







总:基于Transformer的LSTF解决方案
现有基于Transformer的LSTM解决方案设计要素总结如下:
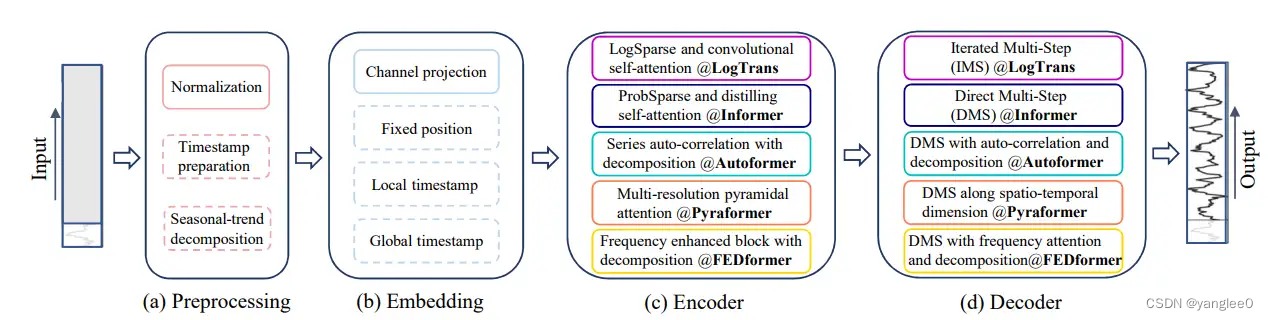
从图中可以看出,Transformer在时序中应用具体包含以下几个步骤:
1)时序分解:对于数据处理,TSF中0均值归一化是比较常见的。此外,还有季节趋势分解预测(Autoformer)。
2)输入嵌入策略:自注意层不能保留位置信息,因此可采用位置embedding,保留位置信息,具体有局部位置信息(数据顺序)、全局信息(年月周等)和其他信息如节假日、大型活动等。对于位置信息的编码有两种:固定embedding和可学习embedding。
3)自注意方案:自注意方案是用来提取成对元素之间的语义依赖。时序对这块的工作主要是两点:减少原始Transformer的计算量和内存量,如采用对数稀疏掩码注意力的LogTrans和采用金字塔注意力的Pyraformer。
4)解码器:IMS:单步迭代预测。DMS:多步预测。
现有基于Transformer的LTSF解决方案(T >> 1)实验中所有被比较的非Transformer模型基线都是IMS预测技术,众所周知,这种策略会受到显著的错误累积效应影响。我们假设,这些模型的性能改进主要是由于其使用了DMS策略。
一、transformer时序预测任务中的缺点:
(1) 通道不独立:对于同一时间步的数据点,它们具有不同物理意义、采集时间可能并不对齐且尺度差异大,强行地将它们编码为统一的temporoal token,不再区分不同的channels。一方面这样编码将导致多变量间的相关性被消除,无法学习以变量为基础的高效表征,并不适合多变量时序预测任务。在部分数据集上,保证变量通道的独立性并考虑不同变量间的互相关是非常有必要的。另一方面由
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









