







我们的目标是使用一个对抗损失函数,学习映射G:X → Y (A2B),使得判别器难以区分图片 G(X) 与 图片Y。因为这样子的映射受到巨大的限制,所以我们为映射G 添加了一个相反的映射F:Y → X(B2A),使他们成对,同时加入一个循环一致性损失函数 (cycle consistency loss),以确保 F(G(X)) ≈ X(反之亦然)。
在这篇文章中,我们提出了一个方法:在没有成对图像的情况下,刻画一个图像数据集的特征,并弄清楚如何将这些特征转化为另外一个图像数据集的特征。这个问题可以被描述成概念更加广泛的图像到图像的翻译 (Image-to-Image translation),从给定的场景x 完成一张图像到另一个场景 y 的转换。举例:从灰度图片到彩色图片、从图像到语义标签(semantic labels) 、从轮廓到图片。但它需要成对的数据 。
但是获取成对的图像较为困难,所以我们寻找一种算法可以学习如何在没有成对数据的情况下,在两个场景之间进行转换。我们假设在两个数据域直接存在某种联系——例如:每中场景中的每幅图片在另一个场景中都有它对应的图像,(我们让机器)去学习这个转换关系。尽管缺乏成对的监督学习样本,我们仍然可以在集合层面使用监督学习:我们在数据域X中给出一组图像,在数据域Y 中给出另外一组图像。我们可以训练一种映射G : X → Y 使得 输出![]() 同时又有一个判别器将生成的样本
同时又有一个判别器将生成的样本![]() 从真实样y本中辨认出来。
从真实样y本中辨认出来。
从而存在一个最佳的映射G,将数据域X翻译为![]() (在程序中表示为fake_Y),使得数据域
(在程序中表示为fake_Y),使得数据域![]() 具有相同的分布,然而,这样的翻译不能保证独立分布的输入x和y是有意义的一对一,因为有无限多种映射G可以有输入的x导出相同的y。此外,在实际中我们发现很难单独地优化判别器:当输出图图片从输入映射到输出的时候,标准的程序经常因为一些众所周知的问题而导致奔溃,使得优化无法继续。
具有相同的分布,然而,这样的翻译不能保证独立分布的输入x和y是有意义的一对一,因为有无限多种映射G可以有输入的x导出相同的y。此外,在实际中我们发现很难单独地优化判别器:当输出图图片从输入映射到输出的时候,标准的程序经常因为一些众所周知的问题而导致奔溃,使得优化无法继续。
为了解决这些问题,我们需要往我们的模型中添加其他结构。因此我们利用 翻译应该具有“循环稳定性”(translation should be "cycle consistent") 的这个性质,某种意义上,我们将一个句子从英语翻译到法语,再从法语翻译回英语,那么我们将会得到一相同的句子。从数学上讲,如果我们有一个生成器 G : X → Y 与另一个生成器 F : Y → X ,那么 G 与 F 彼此是相反的,这一对映射是双射(bijections) 。
于是我们将这个结构应用到 映射 G 和 F 的同步训练中,并且加入一个 循环稳定损失函数(cycle consistency loss) 以确保到达![]() 将这个损失函数与判别器在数据域X 与数据域Y 的对抗损失函数结合起来,就可以得到非成对图像到图像的目标转换。
将这个损失函数与判别器在数据域X 与数据域Y 的对抗损失函数结合起来,就可以得到非成对图像到图像的目标转换。
公式推导
CycleGAN其实就是一个X→Y单向GAN加上一个Y→X单向GAN。两个GAN共享两个生成器,然后各自带一个判别器,所以加起来总共有两个判别器和两个生成器。一个单向GAN有两个loss,而CycleGAN加起来总共有四个loss。

- G实现X到Y迁移(生成fake_Y)
- F实现Y到X迁移(生成fake_X)
- DX实现判别F生成的数据和真实的X数据
- DY实现判别G生成的数据or真实的Y数据
训练过程如下:
- G尽可能生成更真的图像欺骗DY
- F尽可能生成更真的图像欺骗DX
- DX尽可能判别出真实的X或者F生成的X
- DY尽可能判别出真实的Y或者G生成的Y
cycleGAN描述
- 分布X,分布Y,分别来自不同的domain
- G: X->Y ,生成器G来实现从X到Y的迁移
- F: Y->X ,生成器F来实现从Y到X的迁移
- Dx判别X与 F(y) ,判别器Dx判别到底是真X还是F根据Y生成的与X同分布的数据
- Dy判别Y与 G(x),判别器Dy判别到底是真Y还是G根据X生成的与Y同分布的数据
其过程包含了两种loss:
- adversarial losses:尽可能让生成器生成的数据分布接近于真实的数据分布
- cycle consistency losses: 防止生成器G与F相互矛盾,即两个生成器生成数据之后还能变换回来近似看成X->Y->X
adversarial loss
尽可能让生成器生成的数据接近于真实的数据分布,与GAN一样,G用于实现X->Y, 训练应当尽可能让此G(X)接近于Y,判别器Dy用于判别样本的真假。与GAN的公式一样:
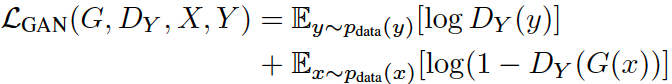
- 其中y表示域Y内的样本,x表示域X内的样本
- DY(y)表示真实的Y中的样本在判别器DY之中的评分,越接近1则判别器认为此样本越真。
- G(x)为生成器根据x生成的与Y同分布的样本。
- DY( G(x))为判别器根据生成的样本得到的评分,如果DY认为生成的样本越假,则DY的评分DY( G(x) )越接近于0,则 1-DY( G(x) ) 越接近于1
- 如果判别器越强,则更能区分真实的y与生成器根据x生成的G(x),此loss值会越大
- 同时,生成器希望尽可能的生成以假乱真的样本,欺骗判别器,所以生成器希望GAN loss越小。生成器与判别器在对抗的过程中,越来越强,最终生成器生成的样本以假乱真,达到判别器判别不出来的程度。
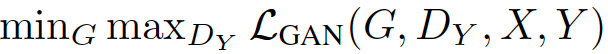
- 整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
- D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
- G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
- D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)
当映射G 试图生成与数据域Y相似的图片 G(x) 的时候,判别器也在试着将生成的图片从原图中区分出来。映射G 希望通过优化减小的项目与 映射F 希望优化增大的项目 相对抗,另一个映射F 也是如此.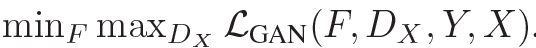
cycle consistency loss
用于让两个生成器生成的样本之间不要相互矛盾。
上一个adversarial loss只可以保证生成器生成的样本与真实样本同分布,但是我们希望对应的域之间的图像是一一对应的。即A-B-A还可以再迁移回来。
如上图(b) 所示,数据域X 中的每一张图片x 在循环翻译中,应该可以让x 回到翻译的原点,反之亦然,即 前向、后向循环一致,换言之:(Consistency loss 源域X中的图像x,经过其中一个生成器生成图像 G(x),作为另一个生成器的输入生成回来 F(G(x)),尽可能与原来图像接近)
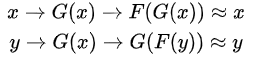
为了尽可能保证consistency,我们设定相应的loss:
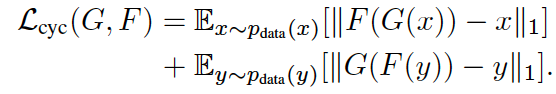
总体loss
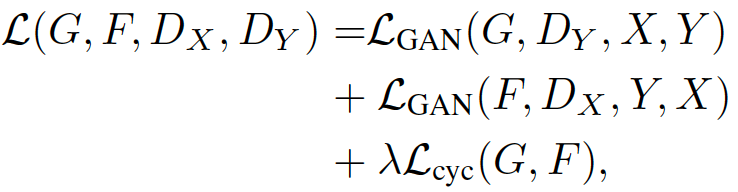
即生成器G尽可能实现X到Y的迁移,生成器F尽可能实现Y到X的迁移,同时,两生成器是可以实现互逆,即相互迭代回到自身。(作者后面细节之中,λ 取10 )
idt loss
Identity loss 用于保证生成图像的连续性,一个图像x,经过其中一个生成器生成图像 G(x),尽可能与原来图像接近。如果不使用这个损失,则生成器G与F 可以自由地改变输入图像的色调,而这是不必要的。idt loss的定义在论文的application之中,防止input 与out put之间的color compostion过多。网络所有的loss的定义就是,reconstruction loss就是GAN loss和cycle consistency loss两个加在一起,GAN loss用于迁移类,cycle consistency loss用于尽量保留原图可以循环迁移。














 2258
2258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









