







一、数组
1. 数组的特性
Go 的数组,其实和C的数组没有什么区别,同样有着以下的特点:
- 指定长度
- 不可扩容
- 数组内所有元素都是相同类型
- 下标从 0 开始
- 访问数组指定下标元素的时间复杂度为 O(1)
- 连续空间存储
- …
2. 原理
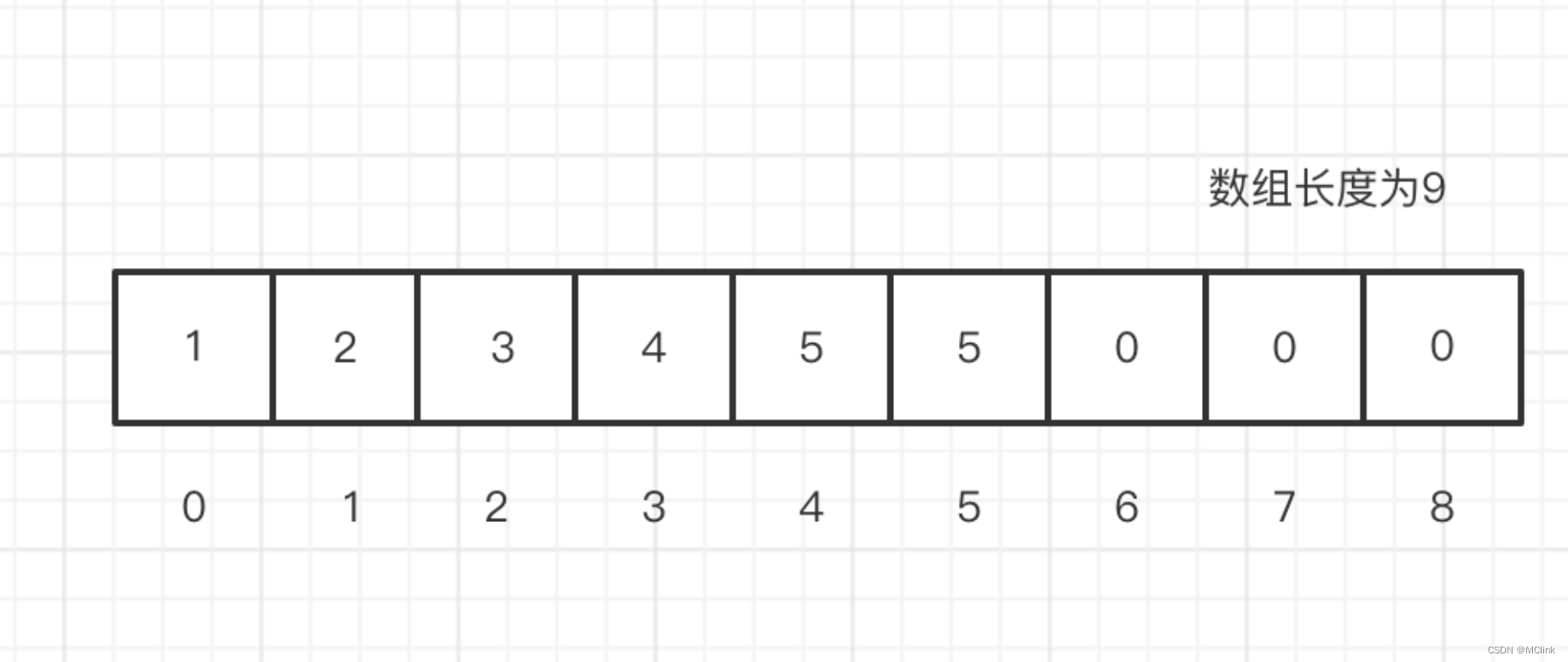
上面是一个长度为9的整形数组。在内存是连续的存储空间。
在我们定义一个数组之后,其中所有的元素值都会是该类型的零值。因此我们无法判定我们存的就是零值还是初始化给的零值,但其实这并不重要。
使用数组的好处和坏处都显而易见。
数组可以节省空间,不像链表和其他数据结构,需要额外存储其他的标识。
而且他很简单,作为基础数据结构之一,他简单而朴实无华,在一些指定的场景中,发挥着很大的作用。
指定下标 访问元素 O(1) 的时间复杂度,又让他很快。
但是人不完人,他本身并不支持扩容,因此当我们一开始定义的存储空间不够用之后,就只能新开新的数组来使用。而连续的存储空间,又很容易造成内存的浪费。就好比你订房间一样,如果个个都想要好几个连号的房间,那么就会造成很多的空房间卖不出去了。
因此数组的使用场景十分有限,因此聪明的前辈们基于数组衍生出了很多新的数据结构。
3. 如何使用
- 定义初始化
var w [3]int // 定义一个长度为3的int类型数组
a := [3]int {1,2,3} // 定义一个长度为3的int类型数组并同时进行赋值
var j = [...]int{1,2,3,4,4} //不想算长度的时候,可以用...代替长度
//[0,0,0], [1,2,3]
- 取值
b := w[0]
- 遍历
for k, v := range a {
fmt.Println(k, v)
}
for i:=0 ; i <len(a) ;i++ {
fmt.Println(a[i])
}
二、切片
为了更方便了解决扩容的问题,Go 引入了切片的概念。切片在定义时可以不指定长度,他的长度会随着元素的变多而变长,但是不会随着元素的减少而变短。实际上他就是数组的一层封装。
1. 原理
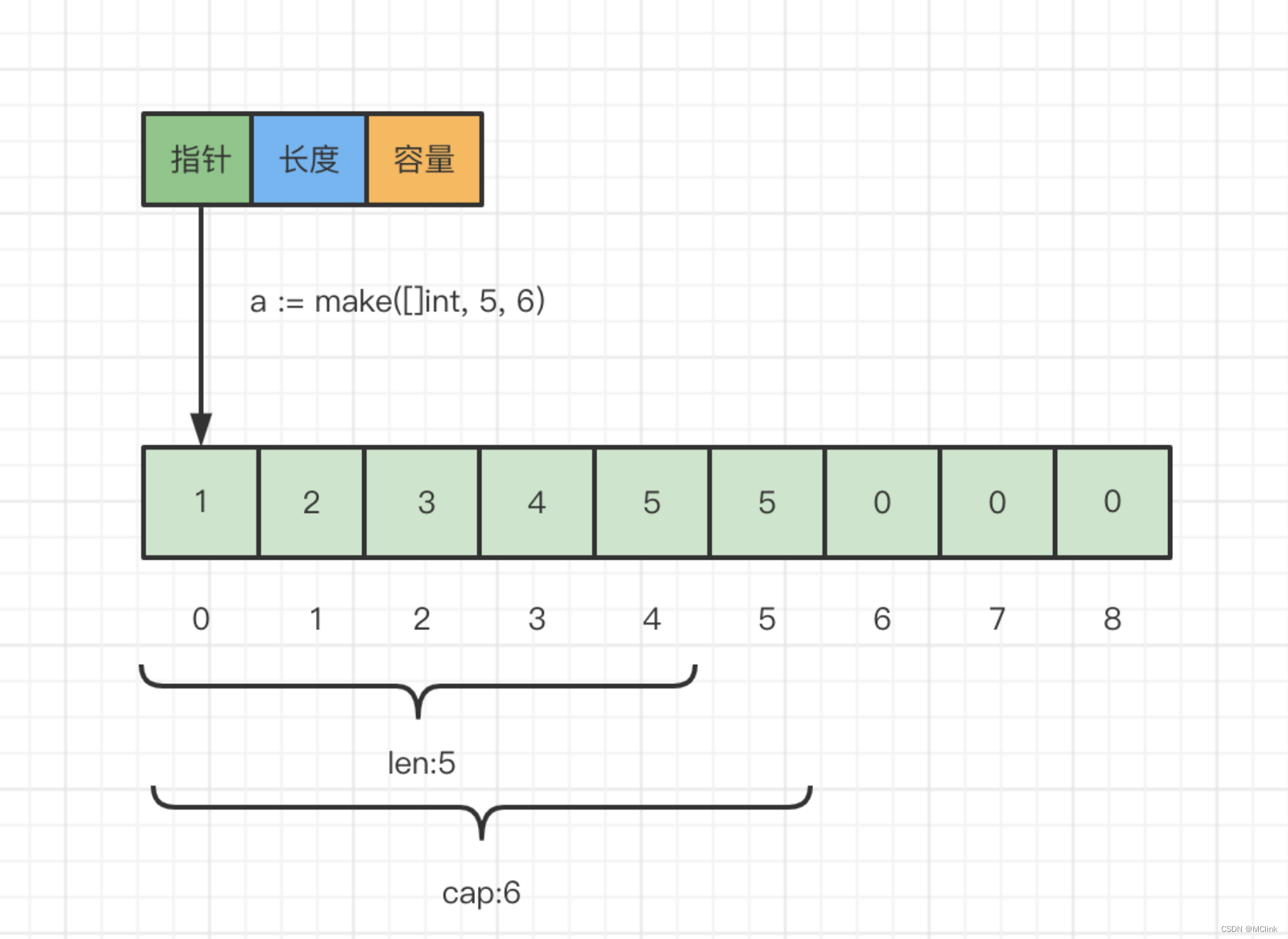
切片的底层一定是数组。所以切片可以看做是某个数组局部窗口。
切片最大的好处就是自动帮我们扩容。
传统切片有三个属性:
- 指向数组的指针
- 切片长度
- 切片容量
切片代码位于 runtime/slice.go
type slice struct {
array unsafe.Pointer
len int
cap int
}
长度是指切片真实拥有的元素个数
容量是指切片能存储的元素个数,对于数组来讲,这两个值总是相等的。
当我们定义一个切片并同时做初始化时,其长度和容量总是相等的。例如:
w := []int{1, 2, 3, 4, 7, 8, 7, 8, 8, 10}
fmt.Println(len(w), cap(w)) // 10, 10
这是因为在使用切片的时候,直接分配了一个对应长度的数组,由于我们没有添加新的元素,因此此时切片的容量和长度都等于数组的长度。
但是当我们再往里面添加元素,此时长度和容量都会变化。
w = append(w, 1, 2, 3)
fmt.Println(len(w), cap(w)) // 13,20
在slice 包中主要实现了以下的方法:
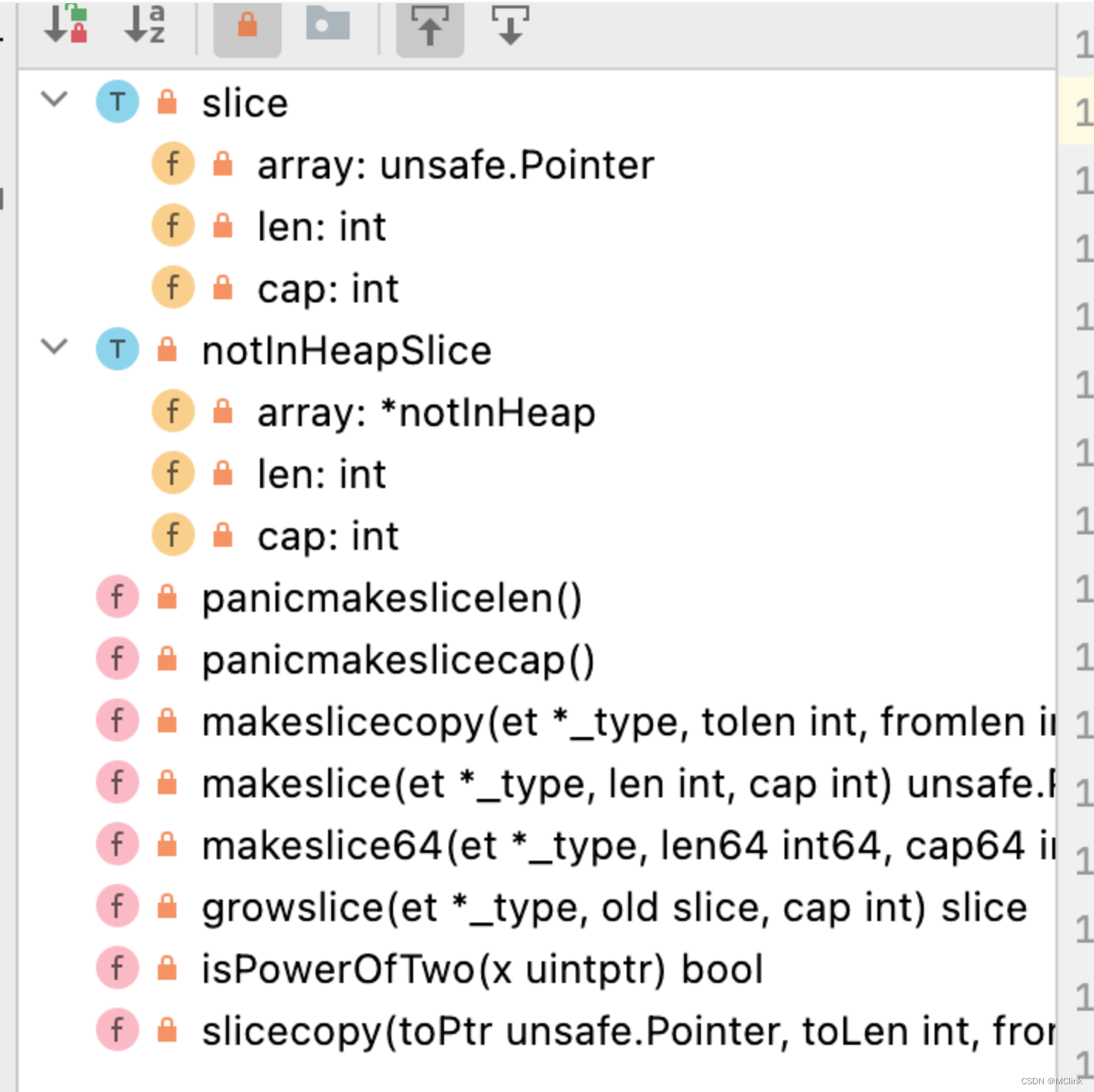
首先是两个结构体
// 普通切片
type slice struct {
array unsafe.Pointer
len int
cap int
}
// 基于 go:notinheap 内存的切片
type notInHeapSlice struct {
array *notInHeap
len int
cap int
}
go:notinheap,该指令常用于类型声明,它表示这个类型不允许从 GC 堆上进行申请内存。
在运行时中常用其来做较低层次的内部结构,避免调度器和内存分配中的写屏障,能够提高性能。
//定义了长度越界和容量越界的自定义 Panic
func panicmakeslicelen() {
panic(errorString("makeslice: len out of range"))
}
func panicmakeslicecap() {
panic(errorString("makeslice: cap out of range"))
}
// 生成切片
func makeslice(et *_type, len, cap int) unsafe.Pointer
// 也是生成切片,只是 len, cap 允许传 int64 类型,实际上也是调用makeslice的
func makeslice64(et *_type, len64, cap64 int64) unsafe.Pointer
// 切片扩容
func growslice(et *_type, old slice, cap int) slice
// 是否是2的倍数,用位运算来判断, 利用了与运算,如果是2的倍数,则返回true,
// 例如 3 的二进制是 11 , 2的2进制是10, 11&10 = 10 != 0; 1 的二进制是 01, 10 & 01 = 0
func isPowerOfTwo(x uintptr) bool {
return x&(x-1) == 0
}
// 切片的深复制, 即 copy 函数的实现
slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int
2. 如何使用
- 定义和初始化
var a []int
b := []int{1, 2, 4}
c := make([]int, 3, 8) // 长度为3,容量为8的切片
fmt.Println(a, b, c, len(b), cap(b), len(b), cap(c))
//[] [1 2 4] [0 0 0] 3 3 3 8
- 取值
w := b[0] // 和数组一样的取值方式,因为本质就是数组实现的
- 遍历
// 和数组也是一样的遍历方式
for k, v := range a {
fmt.Println(k, v)
}
for i:=0 ; i <len(a) ;i++ {
fmt.Println(a[i])
}
- 拷贝
// The copy built-in function copies elements from a source slice into a
// destination slice. (As a special case, it also will copy bytes from a
// string to a slice of bytes.) The source and destination may overlap. Copy
// returns the number of elements copied, which will be the minimum of
// len(src) and len(dst).
func copy(dst, src []Type) int // 对应 slicecopy 方法
b := []int{1, 2, 4}
c := make([]int, 3, 8)
copy(c, b) // 返回值是 min(len(c,b))
fmt.Println(b, c) //[1 2 4] [1 2 4]
- 获取长度和容量
// 获取长度
func len(v Type) int
// 获取容量
func cap(v Type) int
- 切片截取
b := []int{1, 2, 4}
fmt.Println(b[:], b[0:], b[1:2])
//[1 2 4] [1 2 4] [2]
其中 b[:] 和 b[0:] 是一样的,都是指从0到最大长度值。
b[a:b] 指获取下标为 [a,b) 区间的元素
3.切片和数组的区别
- 数组是值类型,切片是引用类型
func main() {
arr := [8]int{3, 6, 7, 5, 1, 2, 10, 14}
fmt.Println(bubblingSort(arr))
fmt.Println(insertionSort(arr))
fmt.Println(selectionSort(arr))
var tArray = func(a [3]int) {
fmt.Printf("Array in func : 0x%x , %v\n", (*uint64)(unsafe.Pointer(&a)), a) //取对应地址
}
var tSlice = func(a []int) {
fmt.Printf("Slice in func : 0x%x , %v\n", *(*uint64)(unsafe.Pointer(&a)), a) //取对应地址上的值(因为切片的指针指向的是数组的首位地址)
}
arrayA := [3]int{1, 2, 3}
sliceA := []int{1, 2}
fmt.Printf("arrayA : 0x%x , %v\n", (*uint64)(unsafe.Pointer(&arrayA)), arrayA) //取对应地址
fmt.Printf("sliceA : 0x%x , %v\n", *(*uint64)(unsafe.Pointer(&sliceA)), sliceA) //取对应地址上的值(因为切片的指针指向的是数组的首位地址)
tArray(arrayA)
tSlice(sliceA)
}
//arrayA : 0xc000016090 , [1 2 3]
//sliceA : 0xc0000180d0 , [1 2]
//Array in func : 0xc0000160c0 , [1 2 3]
//Slice in func : 0xc0000180d0 , [1 2]
我们可以看到,数组和切片作为参数传递时, 数组的地址变了,因为数组是值传递,是会复制的。而切片只是进行了浅拷贝,将指针传递了,没有复制数据,因此修改了函数内切片的值,会导致引用该底层数组的所有切片都会变化此使用切片在参数传递时可以更加节省内存空间。
- 数组从栈或者堆中申请,切片只在堆中申请
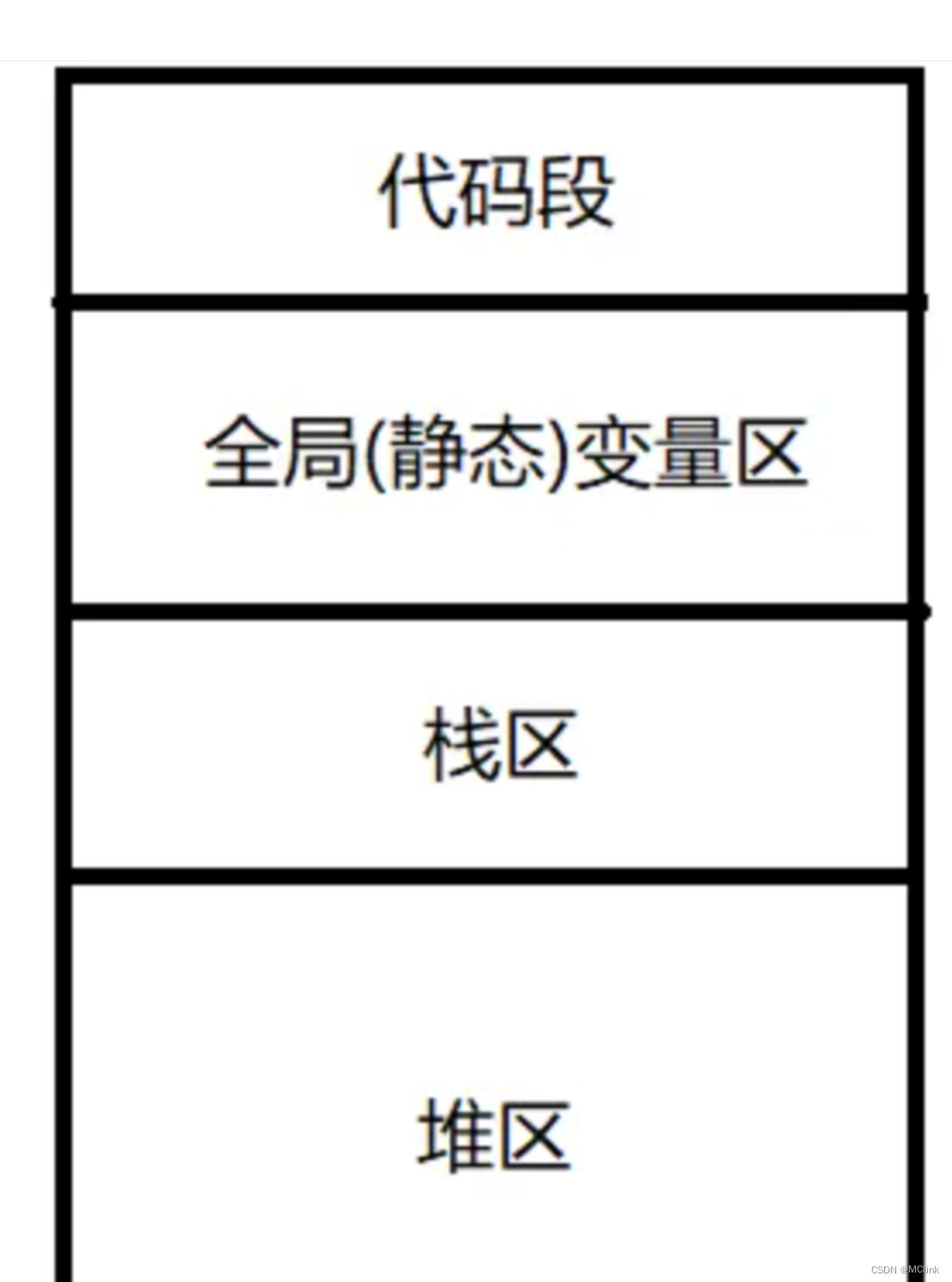
当数组元素数量小于等于4时,放置在栈区。
当数组元素数量大于4时,放置在静态区
而切片是直接从堆中申请的。
4.nil 和空切片
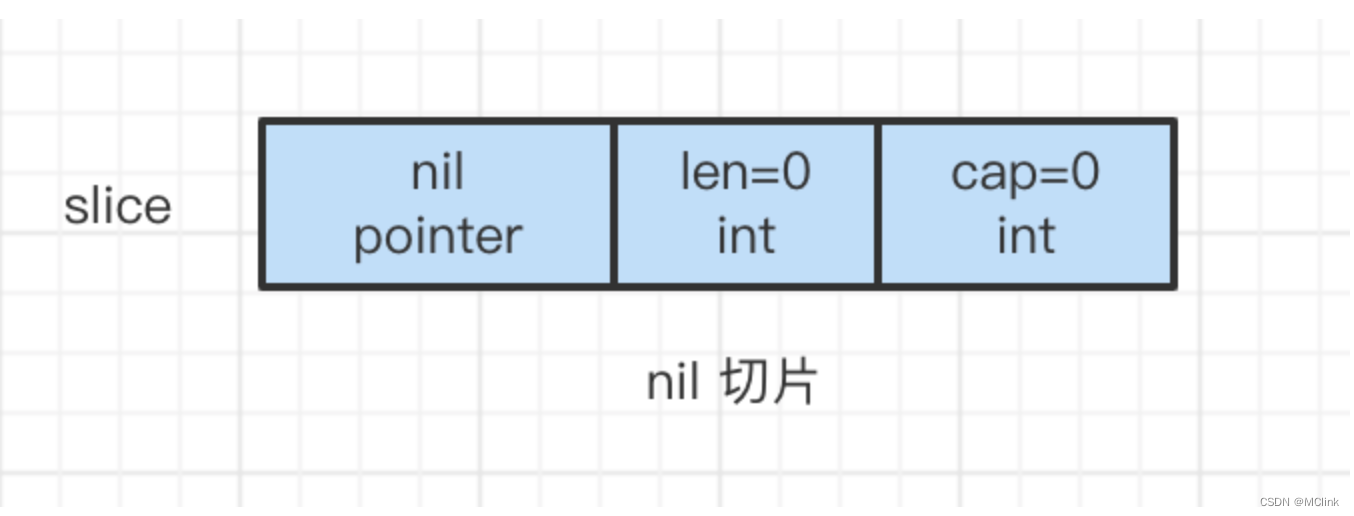
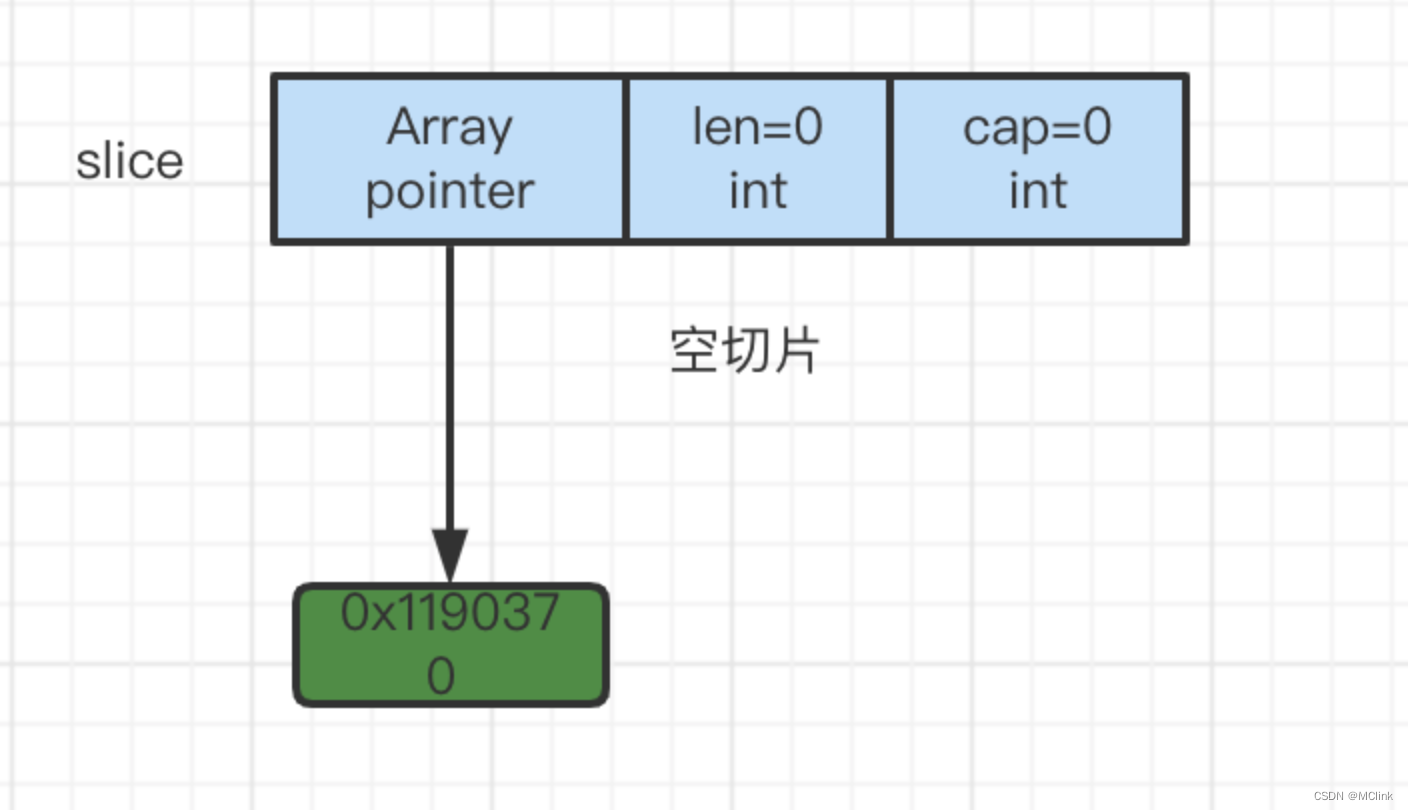
我们用代码来试试
func main() {
var slice1 []int //nil切片
silce2 := make( []int , 0 )//空切片
slice3 := []int{ } //空切片
slice4 := new([]int) //new 实际上并没有分配空间,只是创建了一个指针
fmt.Printf("slice1 : 0x%x , %v\n", *(*uint64)(unsafe.Pointer(&slice1)), slice1)
fmt.Printf("silce2 : 0x%x , %v\n", *(*uint64)(unsafe.Pointer(&silce2)), silce2)
fmt.Printf("slice3 : 0x%x , %v\n", *(*uint64)(unsafe.Pointer(&slice3)), slice3)
fmt.Printf("slice4 : 0x%x , %v\n", *(*uint64)(unsafe.Pointer(&*slice4)), *slice4)//由于 new 返回的是一个指针,所以用 *slice4 来取值
if slice1 == nil { fmt.Printf("slice1 == nil\n")}
if silce2 == nil { fmt.Printf("silce2 == nil\n")}
if slice3 == nil { fmt.Printf("slice3 == nil\n")}
if *slice4 == nil { fmt.Printf("slice4 == nil\n")}
//slice1 : 0x0 , []
//silce2 : 0x1190370 , []
//slice3 : 0x1190370 , []
//slice4 : 0x0 , []
//slice1 == nil
//slice4 == nil
}
我们可以看到 nil切片 array 是 nil, 空切片的 array 是一个非nil 的指针指向某个地址
5. 切片浅拷贝与深拷贝
很久以前学PHP的时候我们就讲过浅拷贝和深拷贝,在Go中,浅拷贝相当于复制引用,深拷贝相当于复制值。
例如:
slice1 := []int{1, 2, 3}
slice2 := slice1
slice3 := slice1[0:2]
fmt.Println(slice1, slice2, slice3)
slice2[0] = 2
fmt.Println(slice1, slice2, slice3)
//[1 2 3] [1 2 3] [1 2]
//[2 2 3] [2 2 3] [2 2]
上面的这种方式叫浅拷贝,实际上这种方式指向的底层数组是同一个,因此如果改了值,所有的切片都会跟着变化
然后我们看看深拷贝
slice := []int{10, 20, 30, 40}
slice2 := make([]int, len(slice))
copy(slice2, slice)
slice2[0] = 20
fmt.Println(slice, slice2)
//[10 20 30 40] [20 20 30 40]
使用copy函数可以实现深拷贝,实际上 copy 函数的实现就是 slicecopy。
深拷贝得到的切片是一个新的切片,底层数组和来源切片用的不是同一个,因此修改新切片不会影响到旧的切片
其实使用 for range 的时候也是用的拷贝的
func main() {
slice := []int{10, 20, 30, 40}
for index, value := range slice {
fmt.Printf("index = %d value = %d \n", index, value)
value = 1 // 这种改法没有用,得用slice[k] = 1 这种才行
}
fmt.Println(slice) // [10 20 30 40]
}
6. 牛逼的扩容机制
关于切片,大家最关心的还是他的扩容机制。
我们一起看下核心代码逻辑。
// et 是切片的类型, old 是要扩容的切片,cap 是要扩容的大小
func growslice(et *_type, old slice, cap int) slice {
...
// 先保存旧容量
newcap := old.cap
// 两倍旧容量
doublecap := newcap + newcap
// 如何要扩容的大小大于两倍容量,则新容量使用要扩容的大小
if cap > doublecap {
newcap = cap
} else {
if old.cap < 1024 { // 如果旧容量小于1024,则使用两倍策略
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap { // 如果旧容量在 0 到 要扩容的大小之间,使用 1.25 倍策略,一直循环直到大于要扩容的大小
newcap += newcap / 4
}
// 如果 newcap 小于等于0,则使用指定扩容的大小
if newcap <= 0 {
newcap = cap
}
}
}
...
}
三、总结
本篇文章主要讲了在Go语言中数组和切片的基本概念、使用方法,和一些基本原理,在日常的业务开发中,实际上很少会使用数组,因为切片的优势相对数组更大。而且在数据结构中,实际上只有两个基础数据结构,数组和链表,但是很多语言为了更加方便的使用,都会基于它们再次封装,衍生出各个语言自己独特的数据类型。因此不管是哪种数据类型,要么是基于数组实现,要么是基于链表实现,要么就是两个结合起来。了解本质可以更好的帮助我们熟悉其算法以及减少使用不当的场景。

















 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











