










NCLL github:https://github.com/NVIDIA/nccl
NCCL是Nvidia Collective multi-GPU Communication Library的简称,它是一个实现多GPU的collective communication通信(all-gather, reduce, broadcast)库,Nvidia做了很多优化,以在PCIe、Nvlink、InfiniBand上实现较高的通信速度。
1 通信原语(communication primitive)
并行任务的通信一般可以分为Point-to-point communication和Collective communication。
P2P通信这种模式只有一个 sender 和一个 receiver,实现起来比较简单。第二种 Collective communication 包含多个 sender 多个 receiver,一般的通信原语包括 broadcast,gather,all-gather,scatter,reduce,all-reduce,reduce-scatter,all-to-all 等。几个常用的操作:
- Reduce:从多个sender那里接收数据,最终combine到一个节点上。
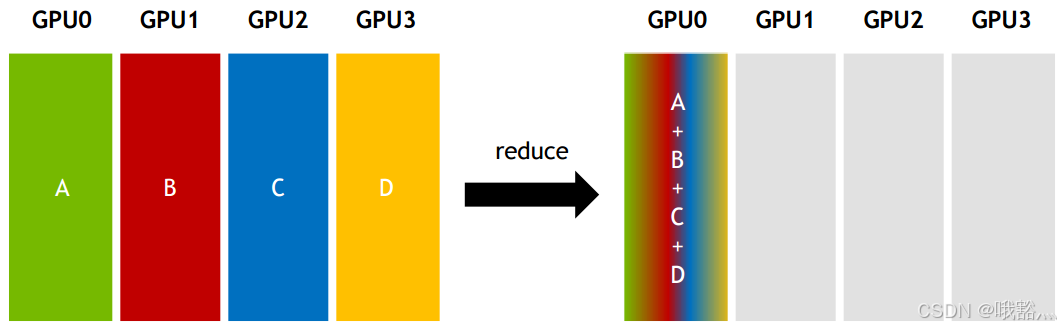
- All-reduce:从多个sender那里接收数据,最终combine到每一个节点上。
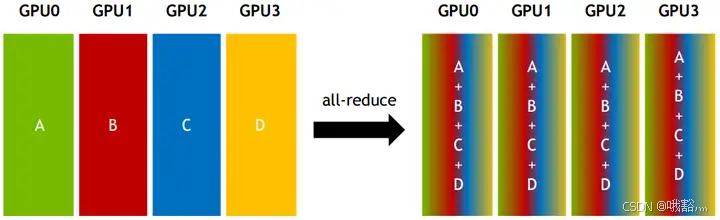
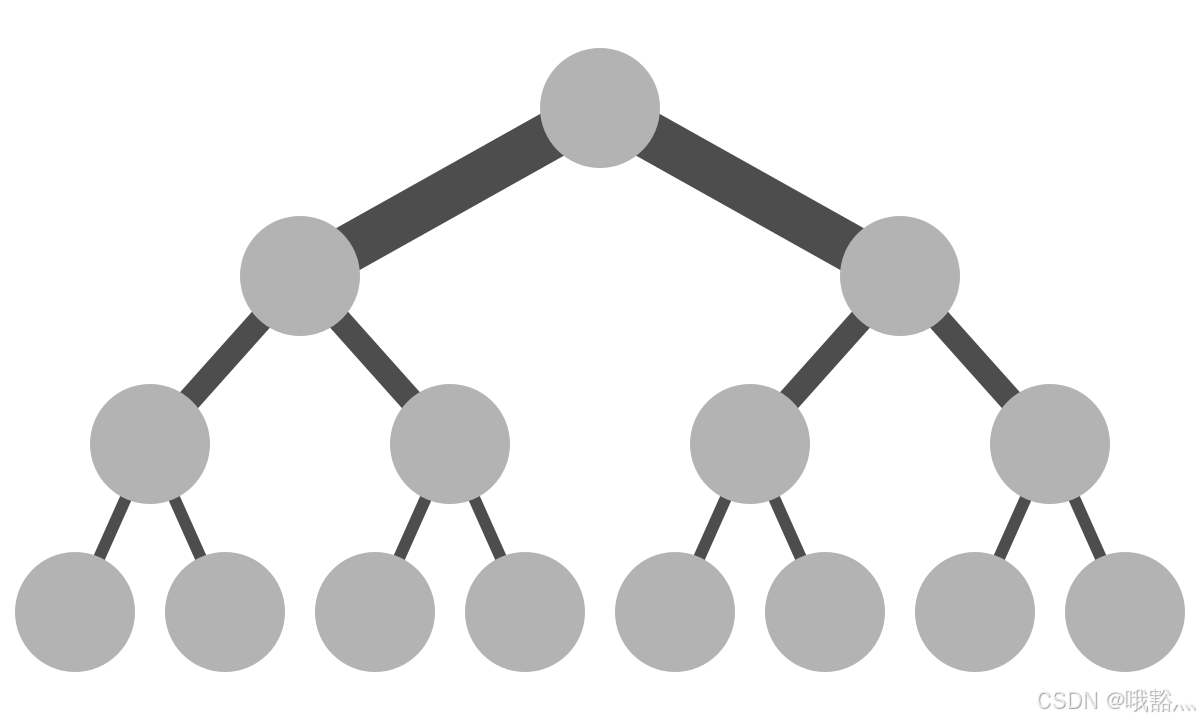
传统Collective communication假设通信节点组成的拓扑节后是一颗fat tree,如下图所示,这样通信效率最高。但实际的通信拓扑节后可能比较复杂,并不是一个fat tree。因此一般用ring-based Collective communication。
2 ring-base collectives
ring-base collectives 将所有的通信节点通过首尾连接形成一个单向环,数据在环上依次传输。以broadcast为例, 假设有4个GPU,GPU0为sender将信息发送给剩下的GPU,按照环的方式依次传输,GPU0-->GPU1-->GPU2-->GPU3,若数据量为 N,带宽为 B,整个传输时间为
(
K
−
1
)
N
/
B
(K-1)N/B
(K−1)N/B。时间随着节点数线性增长,不是很高效。
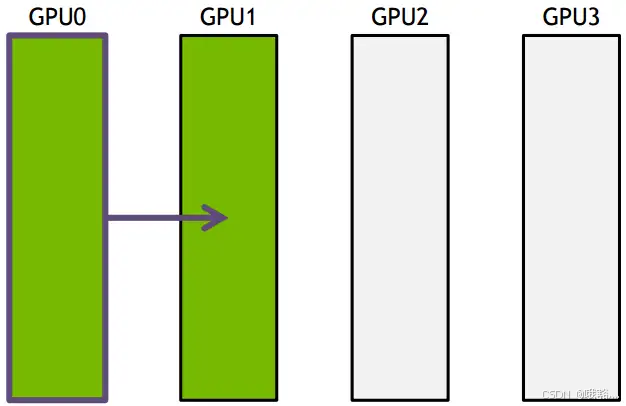
把要传输的数据分成 S 份,每次只传 N/S 的数据量,传输过程如下所示:
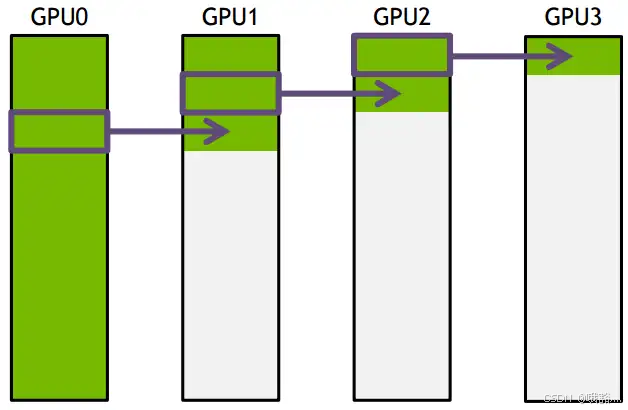
GPU1接收到GPU0的一份数据后,也接着传到环的下个节点,这样以此类推,最后花的时间为 s ∗ ( N / S / S ) + ( K − 2 ) ∗ ( N / S / B ) = N ( S + K − 2 ) / ( S B ) − − > ( N / B ) s*(N/S/S) + (K-2)*(N/S/B) = N(S+K-2)/(SB) --> (N/B) s∗(N/S/S)+(K−2)∗(N/S/B)=N(S+K−2)/(SB)−−>(N/B),在 S 远大于 K 的时候成立,即数据的份数远大于节点的数量。此时通信时间不随节点数增加而增加,只与数据总量和带宽有关。其它通信操作比如 reduce、gather 类似。
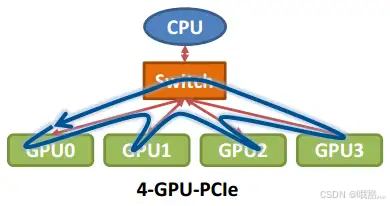
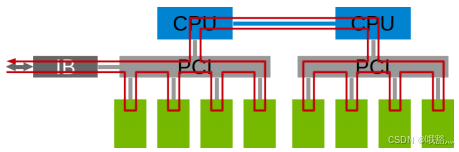
在以GPU为通信节点的场景下,单机4卡通过同一个PCIe switch挂载在一棵CPU的场景:
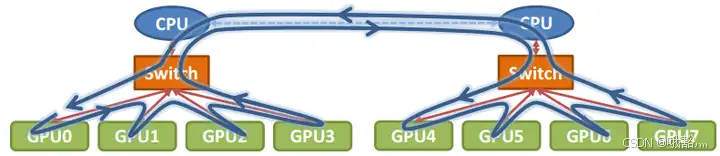
单机8卡通过两个CPU下不同的PCIe switch挂载的场景:
3 NCCL 实现
NCCL实现成 CUDA C++ kernels,包含 3 种 primitive operations: Copy,Reduce,ReduceAndCopy。
NCCL 1.0 版本只支持单机多卡,卡之间通过PCIe、NVlink、GPU Direct P2P来通信。NCCL 2.0支持多机多卡,多机间通过Sockets (Ethernet)或者InfiniBand with GPU Direct RDMA通信。
单机内多卡通过PCIe以及CPU socket通信,多机通过InfiniBand通信。
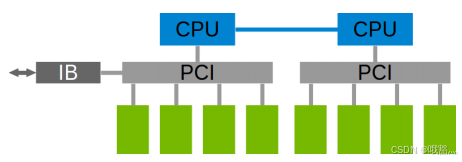
在多机多卡内部,也要构成一个通信环:
NCCL在机内通信的时候采用的是Ring-Allreduce算法,不过是若干个Ring-Allreduce。NCCL在初始化的时候,会检查系统中的链路拓扑,并创建若干个环路,以达到最优的性能。
NCCL 2.4以后,多机通信就默认采用Double Binary Tree了:
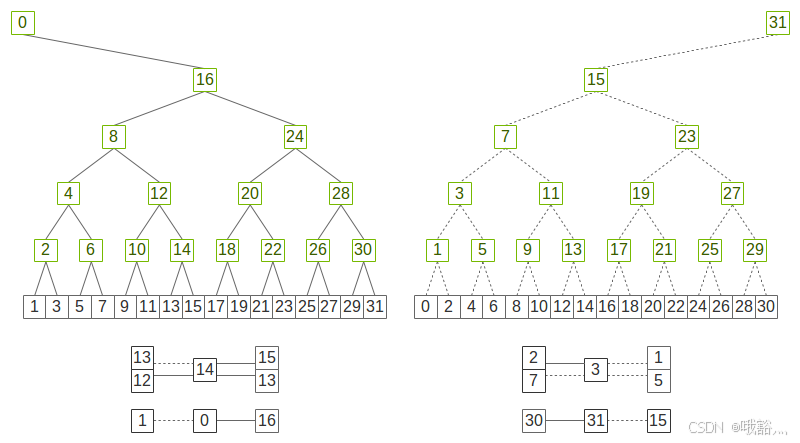
Double Binary Tree 相较于 Ring 的收益:
- 使用Double Binary Tree可以很好的将intra-node和inter-node通信给pipeline起来。实际运行过程中,NCCL每个channel会做intra-node reduce -> inter-node all-reduce -> intra-node broadcast,这三个步骤是可以流水线处理的。
- 通过构建Double Binary Tree,每个节点至多是一个叶子和一个非叶子结点。因此每个节点至多只需要收发两倍的数据量,这点跟Ring的实现也是一样的。因此Double Binary Tree也是一种带宽最优(近似)的算法。之所以说是近似,是因为根节点只需要收发一倍的数据量。
- 随着节点数量的增加,Ring算法所带来的latency是成线性增加的。而Double Binary Tree的latency是log(N)。
4 CollNet
CollNet其实不是一种算法,而是一种自定义的网络通信方式,需要加载额外的插件来使用。是基于SHArP协议的,具体加载方法这个链接里有写:https://docs.nvidia.com/networking/display/SHARPv261/Using+NVIDIA+SHARP+with+NVIDIA+NCCL
NVIDIA官方的CollNet实现应该是只有基于SHArP的这一种,需要搭配Infiniband以及Infiniband交换机一起食用。
4.1 SHArP
介绍SHArP的论文:https://ieeexplore.ieee.org/document/7830486
简单来说,SHArP是一个软硬结合的通信协议,实现在了NVIDIA Quantum HDR Switch的ASIC里。它可以把从各个node收到的数据进行 reduce,并发送回去。更通俗一些来说,通过使用SHArP,把 reduce 的操作交由交换机完成了。这种做法,业界叫做In-network Computing(在网计算)。用术语展开来讲,就是将计算卸载到网络中进行。
NVIDIA 关于 SHArP 的介绍:https://www.nvidia.com/en-us/on-demand/session/gtcspring21-s32067/
通过把计算卸载到网络里,每个node只需要收发一倍的数据量就可以完成AllReduce了。相比Tree和Ring算法,收发的数据量直接就减半了。而且SHArP因为把计算卸载给交换机去做了,因此小数据的latency也会减少很多。
SHArP nccl-tests里有一个nccl-test的例子,应该是用128个DGX A100服务器测的。测出来的算法带宽有95GB/s。机间达到了95GB/s。这个值已经很接近 A100 卡间的通信带宽 120GB/s。
5 NCCL关键参数
5.1 NCCL_P2P_DISABLE
用于控制 NCCL是否启用GPU间的点对点(Peer-to-Peer, P2P)直接通信功能的环境变量。点对点P2P通信允许GPU直接交换数据,而无需经过CPU或系统内存,这样可以减少数据传输的延迟并提高吞吐量。
在多GPU系统中,点对点通信指的是两个GPU之间直接的数据交换能力。这通常依赖于硬件级别的直接内存访问(DMA)技术,比如NVLink、PCI Express (PCIe) 或其他高速互连技术,使得GPU能够绕过CPU直接读写另一个GPU的内存。
在P2P被禁用的情况下,NCCL会回退到其他通信机制,比如通过共享内存(SHM)进行数据交换。这通常涉及到数据先从一个GPU复制到CPU内存,然后再从CPU内存复制到另一个GPU,增加了额外的步骤和潜在的性能损失。
5.2 NCCL_P2P_LEVEL
自NCCL 2.3.4版本起,NCCL_P2P_LEVEL 环境变量允许用户精细化控制GPU间何时使用点对点(P2P)传输。这一变量定义了GPU间最大距离阈值,在此阈值内NCCL将采用P2P传输方式。用户需指定一个简短的字符串来表示路径类型,以此来设定启用P2P传输的拓扑界限。如果不特别指定,NCCL将尝试根据运行的架构和环境自动选择最优的P2P使用策略。
如果不特别指定,NCCL将尝试根据运行的架构和环境自动选择最优的P2P使用策略:
- LOC:指示NCCL完全不考虑P2P通信,即便GPU间存在直接连接也不会启用。
- NVL:仅在GPU间有NVLink直接连接时启用P2P通信。
- PIX:当GPU位于同一个PCI交换机上时,允许使用P2P传输。
- PXB:即便需要跨多个PCI交换机跳转,只要GPU间可通过PCIe链路相连,即启用P2P。
- PHB:在相同NUMA节点上的GPU间使用P2P 。此时P2P通信虽允许,但数据流经CPU,可能不如直接P2P高效。
- SYS:跨NUMA节点使用P2P,可能涉及SMP互连(如QPI/UPI)。在不同NUMA节点的GPU间启用P2P,可能包含跨越系统间高速互联的情况。
此外,用户还可以使用整数值来设定NCCL_P2P_LEVEL,这些数值对应于上述路径类型:
- LOC:0
- PIX:1
- PXB:2
- PHB:3
- SYS:4
5.3 NCCL_P2P_DIRECT_DISABLE
NCCL_P2P_DIRECT_DISABLE 环境变量用于禁止NCCL直接通过点对点(P2P)在同一个进程管理下的不同GPU间访问用户缓冲区。这项设置在用户缓冲区通过不自动使它们对同一进程中其他GPU可访问(特别是缺乏P2P访问权限)的API分配时非常有用。
当设置 NCCL_P2P_DIRECT_DISABLE=1 时,NCCL在进行通信操作时,即使源和目标GPU属于同一个进程中,也会避免直接通过P2P方式访问和传输用户分配的内存缓冲区。这一设置主要是为了解决一些特定的内存分配和访问权限问题,确保程序的兼容性和稳定性。
通过启用 NCCL_P2P_DIRECT_DISABLE,NCCL会采取替代路径来完成数据传输,这可能意味着数据会先从一个GPU复制到CPU内存(或通过其他中介存储),然后再从CPU内存复制到目标GPU。这样的路径显然不如直接P2P高效,但在某些特定配置下是必要的,以确保数据的正确传输和程序的正常执行。
5.4 NCCL_SHM_DISABLE
NCCL_SHM_DISABLE 环境变量用于禁用NCCL中的共享内存(SHM)传输方式。共享内存通常在GPU间无法直接进行点对点(P2P)通信时使用,作为替代路径,通过主机内存来传输数据。当设置 NCCL_SHM_DISABLE=1 后,NCCL在那些原本会使用共享内存的场景下,将转而使用网络(例如,InfiniBand或IP套接字)在CPU插槽间进行通信。
在某些系统配置中,GPU可能由于硬件或驱动限制,无法有效地利用P2P通信。此时,NCCL通常会退回到使用共享内存作为数据传输的中间站。然而,如果共享内存本身也存在问题或效率低下(例如,内存带宽限制),禁用SHM并改用网络通信可能是更优选择。在拥有高性能网络环境(如InfiniBand)的多节点系统中,直接通过网络而非共享内存进行GPU间的数据交换,有时可以提供更低的延迟和更高的吞吐量,尤其是在跨节点通信时。同时,在资源紧张的环境中,禁用共享内存可以减轻系统内存的压力。
6 测试
- 查看网卡设备:
lspci | grep Ethernet
- 查看机器上的 NVIDIA 显卡:
lspci | grep NVIDIA
- 查看RDMA设备
ibv_devices
# 我这里没有 RDMA 设备,因此显示如下:
device node GUID
------ ----------------
- 测试GPU的连接拓扑:
nvidia-smi topo -m
# 我这里只有两张卡,并且是使用 PCIE 连接,因此GPU拓扑如下:
GPU0 GPU1 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X SYS 0-27 0 N/A
GPU1 SYS X 0-27 0 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks

















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









