






Deep Knowledge Tracing 论文阅读笔记
参考文献: Piech C , Spencer J , Huang J , et al. Deep Knowledge
Tracing[J]. Computer Science, 2015, 3(3):págs. 19-23
.
1 Introduction
Knowledge Tracing(知识追寻)的任务是**学生的知识在随着时间的推移的变化,通过生成模型去精确预测学生将来的表现。**根据预测表现,基于每位学生的需求,去提供个性化的学习方案推荐。提高学习效率和减少学习开销。
作者后面又用一种公式化的方式讲述了Knowledge Tracing的任务:根据所给的学生特定学习任务中的可观测交互数据: x 0 , x 1 … … x t x_0, x_1 ……x_t x0,x1……xt,去预测接下来的交互数据 x t + 1 x_{t+1} xt+1的表现
之前的教育相关工作大都依赖于:马尔科夫模型
这篇文章中提出的DKT模型:将深度神经网络引入教育相关工作,通过大量的人工神经元向量去表示潜在的知识状态,通过RNN来体现时间的动态性。学生掌握知识点的潜在变量是从数据中挖掘学习出来,而不是硬编码。
这篇论文的几个重要贡献
- 以一种新的方式去编码学生的交互信息,作为RNN的输入
- 与之前的成果相比较,该方法提升了25%的AUC
- DKT不需要专家标注
- 挖掘习题的影响并生成改进后的习题课程体系(不太明白)
接下来解释一下论文的图

(该图片我看了好久才看懂。。。。。。)
讲述的是一个学生在学习8年级数学时的一些情况。
- y轴代表的是知识点
- x轴代表题目的索引
- 一定要注意x和y轴的小圆圈颜色,x轴上方的小圆圈代表做题情况
首先该学生做对两道Square roots相关习题,做错一道x轴截距题目。后续该同学又做了47道题目,我们可以发现,在做其他题目时候,是可能会影响其他知识点的掌握程度的。这说明DKT会在学生每次回答完习题后,根据答题情况,去预测下次习题中是否能够正确回答其他每种类型的练习题。
2 Related Work
2.1 BKT(Bayesian Knowledge Tracing)
BKT生成每位学习者的知识状态作为一个二分类变量集合,代表了每一个单一知识点掌握还是未掌握。使用HMM(Hidden Markov Model )去更新二分类变量之间的概率。
原有的模型认为,学得知识,永远不会被遗忘。近期对改模型的改进中,考虑了结合之前和将来的表现,估测猜测与失误,估测每位同学的先验知识以及估测习题难度
BKT的缺陷
1、二分类表示学生每个知识点的认知水平是不现实的
2、习题相对应的隐含变量模棱两可,很难满足模型对每个练习题对应的单一概念的期望。
3 Deep Knowledge Tracing
3.1 Model

x
i
x_i
xi表示每一个输入的向量,这一个动态的网络而不是one-hot编码或者被压缩的学生行为表现
y
i
y_i
yi表示对应的输出向量,含义为每一个习题集的正确率
h
i
h_i
hi$表示隐含状态,可以视为过去观测的相关信息的连续编码。隐含状态对于后面的预测时有用的
对应的模型公式为:
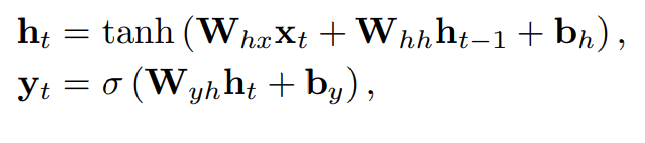
3.2 Input and Output Time Series
为了将学生的习题记录放入RNN或者LSTM中训练,需要将学生答题记录转换成固定长度的 x t x_t xt。
假设有一个长度为
M
M
M的习题集,我们将
x
t
x_t
xt转换成一个one-hot编码表示的学生答题记录元组
h
t
=
(
q
t
,
a
t
)
h_t = (q_t, a_t)
ht=(qt,at) ,
q
t
q_t
qt代表习题,
a
t
a_t
at代表习题回答是否正确。因此
x
t
⊂
(
0
,
1
)
2
M
x_t \subset(0,1)^{2M}
xt⊂(0,1)2M
但是,当练习题集过大,会导致one-hot大得离谱。因此通过一种随机向量来取代one-hot表示形式。该方法可以将
d
d
d维的
k
−
k-
k−稀疏信号从
k
l
o
g
d
klogd
klogd随机线性投影。因此可以将学生交互信息透影至一个长度为
l
o
g
2
M
log2M
log2M的固定随机高斯输入向量。
输出 y t y_t yt向量的长度为题目集的长度 M M M,表示的含义是学生回答问题的正确概率。
3.3 Optimization
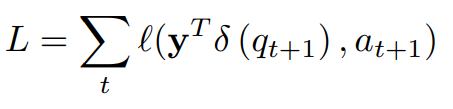
δ
(
q
t
+
1
)
\delta(q_{t+1})
δ(qt+1)表示在
t
+
1
t+1
t+1时刻习题的作答情况。
ι
\iota
ι表示二进制交叉熵
后续会尝试复现模型的代码,并跟大家分享交流。上面只是简单地笔记,可能存在错误理解。















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









