征
一般算法,需要把类别特征转化到多维的0/1特征,然而会降低了空间和时间的效率。 LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。
LightGBM的优缺点:
-
优点:
1)速度较快,是XGBoost速度的16倍,内存占用率为XGBoost的1/6
2)采用了直方图算法,将连续的浮点型特征值离散化成K个整数
3)使用带有深度限制的leaf-wise的叶子生长策略。 -
缺点:
1)可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度限制,在保证高效率的同时防止过拟合
2)基于偏差的算法,会对噪点较为敏感
3)在寻找最优解时,依据的最优切分变量,没有将最优解是全部特征的综合这一理念来考虑
















 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









