







 本文详细介绍了如何使用Tesseract OCR引擎进行字符识别训练,包括环境准备、样本制作、字符矫正及训练文件生成等步骤,适合需要提升OCR识别效果的开发者。
本文详细介绍了如何使用Tesseract OCR引擎进行字符识别训练,包括环境准备、样本制作、字符矫正及训练文件生成等步骤,适合需要提升OCR识别效果的开发者。
因图像课程作业需要字符识别,所以采用了tesseract-OCR,但是自带库的效果不太好,所以根据自己的图片尝试进行训练。
tesseract-OCR
Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护。
一、环境准备:
1.JAVA JDK (Java Development Kit即Java语言软件工具开发包)
jTessBoxEditor,运行依赖Java运行时环境,所以需要安装Java虚拟机。
2.jTessBoxEditor
jTessBoxEditor工具,用于调整图片上文字的内容和位置。
1.安装java虚拟机(Java最初是SUN公司,因后来被oracle公司收购)
所以在oracle网站:
java下载地址
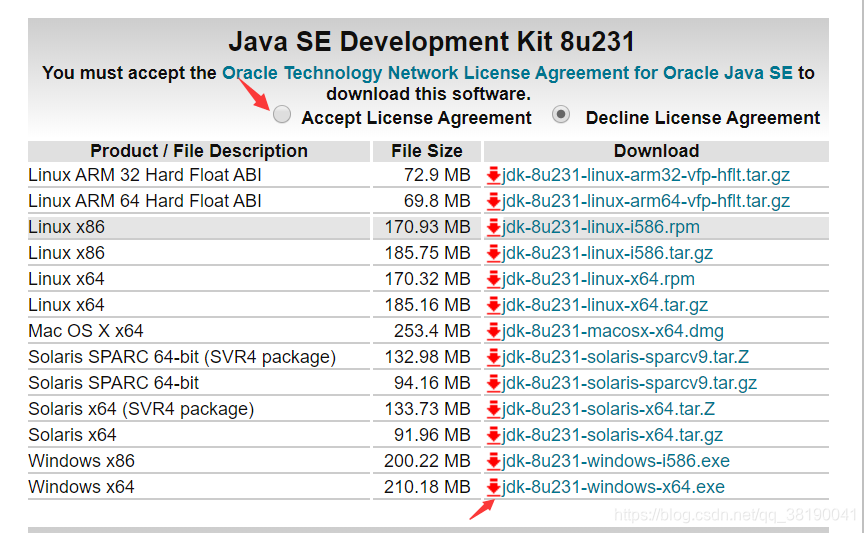
好吧,我下载的时候被强制登录oracle(……没有,还创建了账户)
下载太缓慢,网上重新找了下了个版本
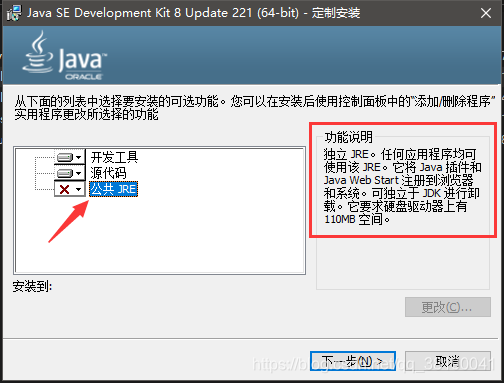
2.配置java环境变量
1、右键我的电脑->属性
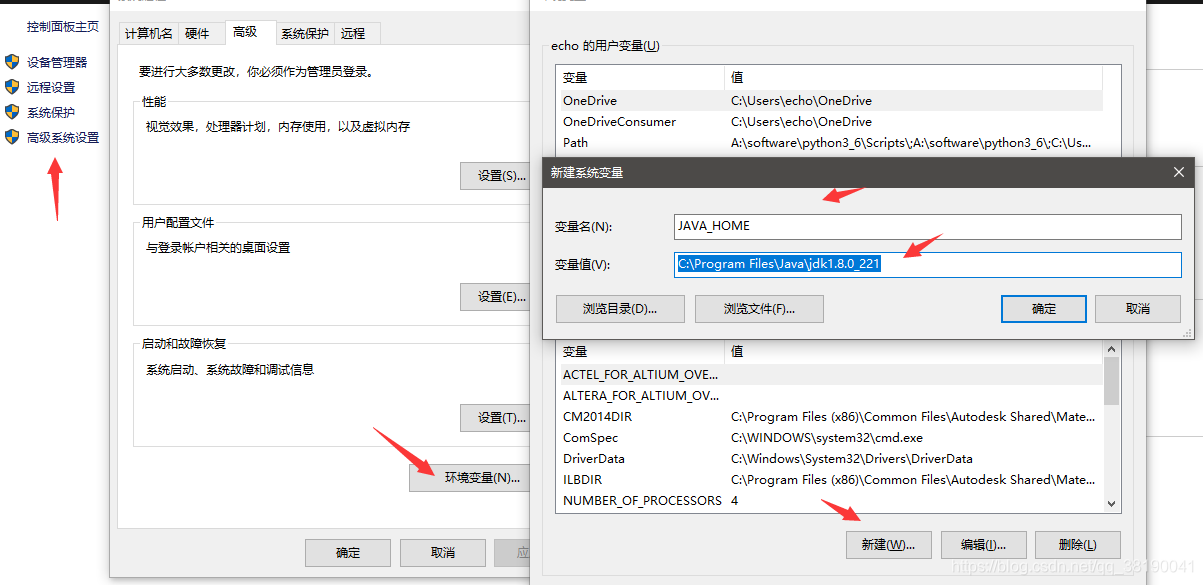
2、找到path
1)然后单击新建,填入%JAVA_HOME%\bin
再新建,填入%JAVA_HOME%\jre\bin
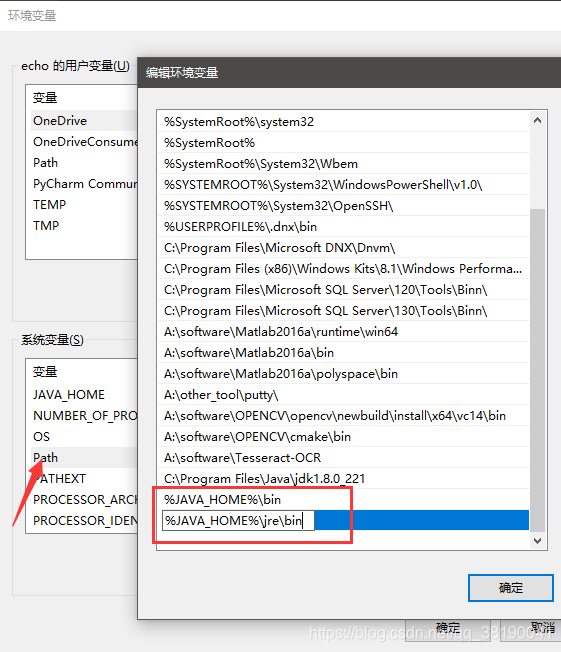
2)新建->变量名:CLASSPATH 变量值:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
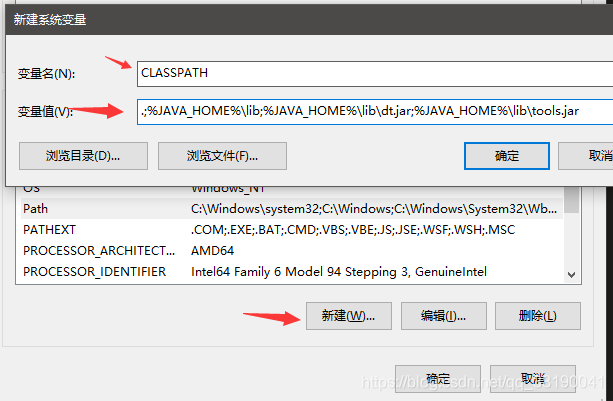
3)重新开机后测试:
在控制台分别输入java、javac、java -version命令,出现如下所示即为配置成功

3.安装jTessBoxEditor
下载地址:jTessBoxEditor
解压后双击
出来这个界面
二、开始训练
1.制作训练样本
我的图片
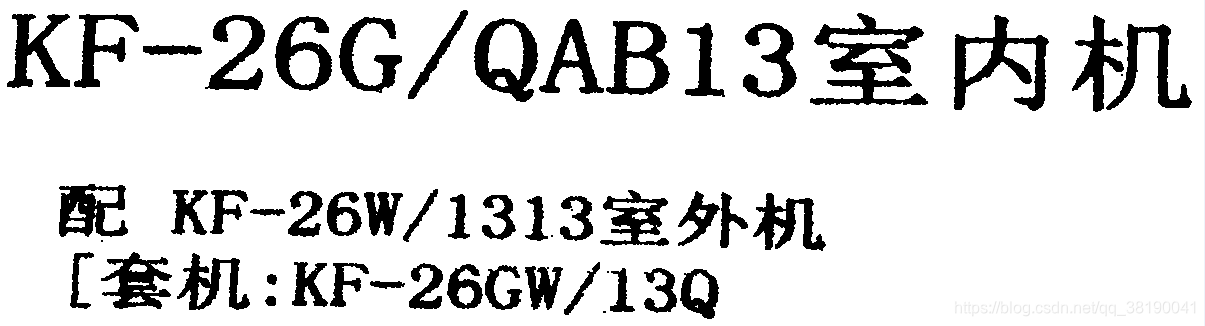
在画图中将png的图片转画为tiff
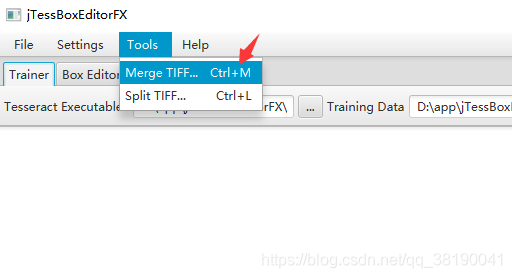
样本文件全部选上,按住Ctrl 键不松,点击打开。
【注意】:这里是没有界面化的提示的,选中后,点击【打开】,立马就是输入合成后的文件名界面,输入char.font.exp0.tif,点击【保存】
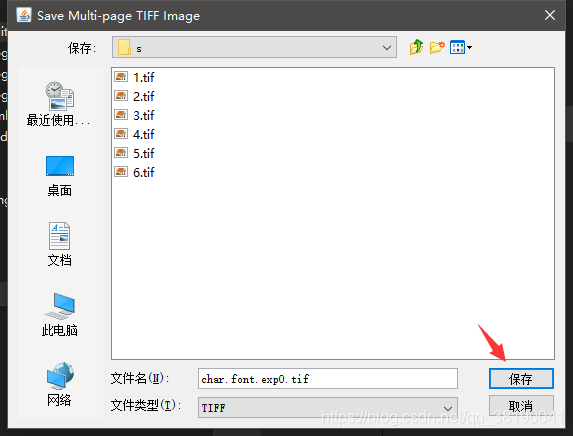
2.生成BOX文件
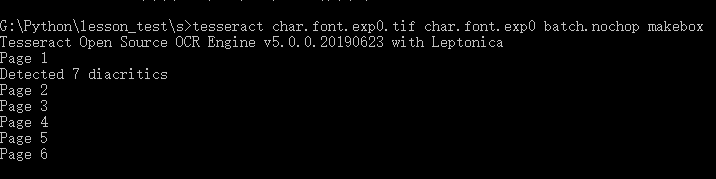
使用cmd(管理员)到char.font.exp0.tif目录
输入下面命令,生成文件名为char.font.exp0.box
tesseract char.font.exp0.tif char.font.exp0 batch.nochop makebox
- tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
- lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式
3.定义字符配置文件
1)新建font_properties
在文件夹文件夹内,新建一个文本文件,名为font_properties,删掉.txt,用记事本打开,写入内容为:
font 0 0 0 0 0
2)
将.tif .box 和font_properties放到一个文件夹中
4.字符矫正
打开 jTessBoxEditor->BOX Editor->Open,打开num.font.exp0.tif;
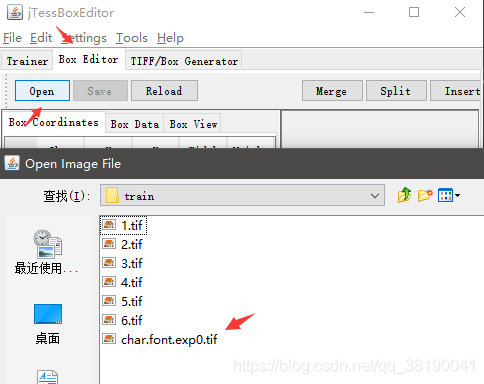
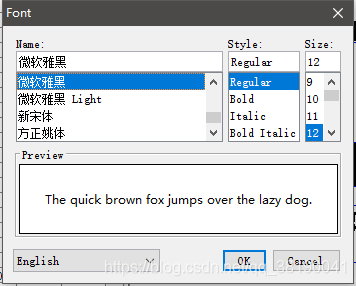
因为有中文,所以需要改字体
在setting>font 设置中文字体
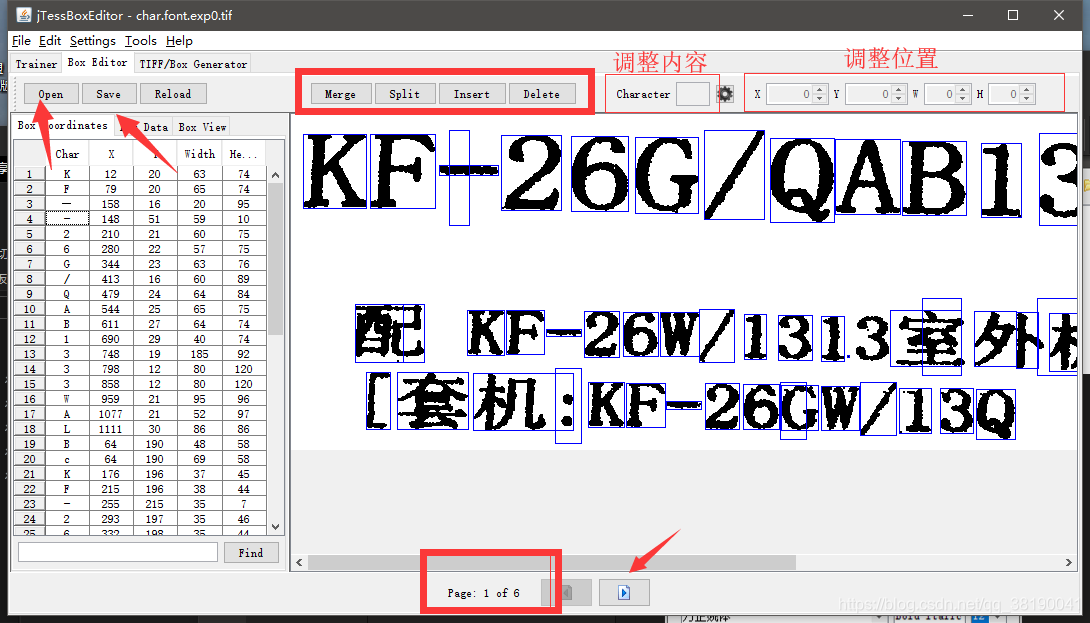
调整字符
注意要调整完所有的图片(page)。
5.使用tesseract生成.tr训练文件
执行下面命令,执行完之后,会在当前目录生成char.font.exp0.tr文件。
tesseract char.font.exp0.tif char.font.exp0 nobatch box.train
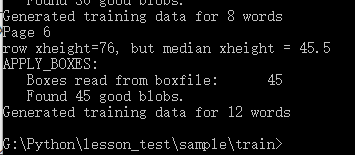
6、生成字符集文件:
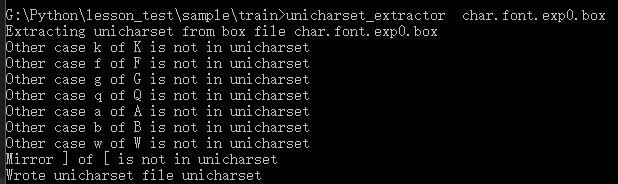
执行下面命令:执行完之后会在当前目录生成一个名为“unicharset”的文件。
unicharset_extractor char.font.exp0.box
7、生成shape文件:
执行下面命令,执行完之后,会生成 shapetable 和 char.unicharset 两个文件。
shapeclustering -F font_properties -U unicharset -O char.unicharset char.font.exp0.tr

8、生成聚字符特征文件:
执行下面命令,会生成 inttemp、pffmtable、shapetable和char.unicharset四个文件。
mftraining -F font_properties -U unicharset -O char.unicharset char.font.exp0.tr

9、生成字符正常化特征文件:
cntraining char.font.exp0.tr

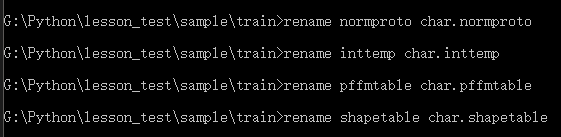
10、文件重命名:
重新命名inttemp、pffmtable、shapetable和normproto这四个文件的名字为[lang].xxx。
这里修改为char.inttemp、char.pffmtable、char.shapetable和char.normproto
执行下面命令:
rename normproto char.normproto
rename inttemp char.inttemp
rename pffmtable char.pffmtable
rename shapetable char.shapetable
11、合并训练文件:
执行下面命令,会生成char.traineddata文件。
combine_tessdata char
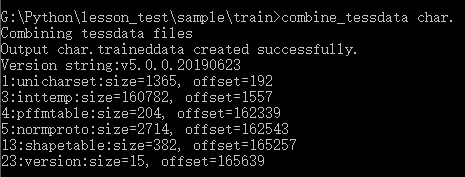
Log输出中的Offset 1、3、4、5、13这些项不是-1,表示新的语言包生成成功。
12、将生成的“char.traineddata”语言包文件复制到Tesseract-OCR 安装目录下的tessdata文件夹中
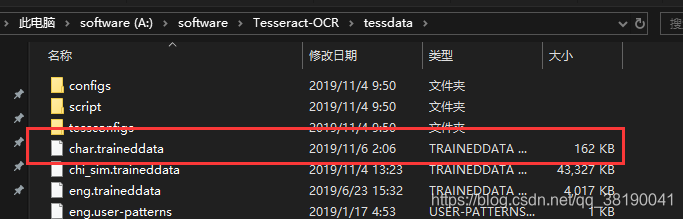
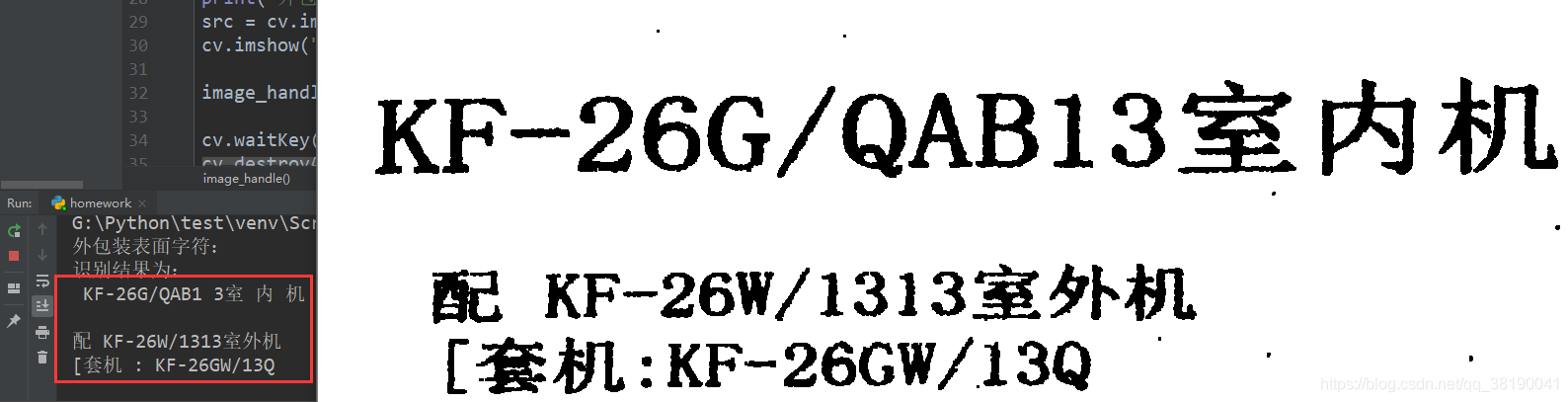
13、测试结果:
代码中引入训练出来的对应的库:
tess.image_to_string(textImage, lang='char')
被抛弃的写随笔公众号改写技术文章了,感兴趣的可以关注公众号:王崇卫



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









