









红外图像是通过红外辐射技术获取的图像。红外辐射是指波长在红外光谱范围内的电磁辐射,因此红外图像可以显示物体在红外波段的热分布情况。红外图像通常用于热成像、夜视、医学诊断等领域。
红外图像的特点是:
- 可以显示物体的热分布情况,即使在暗光或低光条件下也能获取清晰的图像。
- 能够穿透雾霾、烟雾等大气障碍物,适用于复杂环境下的监测和观测。
- 可以探测物体的表面温度差异,用于检测故障设备、热漏点等。
- 在医学领域可以用于体温检测、疾病诊断等。
红外图像具有不同于可见光图像的特殊功能和应用领域,是一种重要的成像技术。因为红外图像与可见光完全不同的显示特性,所以后续还有很多将可见光和红外图像融合的技术,借鉴红外图像在特殊场景下对可见光的补充作用。这个我们后面再聊。今天先来看HCFNet如何实现红外图像中小目标检测功能。
目录

🐸🐸1.摘要
红外小目标检测是一项重要的计算机视觉任务,涉及对红外图像中微小物体的识别和定位,这些图像通常仅包含几个像素。然而,由于物体的体积很小,而且红外图像中的背景通常很复杂,因此遇到了困难。在本文中,我们提出了一种深度学习方法 HCF-Net,该方法通过多个实用模块显著提高了红外小目标检测性能。具体来说,它包括并行补丁感知注意力 (PPA) 模块、维度感知选择性集成 (DASI) 模块和多扩张通道精简器 (MDCR) 模块。PPA 模块使用多分支特征提取策略来捕获不同尺度和级别的特征信息。DASI 模块支持自适应通道选择和融合。MDCR 模块通过多个深度可分离卷积层捕获不同感受野范围的空间特征。在 SIRST 红外单帧图像数据集上的大量实验结果表明,所提出的 HCF-Net 性能良好,优于其他传统模型和深度学习模型。代码可在 https://github.com/zhengshuchen/HCFNet 获取。
代码:code
论文:paper
🙋🙋2.网络结构
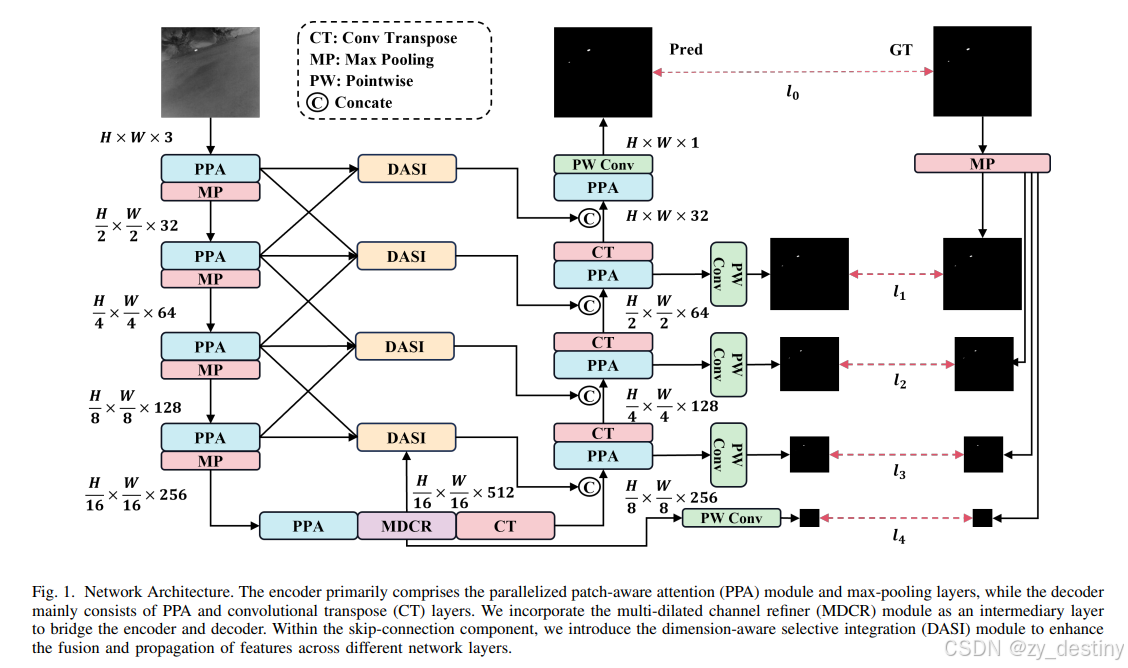
我们将红外小目标检测建模为语义分割问题,并提出了 HCF-Net。
HCFNet是一种用于红外小目标检测的深度学习方法,旨在解决红外图像中小目标检测面临的挑战,如目标尺寸小、背景复杂以及信息在下采样过程中容易丢失等问题。该网络通过将红外小目标检测建模为语义分割问题,提出了一种层次化上下文融合网络(HCF-Net),并引入了三个关键模块:并行化块感知注意力(PPA)模块、维度感知选择性集成(DASI)模块和多扩张通道细化(MDCR)模块。这些模块协同工作,显著提高了红外小目标检测的性能。
HCFNet的整体架构基于改进的U-Net结构,主要由编码器(encoder)和解码器(decoder)组成,其中编码器和解码器的主要组件分别为PPA模块和最大池化层(max-pooling layers),以及PPA模块和转置卷积层(convolutional transpose layers)。MDCR模块作为编码器和解码器之间的中间层,用于连接两者并强化多尺度特征提取。在跳跃连接(skip-connection)部分,引入了DASI模块,以增强不同网络层之间特征的融合和传播。
-
编码器:主要由PPA模块和最大池化层构成,负责对输入图像进行下采样,提取图像的特征表示。
-
中间层(MDCR模块):连接编码器和解码器,通过多扩张率的深度可分离卷积层捕捉不同感受野范围的空间特征,增强特征表示。
-
解码器:主要由PPA模块和转置卷积层构成,负责对编码器提取的特征进行上采样,恢复图像的空间分辨率,并最终生成检测结果。
-
跳跃连接(DASI模块):在编码器和解码器之间建立连接,通过自适应选择和融合高维与低维特征,增强小目标的显著性,提高检测性能。
此外,HCFNet采用了深度监督策略,通过在多个尺度上计算二元交叉熵损失和交并比损失,进一步解决了小目标在下采样过程中容易丢失的问题。
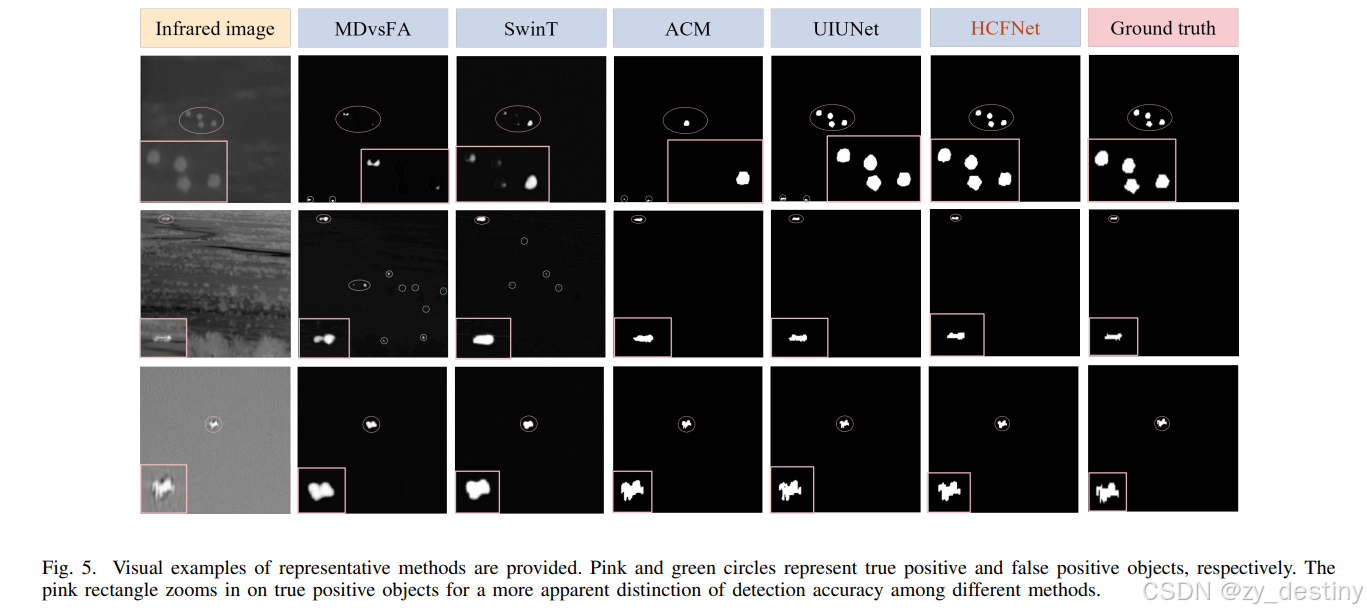
💖💖3.创新点
-
并行化块感知注意力(PPA)模块:通过多分支特征提取策略,PPA模块能够捕捉不同尺度和层次的特征信息。它包含局部、全局和串行卷积分支,通过控制块大小参数(patch size)实现局部和全局特征的提取与交互。此外,PPA还结合了通道注意力和空间注意力机制,进一步增强特征表示,有效缓解了小目标在多次下采样过程中信息丢失的问题。
-
维度感知选择性集成(DASI)模块:DASI模块通过自适应选择高维和低维特征进行融合,解决了高维特征可能丢失小目标信息、低维特征可能缺乏足够上下文的问题。该模块将高维、低维和当前层特征划分为多个通道段,根据目标的大小和特征自适应地选择合适的特征进行融合,从而增强小目标的显著性。
-
多扩张通道细化(MDCR)模块:MDCR模块通过引入多个扩张率不同的深度可分离卷积层,捕捉不同感受野范围的空间特征。这种设计使得网络能够更精细地建模目标与背景之间的差异,增强对小目标的定位能力。MDCR模块还通过通道分割和重组的方式,进一步增强了多尺度特征的多样性,并通过逐点卷积实现轻量且高效的特征聚合。
👍3.1并行化块感知注意力(PPA)模块
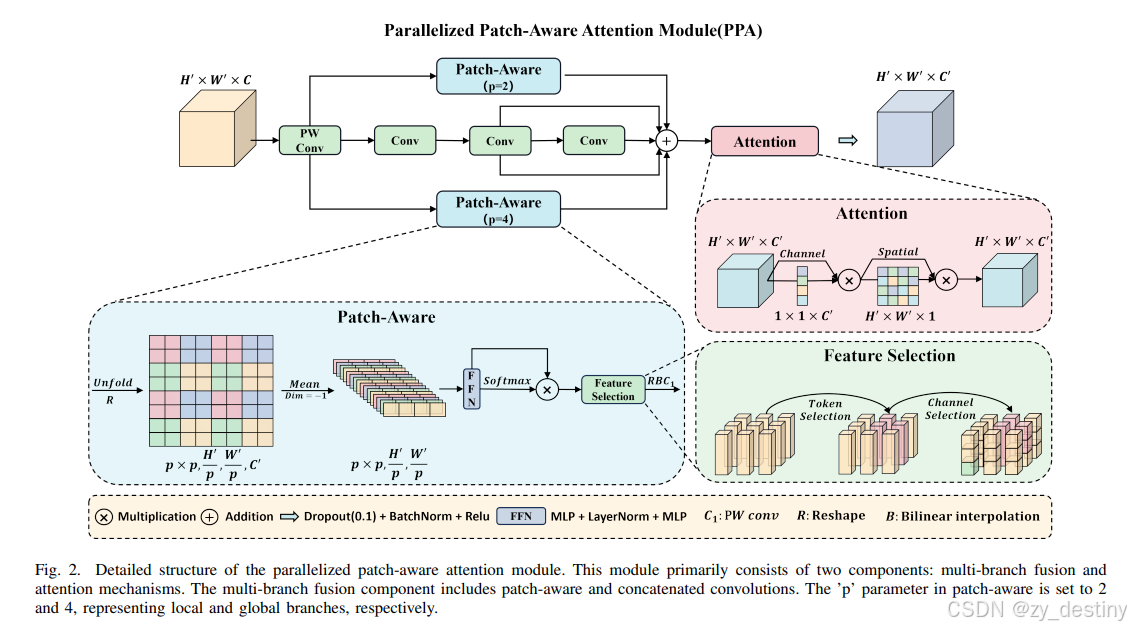
PPA模块的核心在于多分支特征提取和特征融合与注意力机制,具体工作流程如下:
-
多分支特征提取:
-
输入特征张量 F∈RH′×W′×C 首先通过逐点卷积调整通道数,得到 F′∈RH′×W′×C′。
-
然后通过三个并行分支分别计算局部特征 Flocal、全局特征 Fglobal 和串行卷积特征 Fconv。
-
局部和全局分支:通过控制块大小参数 p(例如 p=2 表示局部分支,p=4 表示全局分支),将 F′ 分割成非重叠的块,并计算块之间的注意力矩阵,实现局部和全局特征的提取与交互。具体步骤包括:
-
使用
Unfold和reshape操作将 F′ 分割成一组空间上连续的块 (p×p,pH′,pW′,C)。 -
对块进行通道平均,得到 (p×p,pH′,pW′)。
-
通过线性计算(如前馈神经网络 FFN)和激活函数,得到块在空间维度上的概率分布,并根据任务相关性调整块的权重。
-
使用特征选择操作,基于任务嵌入 ξ 和余弦相似度函数 sim(⋅,⋅),对每个块的特征进行加权,选择与任务相关的特征。
-
-
串行卷积分支:用三个 3×3 卷积层替换传统的 7×7、5×5 和 3×3 卷积层,分别得到 Fconv1、Fconv2 和 Fconv3,并将它们相加得到 Fconv。
-
-
最后,将三个分支的输出 Flocal、Fglobal 和 Fconv 相加,得到融合后的特征 F~。
-
-
特征融合与注意力:
-
将融合后的特征 F~ 依次通过一维通道注意力图 Mc∈R1×1×C′ 和二维空间注意力图 Ms∈RH′×W′×1 进行特征增强。
-
具体计算公式为:
Fc=Mc(F~)⊗F~,Fs=Ms(Fc)⊗Fc,其中 ⊗ 表示逐元素相乘,Fc 和 Fs 分别表示经过通道和空间选择后的特征。
-
最后,通过 ReLU 激活函数和批量归一化(Batch Normalization, BN)处理,得到 PPA 模块的最终输出 F′′。
-
👍3.2.维度感知选择性集成(DASI)模块

DASI模块的主要作用是在跳跃连接中自适应地选择和融合高维和低维特征,具体工作流程如下:
-
输入高维特征 Fh∈RHh×Wh×Ch、低维特征 Fl∈RHl×Wl×Cl 和当前层特征 Fu∈RH×W×C。
-
首先通过卷积和插值操作将高维和低维特征与当前层特征对齐,得到对齐后的特征 Fh′ 和 Fl′。
-
然后将对齐后的特征在通道维度上划分为四个等分,分别得到高维、低维和当前层的四个通道段 (hi)i=14、(li)i=14 和 (ui)i=14。
-
对于每个通道段,计算自适应融合权重 α=sigmoid(ui),并根据权重进行特征融合:
ui′=αli+(1−α)hi,其中 ui′ 表示融合后的特征段。
-
将融合后的四个特征段在通道维度上合并,得到 Fu′,然后通过卷积、批量归一化和 ReLU 激活函数处理,得到 DASI 模块的最终输出 F^u。
-
如果 α>0.5,模型优先选择细粒度特征;如果 α<0.5,则更注重上下文特征。
👍3.3 多扩张通道细化(MDCR)模块
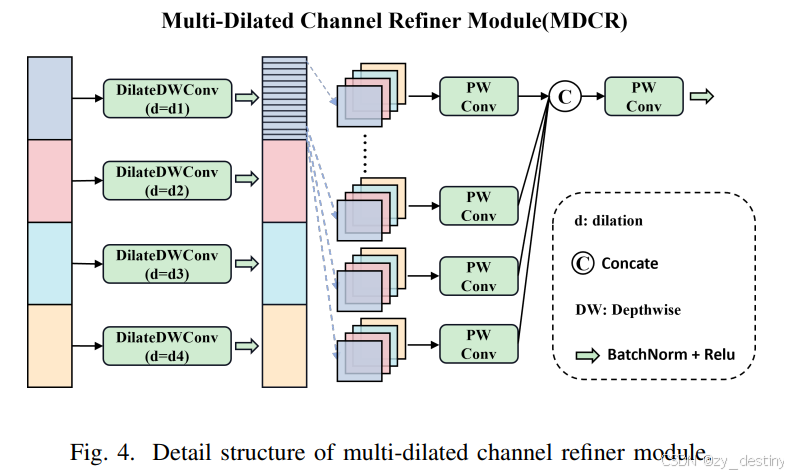
MDCR模块通过多个扩张率不同的深度可分离卷积层捕捉不同感受野范围的空间特征,具体工作流程如下:
-
输入特征 Fa∈RH×W×C。
-
将输入特征在通道维度上划分为四个头 (ai)i=14∈RH×W×4C。
-
每个头分别进行扩张率不同的深度可分离卷积操作,得到 (ai′)i=14∈RH×W×4C,扩张率分别为 d1,d2,d3,d4。
-
将每个头的特征进一步划分为单通道特征 (aj,i)j=14C∈RH×W×1,然后将不同头的相同通道特征交错组合,形成 (hj)j=14C∈RH×W×4。
-
通过逐点卷积对交错组合后的特征进行组内和组间信息融合,得到最终输出 Fo∈RH×W×C。
-
具体计算公式为:
hj=Winner([aj,1,aj,2,aj,3,aj,4]),Fo=δ(B(Wouter([h1,h2,…,hj]))),其中 Winner 和 Wouter 是逐点卷积中的权重矩阵,δ 和 B 分别表示 ReLU 激活函数和批量归一化。
通过以上三个模块的协同工作,HCFNet能够有效地解决红外小目标检测中目标信息丢失和背景复杂性的问题,显著提高了检测性能。
🍌🍌4.为小目标识别的设计
- PPA模块旨在通过多尺度特征提取和注意力机制,增强小目标的特征表示,防止小目标在多次下采样过程中丢失重要信息。
- DASI模块旨在通过自适应选择和融合高维和低维特征,增强小目标的显著性,解决高维特征可能丢失小目标信息、低维特征可能缺乏足够上下文的问题。
- MDCR模块旨在通过多尺度特征提取和通道信息细化,增强小目标与背景之间的区分能力,提高小目标的定位精度。
🍉🍉5.python代码训练
🍇5.1数据准备
我在复现HCFNet网络使用了2个数据集(SIRST和NCHU),都是公开数据集,如何你要训练自己的数据,可以按照以下数据组织格式来准备数据:
|-SIRST
|-trainval
|-images
|-xxx.png
|-masks
|-xxx.png
|-test
|-images
|-xxx.png
|-masks
|-xxx.png🍇5.2训练yaml配置
训练参数配置在./opention/train.yaml文件中,具体内容如下:
exp:
name: HCF_demo_NCHU
save_exp: True
bs: 16
total_epochs: 300
log_interval: 1
save_interval: 150
test_interval: 1
device: 1
model:
net:
type: HCFnet
gt_ds: True
optim:
type: AdamW
# init_lr: !!float 1e-3
init_lr: !!float 5e-4
weight_decay: !!float 1e-4
betas: [0.9, 0.999]
# Iou_loss, Bce_loss, Dice_loss ..
loss:
loss_1:
type: Bce_loss
weight: 1
loss_2:
type: Iou_loss
weight: 1
# resume_train: ~
lr:
warmup_iter: -1 # warmup to init_lr
# type: CosineAnnealingLR /
scheduler:
# type: ~
type: CosineAnnealingLR
step_interval: iter # iter or epoch (every iter or every epoch to update once)
eta_min: !!float 1e-5
dataset:
name:
train:
type: Dataset_aug_bac
data_root: /home/2025/红外小目标分割/NCHU-Seg/trainval
img_sz: 512
test:
type: Dataset_test
data_root: /home/2025/红外小目标分割/NCHU-seg/test
img_sz: 512
resume:
net_path:
state_path:
主要要修改的参数包括:
- name:训练的名字,跟后续保存出来的文件夹名称有关,也可以默认,就是不方便换了数据集之后查找哪个模型是那个数据集,所以建议在name里做好区分
- bs:batchsize,没啥说的,按照自己的显存调就行了
- total_epochs:也没啥说的,epoch总数
- save_intreval:每多少轮保存一次模型,这个可以自己设定
- data_root:数据集的根目录,要根据自己的数据集地址修改
🍇5.3开始训练
train.py内容如下:
import time
import torch
import torch.nn as nn
import torch.distributed as dist
import torch.utils.data as Data
import os
import time
import logging
import random
import copy
import numpy as np
from basicseg.seg_model import Seg_model
from basicseg.utils.yaml_options import parse_options, dict2str
from basicseg.utils.path_utils import *
from basicseg.utils.logger import get_root_logger, init_tb_logger, get_env_info, MessageLogger
from basicseg.data import build_dataset
def set_seed(seed, cuda_deterministic=False):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
if cuda_deterministic:
# slower, more reproducible
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
else:
# faster
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = True
def init_exp(opt, args):
exp_name = opt['exp'].get('name')
if not exp_name:
exp_name = os.path.basename(args.opt[:-4])
opt['exp']['name'] = exp_name
exp_root = make_exp_root(os.path.join('experiment', exp_name))
opt['exp']['exp_root'] = exp_root
log_file = os.path.join(exp_root, f'train_{exp_name}_{get_time_str()}.log')
logger = get_root_logger(logger_name='basicseg', log_level=logging.INFO, log_file=log_file)
logger.info(get_env_info())
logger.info(dict2str(opt))
tb_logger = init_tb_logger(log_dir = os.path.join(exp_root, 'tb_log'))
return logger, tb_logger
def init_model(opt):
model = Seg_model(opt)
return model
def init_dataset(opt):
# trainset
train_opt = opt['dataset']['train']
trainset = build_dataset(train_opt)
test_opt = opt['dataset']['test']
testset = build_dataset(test_opt)
return trainset, testset
def init_dataloader(opt, trainset, testset):
if opt['exp']['dist']:
sampler = Data.DistributedSampler(trainset)
else:
sampler = None
train_loader = Data.DataLoader(dataset=trainset, batch_size=opt['exp']['bs'],\
sampler=sampler, num_workers=opt['exp'].get('nw', 16))
test_loader = Data.DataLoader(dataset=testset, batch_size=opt['exp']['bs'],\
sampler=None, num_workers=opt['exp'].get('nw', 16))
return train_loader, test_loader
def main():
opt, args = parse_options()
os.environ['CUDA_VISIBLE_DEVICES'] = str(opt['exp']['device']) # not safe there
if isinstance(opt['exp']['device'], int):
opt['exp']['dist'] = False
cur_rank = 0
total_device = 1
opt['exp']['num_devices'] = total_device
elif isinstance(opt['exp']['device'], str):
opt['exp']['dist'] = True
dist.init_process_group(backend='nccl')
total_device = len(opt['exp']['device']) // 2 + 1
opt['exp']['num_devices'] = total_device
cur_rank = dist.get_rank()
# init dataset
trainset, testset = init_dataset(opt)
train_loader, test_loader = init_dataloader(opt, trainset, testset)
# init exp_root, logger, tb_logger
total_epochs = opt['exp']['total_epochs']
total_iters = total_epochs * (len(trainset) // opt['exp']['bs'] // total_device +1)
opt['exp']['total_iters'] = total_iters
save_interval = opt['exp']['save_interval']
test_interval = opt['exp']['test_interval']
logger, tb_logger = init_exp(opt, args)
set_seed(cur_rank + 0)
# initialize parameters including network, optimizer, loss function, learning rate scheduler
model = init_model(opt)
cur_iter = 0
cur_epoch = 1
# train from checkpoint
if opt.get('resume'):
if opt['resume'].get('net_path'):
model.load_network(model.net, opt['resume']['net_path'])
logger.info(f'load pretrained network from: {opt["resume"]["net_path"]}')
else:
logger.info(f'load from random initialized network')
if opt['resume'].get('state_path'):
cur_epoch = model.resume_training(opt['resume']['state_path'])
cur_iter = cur_epoch * (len(trainset) // opt['exp']['bs'] // total_device + 1)
logger.info(f'resume training from epoch: {cur_epoch}')
else:
logger.info(f'training from epoch: 1')
msg_logger = MessageLogger(opt, start_epoch=cur_epoch, tb_logger=tb_logger)
for epoch in range(cur_epoch, total_epochs+1):
if opt['exp']['dist']:
train_loader.sampler.set_epoch(epoch)
epoch_st_time = time.time()
########## training ##########
for idx, data in enumerate(train_loader):
cur_iter += 1
model.update_learning_rate(cur_iter, idx)
model.optimize_one_iter(data)
epoch_time = time.time() - epoch_st_time
log_vars = {'epoch': epoch}
log_vars.update({'lrs': model.get_current_learning_rate()})
log_vars.update({'time': epoch_time})
log_vars.update({'train_loss': model.get_epoch_loss(opt['exp']['dist'], 'sum')})
log_vars.update({'train_mean_metric': model.get_mean_metric(opt['exp']['dist'], 'mean')})
log_vars.update({'train_norm_metric': model.get_norm_metric(opt['exp']['dist'], 'mean')})
########## tesing ##########
if cur_rank == 0 and epoch % test_interval == 0:
# model.net.eval()
model.model_to_eval()
for idx, data in enumerate(test_loader):
model.test_one_iter(data)
log_vars.update({'test_loss': model.get_epoch_loss()})
test_mean_metric = model.get_mean_metric()
test_norm_metric = model.get_norm_metric()
log_vars.update({'test_mean_metric': test_mean_metric})
log_vars.update({'test_norm_metric': test_norm_metric})
if test_mean_metric['iou'] > model.best_mean_metric['iou']:
model.best_mean_metric['iou'] = test_mean_metric['iou']
model.best_mean_metric['net'] = copy.deepcopy(model.net.state_dict())
model.best_mean_metric['epoch'] = epoch
if test_norm_metric['iou'] > model.best_norm_metric['iou']:
model.best_norm_metric['iou'] = test_norm_metric['iou']
model.best_norm_metric['net'] = copy.deepcopy(model.net.state_dict())
model.best_norm_metric['epoch'] = epoch
# model.net.train()
model.model_to_train()
########## saving_model ##########
if cur_rank == 0 and epoch % save_interval == 0 :
model.save_network(opt, model.net, epoch)
model.save_training_state(opt, epoch)
msg_logger(log_vars)
########## trainging done ##########
if cur_rank == 0:
model.save_network(opt, model.net, current_epoch='latest')
model.save_network(opt, model.best_mean_metric['net'], current_epoch='best_mean', net_dict=True)
model.save_network(opt, model.best_norm_metric['net'], current_epoch='best_norm', net_dict=True)
logger.info(f"best_mean_metric: [epoch: {model.best_mean_metric['epoch']}] [iou: {model.best_mean_metric['iou']:.4f}]")
logger.info(f"best_norm_metric: [epoch: {model.best_norm_metric['epoch']}] [iou: {model.best_norm_metric['iou']:.4f}]")
if __name__ == '__main__':
main()
开始训练命令:
python train.py --opt ./options/train.yaml开始训练之后输出:
nohup: ignoring input
INFO:albumentations.check_version:A new version of Albumentations is available: 2.0.5 (you have 1.4.11). Upgrade using: pip install --upgrade albumentations
INFO:basicseg:
Version Information:
PyTorch: 1.12.1+cu116
TorchVision: 0.13.1+cu116
INFO:basicseg:
exp:[
name: HCF_demo_sirst
save_exp: True
bs: 16
total_epochs: 300
log_interval: 1
save_interval: 150
test_interval: 1
device: 0
dist: False
num_devices: 1
total_iters: 8100
exp_root: experiment/HCF_demo_sirst/20250415_110123
]
model:[
net:[
type: HCFnet
gt_ds: True
]
optim:[
type: AdamW
init_lr: 0.0005
weight_decay: 0.0001
betas: [0.9, 0.999]
]
loss:[
loss_1:[
type: Bce_loss
weight: 1
]
loss_2:[
type: Iou_loss
weight: 1
]
]
lr:[
warmup_iter: -1
scheduler:[
type: CosineAnnealingLR
step_interval: iter
eta_min: 1e-05
]
]
]
dataset:[
name: None
train:[
type: Dataset_aug_bac
data_root: /home/2025/红外小目标分割/sirst/trainval
img_sz: 512
]
test:[
type: Dataset_test
data_root: /home/2025/红外小目标分割/sirst/test
img_sz: 512
]
]
resume:[
net_path: None
state_path: None
]
2025-04-15 11:01:23.587776: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2025-04-15 11:01:23.656910: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-04-15 11:01:24.497913: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
INFO:basicseg:load from random initialized network
INFO:basicseg:training from epoch: 1
libpng warning: iCCP: known incorrect sRGB profile
libpng warning: iCCP: known incorrect sRGB profile
INFO:basicseg:[HCF_demo_sirst][epoch: 1, lr:(5.000e-04,)] [eta: 6:35:16, time (epoch): 62.499 ]
TrainSet
Bce_loss_0:2.1497e+01 Iou_loss_0:5.2275e+01
m_fscore:0.0063 m_iou:0.0031 n_fscore:0.0453 n_iou:0.0154
TestSet
Bce_loss_0:1.3040e+01 Iou_loss_0:2.6983e+01
m_fscore:0.0000 m_iou:0.0000 n_fscore:0.0000 n_iou:0.0000
libpng warning: iCCP: known incorrect sRGB profile
libpng warning: iCCP: known incorrect sRGB profile
INFO:basicseg:[HCF_demo_sirst][epoch: 2, lr:(4.999e-04,)] [eta: 6:01:02, time (epoch): 49.180 ]
TrainSet
Bce_loss_0:1.4009e+01 Iou_loss_0:5.2275e+01
m_fscore:0.0053 m_iou:0.0027 n_fscore:0.0143 n_iou:0.0051
TestSet
Bce_loss_0:9.0274e+00 Iou_loss_0:2.6982e+01
m_fscore:0.0000 m_iou:0.0000 n_fscore:0.0000 n_iou:0.0000
libpng warning: iCCP: known incorrect sRGB profile
libpng warning: iCCP: known incorrect sRGB profile
INFO:basicseg:[HCF_demo_sirst][epoch: 3, lr:(4.999e-04,)] [eta: 5:48:37, time (epoch): 48.982 ]
TrainSet
Bce_loss_0:1.1098e+01 Iou_loss_0:5.2274e+01
m_fscore:0.0021 m_iou:0.0011 n_fscore:0.0024 n_iou:0.0013
TestSet
Bce_loss_0:7.7452e+00 Iou_loss_0:2.6981e+01
m_fscore:0.0000 m_iou:0.0000 n_fscore:0.0000 n_iou:0.0000
libpng warning: iCCP: known incorrect sRGB profile
libpng warning: iCCP: known incorrect sRGB profile
INFO:basicseg:[HCF_demo_sirst][epoch: 4, lr:(4.998e-04,)] [eta: 5:41:48, time (epoch): 48.853 ]
TrainSet
Bce_loss_0:9.0992e+00 Iou_loss_0:5.2266e+01
m_fscore:0.0044 m_iou:0.0022 n_fscore:0.0040 n_iou:0.0017
TestSet
Bce_loss_0:6.6226e+00 Iou_loss_0:2.6981e+01
m_fscore:0.0007 m_iou:0.0004 n_fscore:0.0004 n_iou:0.0002
libpng warning: iCCP: known incorrect sRGB profile
libpng warning: iCCP: known incorrect sRGB profile
INFO:basicseg:[HCF_demo_sirst][epoch: 5, lr:(4.997e-04,)] [eta: 5:37:23, time (epoch): 49.074 ]
TrainSet
Bce_loss_0:7.6279e+00 Iou_loss_0:5.2175e+01
m_fscore:0.0060 m_iou:0.0030 n_fscore:0.0043 n_iou:0.0022
TestSet
Bce_loss_0:5.4171e+00 Iou_loss_0:2.6981e+01
m_fscore:0.0000 m_iou:0.0000 n_fscore:0.0000 n_iou:0.0000
🍇5.4测试
与训练一样,测试的时候也有个./option/test.yaml文件,内容如下:
exp:
# save_dir:
bs: 4
device: 0
save_dir: /data/HCFNet-main/output/sirst
model:
net:
type: HCFnet
gt_ds: False
dataset:
test:
type: Dataset_test
data_root: /home/2025/红外小目标分割/sirst
img_sz: 512
get_name: True
resume:
net_path: /data/HCFNet-main/experiment/HCF_demo_sirst/20250415_110123/models/net_best_mean.pth
主要参数有:
- device:显卡号
- save_dir:保存结果的地址
- data_root:数据集输入根目录
- net_path:网络模型地址
准备好test.yaml就可以进行测试了,具体的测试命令:
python test.py --opt ./options/test.yaml
输出结果:
(openmmlab) [n@354426 HCFNet-main]$ python test.py --opt ./options/test.yaml
INFO:albumentations.check_version:A new version of Albumentations is available: 2.0.5 (you have 1.4.11). Upgrade using: pip install --upgrade albumentations
INFO:basicseg:Loading HCFnet model from /data/n/HCFNet-main/experiment/HCF_demo_sirst/20250415_110123/models/net_best_mean.pth.
load pretrained network from: /data/n/HCFNet-main/experiment/HCF_demo_sirst/20250415_110123/models/net_best_mean.pth
100%|?????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????| 22/22 [00:07<00:00, 3.02it/s]
best_mean_metric: [miou: 0.8527] [mfscore: 0.9205]
best_norm_metric: [niou: 0.8554] [nfscore: 0.9223]🍇5.5精度展示
sirst数据集和NCHU数据集的精度展示如下:
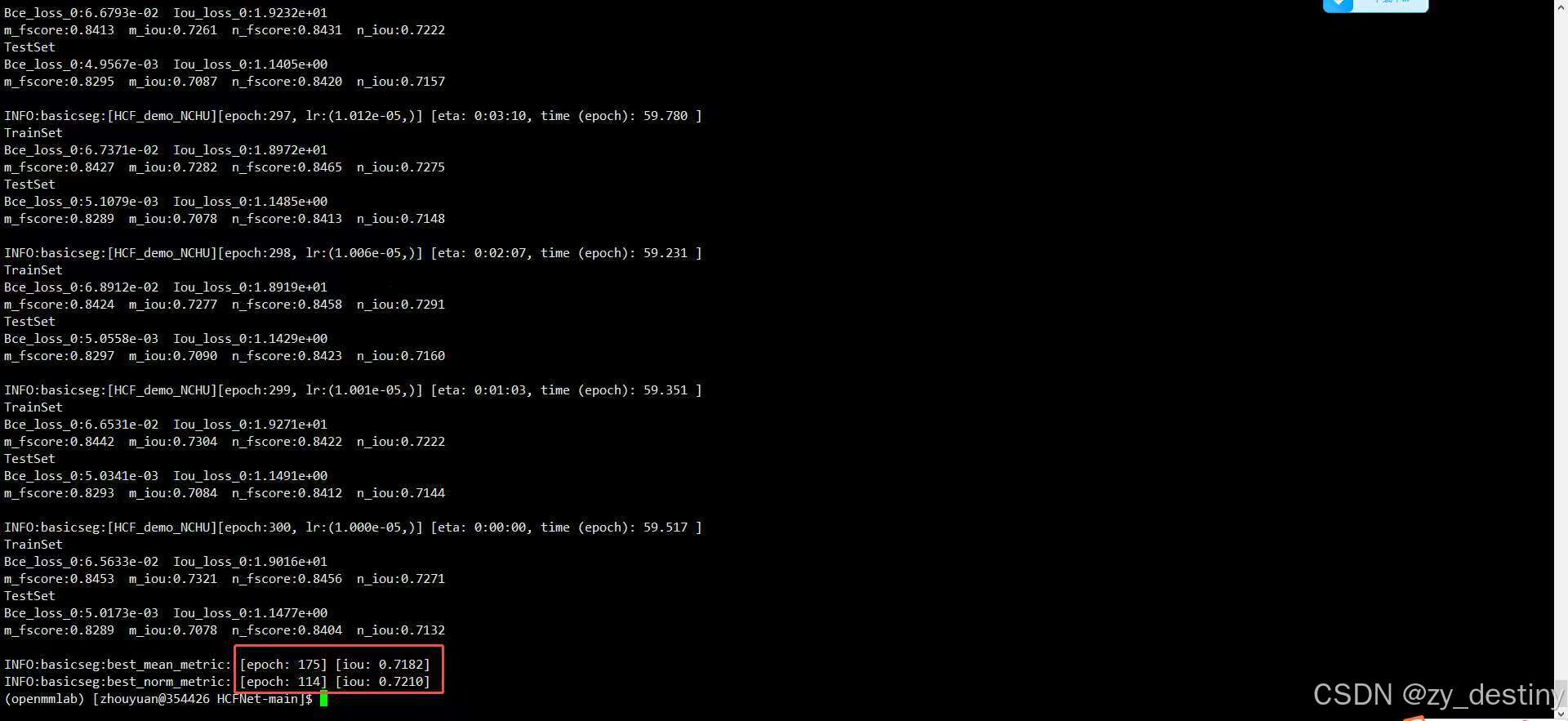
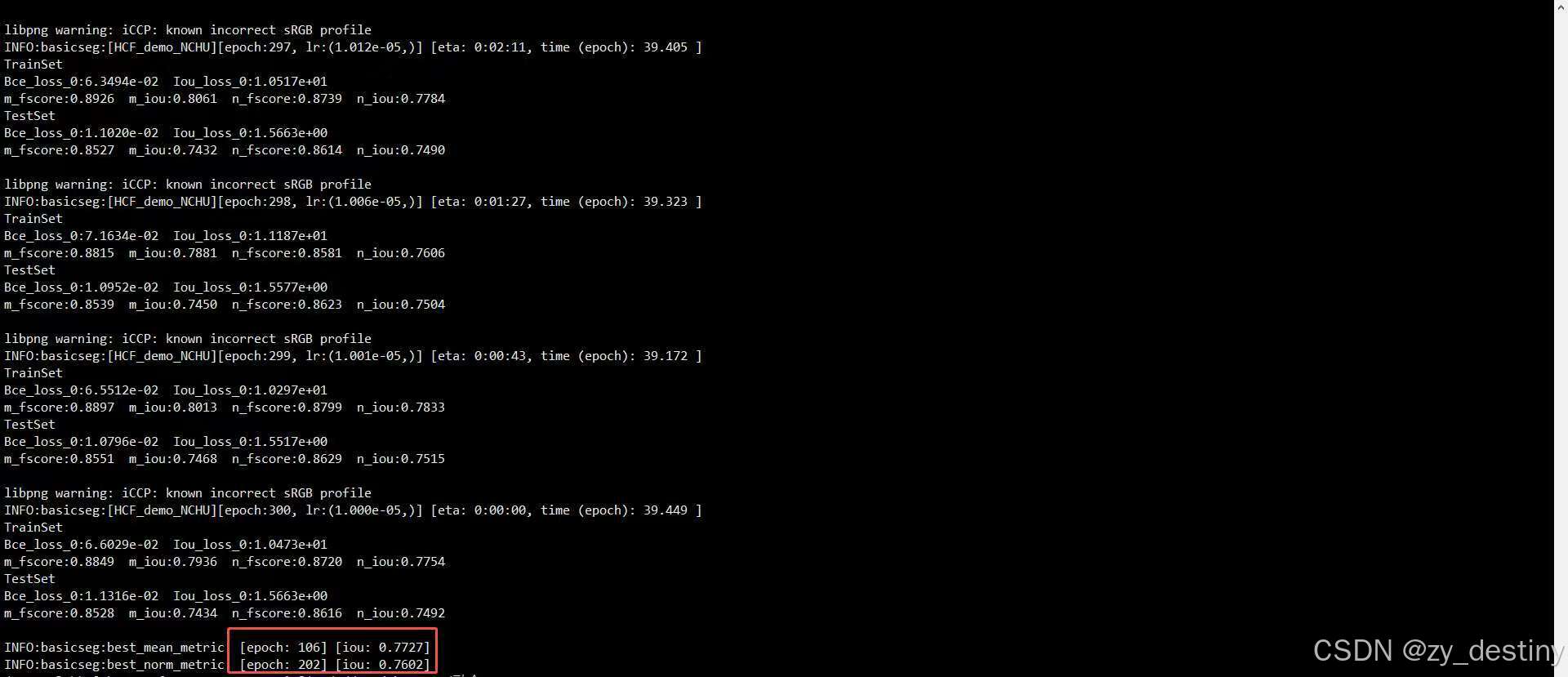
sirst: miou = 0.7182 niou = 0.7210
NCHU: miou = 0.7727 niou = 0.7602
至此,HCFNet在红外图像上的小目标检测任务就完成了,撒花。有问题的童鞋可在下方留言。
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











