







CycleGAN:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Abstract
图像到图像的翻译是一类视觉和图形问题,其目标是使用成对的图像训练集来学习输入图像和输出图像之间的映射。但是,对于许多任务,不存在配对的训练集据。本文提出了一种在没有配对训练集的情况下学习将图像从源域X转换为目标域Y的方法。
Introduction
CycleGAN是发表于ICCV17的一篇GAN工作,可以让两个domain的图片互相转化。传统的GAN是单向生成,而CycleGAN是互相生成,网络是个环形,所以命名为Cycle。并且CycleGAN一个非常实用的地方就是输入的两张图片可以是任意的两张图片,也就是unpaired。
Pix2Pix训练数据集的一个非常重要的要求就是你的图像必须是成对的,这一点其实是非常苛刻的,现实中很难找到,就好比同一个场景下的白天和黑夜的两幅图,很难找到这样一个大的数据集里面包含完全相同的同一个场景下的白天与黑夜图。CycleGAN训练集不在需要同一组完全配对的图,只需要两个模式不同的图即可,如下:

Formulation

本文的目标包含两种类型的术语:对抗损失,用于将生成的图像的分布与目标域中的数据分布进行匹配; 以及循环一致性损失,以防止学习到的映射G和F相互矛盾。
单向GAN
CycleGAN本质上是两个镜像对称的GAN,构成了一个环形网络。其实只要理解了一半的单向GAN就等于理解了整个CycleGAN。

上图是一个单向GAN的示意图。我们希望能够把domain A的图片(命名为a)转化为domain B的图片(命名为图片b)。为了实现这个过程,我们需要两个生成器GAB 和GBA ,分别把domain A和domain B的图片进行互相转换。图片A经过生成器GAB表示为Fake Image in domain B,用GAB (a)表示。而GAB (a)经过生成器GBA表示为图片
A
A
A的重建图片,用GBA(GAB(a))表示。最后为了训练这个单向GAN需要两个loss,分别是生成器的重建loss和判别器的判别loss。
单向GAN的损失函数
训练这个单向GAN需要两个loss:生成器的重建Loss和判别器的判别Loss:
判别器DB是用来判断输入的图片是否是真实的domain B图片,于是生成的假图片GAB(A)和原始的真图片B都会输入到判别器里面,公示挺好理解的,就是一个0,1二分类的损失。最后的loss表示为:
- 判别器的损失
判别器DB是用来判断输入的图片是否是真实的domain B图片,于是生成的假图片GAB(A)和原始的真图片B都会输入到判别器里面,公示挺好理解的,就是一个0,1二分类的损失。最后的loss表示为:
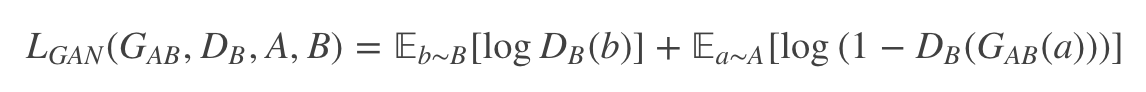
- 生成器的损失
生成器用来重建图片a,目的是希望生成的图片GBA(GAB(a))和原图a尽可能的相似,那么可以很简单的采取L1 loss或者L2 loss。最后生成loss就表示为:

CycleGAN
CycleGAN其实就是一个A→B单向GAN加上一个B→A单向GAN。两个GAN共享两个生成器,然后各自带一个判别器,所以加起来总共有两个判别器和两个生成器。一个单向GAN有两个loss,而CycleGAN加起来总共有四个loss。CycleGAN论文的原版原理图和公式如下,其实理解了单向GAN那么CycleGAN已经很好理解。

对抗损失
For the mapping function G : X → Y and its discriminator DY , we express the objective as:

整个式子由两项构成。
y
y
y表示真实图片,
x
x
x表示输入G网络的图片,而
G
(
x
)
G(x)
G(x)表示G网络生成的图片。
DY(y)表示D网络判断真实图片是否真实的概率(因为
y
y
y就是真实的,所以对于D来说,这个值越接近1越好)。而DY(G(x))是D网络判断G生成的图片的是否真实的概率。
G的目的:上面提到过,DY(G(x))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望DY(G(x))尽可能得大,这时LGAN(G,DY,X,Y)会变小。因此式子对于G来说是求最小化min。
D的目的:D的能力越强,DY(y)应该越大,DY(G(x))应该越小。这时LGAN(G,DY,X,Y)会变大。因此式子对于D来说是求最大化max。

Y → X的过程类似:

循环一致性损失


总的损失函数:


论文里面提到判别器如果是对数损失训练不是很稳定,所以改成的均方误差损失,如下:

实验结果


本文结果的图像质量接近于完全监督的pix2pix产生的图像质量,而且本文的方法无需配对监督就可以学习映射。意思就是不需要严格的图与图之间的配对。

训练细节
- Generator采用的是Perceptual losses for real-time style transfer and super-resolution 一文中的网络结构;一个resblock组成的网络,降采样部分采用stride 卷积,增采样部分采用反卷积;Discriminator采用的仍是pix2pix中的PatchGANs结构,大小为70x70;
- 定义四个xx器的损失函数,分别优化训练G和D,两个生成器共享权重,两个鉴别器也共享权重训练;
- 计算每个生成图像的损失是不可能的,因为会耗费大量的计算资源。建立一个图像库,存储之前生成的50张图,而不只是最新的生成器生成的图;
- Lr=0.0002。对于前100个周期,保持相同的学习速率0.0002,然后在接下来的100个周期内线性衰减到0。
代码实现
论文地址
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks















 2668
2668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









