







DDR3联合HDMI进行图片数据的传输
- 项目概况
- DDR3 IP核调用及介绍
- DDR3 IP核的调取
- IP核引脚以及功能说明
- DDR3内部模块
- 仲裁模块
- 读写模块
- 仿真测试
- DDR3外部模块
- 外部读写模块
- 内外联合测试仿真
- HDMI模块
- encode模块
- par2ser模块
- HDMI仿真测试
- DDR3联合HDMI
项目概述
本次项目是为了实现DDR3联合HDMI,进行一幅1024*768图片的显示,在PC机上利用串口讲图片的数据发送给DDR3并存入到DDR3中,然后由HDMI将数据取出来,显示到显示器上。
项目框图如下:
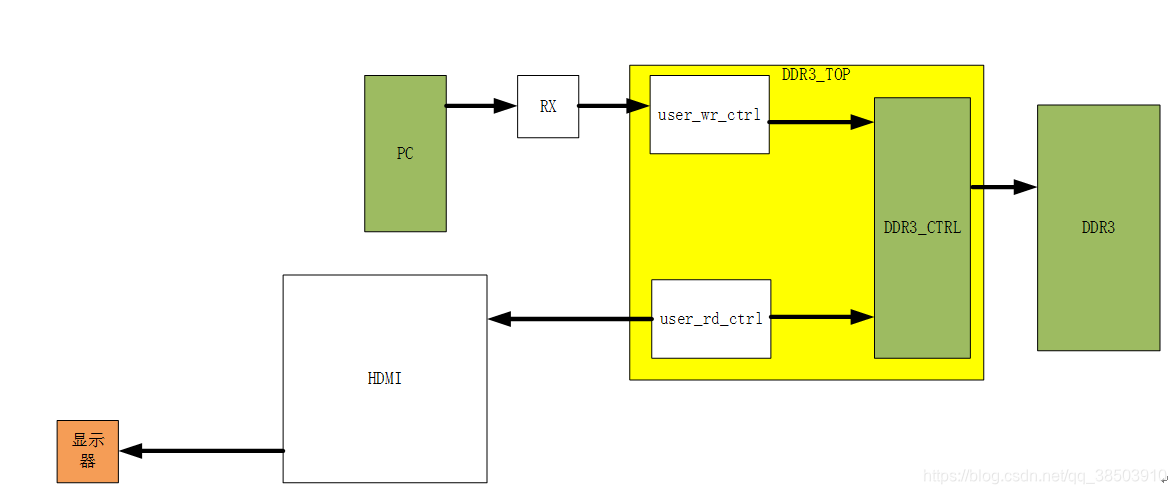
本次项目的主要目的是通过DDR3和HDMI这种联合的方式,掌握DDR3的存取原理和HDMI的显示原理,自己搭建起DD3的控制器,将DDR3灵活的运用起来,同时编写HDMI_trans模块去发送我们想要显示的图像数据,以达到通用的效果。
实验环境为Vivado 16.4,Win10,64位,采用开发板为XC7A35T-2FGG484。
DDR3 IP核调取及介绍
一.DDR3 IP核的调取:
1.调取方法
A7的DDR3调用方法和Spartan6一样,通过GUI界面调取IP的方法来调用DDR3
下面为DDR3 IP核调用事项(放大后看清):
在IP界面中选择7系列的MIG:
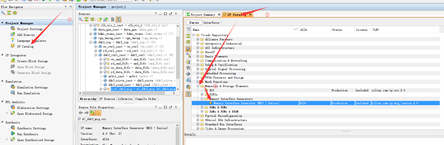
选择你的IP名字:
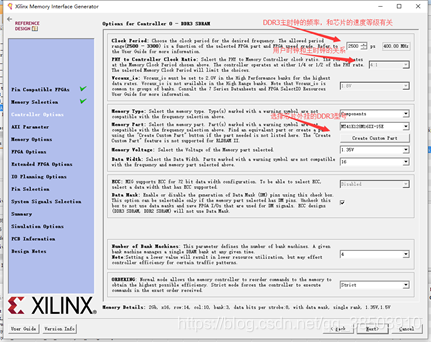
这一页改动很多,而且很重要,在这里有较为详细的解释:
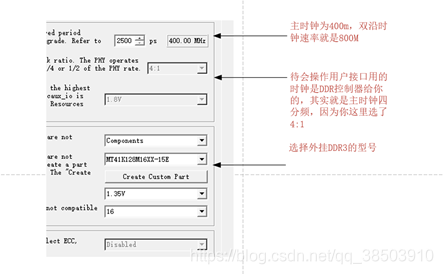
DDR3数据的位宽是16位,并且是双沿数据,因为在用户端是只能上沿发送数据,所以用户端的数据位宽就为:16*2*4==128位的,这个的*4就是4:1造成的。
关于参考时钟:理论上应该给一个稳定200M的时钟,用来恢复主时钟的时钟质量,
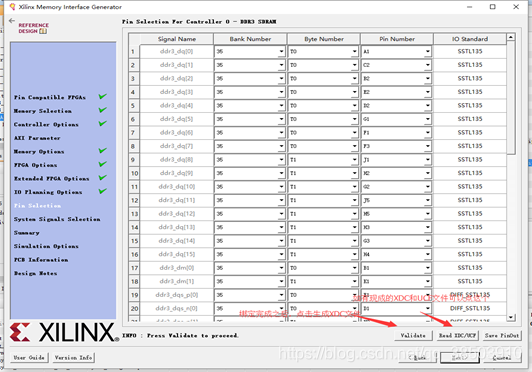
下面的一个页面全部选默认,到了绑定管教的界面直接绑定管脚就好了
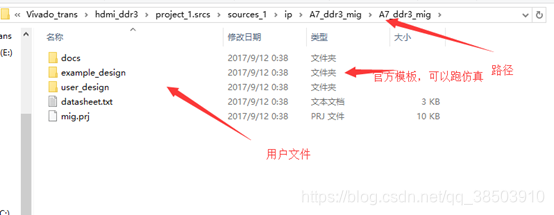
接下来一点默认到生成IP核,之后会在你的工程中生成这样的文件夹:
在调取完成DDR3的IP核之后,就可以启动仿真来测试一下:
2.IP核的例化
首先建立一个顶层文件,将DDR3的IP核例化进来:
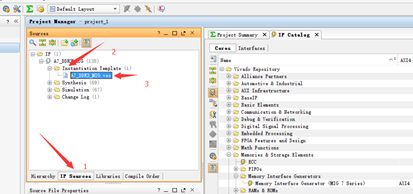
在这个界面可以找到DDR3 IP核的例化模板,将IP核例化进去,然后需要将连接DDR3的绑定管脚的部分引到外面去,而那些中间用户变量需要模块中声明(ddr3开头为引脚,app的则为用户变量):
3.IP核的仿真
将ip核例化好之后,在tb里面将顶层文件例化一下,声明各种中间变量,同时,还需要加一个DDR3的模型到tb中来充当DDR3。模型的位置如下:
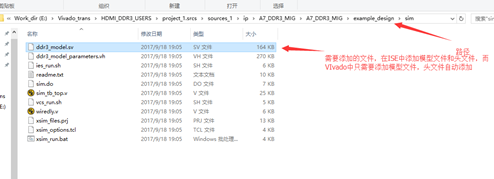
启动仿真打开ModelSim之后,选择添加ddr3_ctrl模块,运行一段时间,如果init_calib_complete拉高,则表示DDR3初始化成功,调取DDR3 IP核可以进行更进一步的操作。
二 . 功能及引脚介绍
- DDR3时序介绍:
如果想要完全的用起来DDR3的IP核,需要知道它内部的运作原理和时序。通过查阅相应的DataSheet可知:A7的DDR3突发长度是固定为8的,也就是一次突写写8次单位地址的长度,如果DDR3的数据线为8位,突写一次就需要些8*8=64bit,而16位的话则需要16*8=128bit。
- DDR3的两种模式:
DDR3有4:1和2::1两种模式,,这个4:1 和 2:1 是我们在调取IP的时候可以选择的,这里的 4:和2指的是DDR3与DDR3的IP核完成一次突发所需要的时钟周期的长度,而1指的是用户端向DDR3的IP核发送数据所需要的时钟周期数,不同的模式,有不同时序。 以数据线为8为例来说:
如果选择2:1的模式,用户需要用两个时钟周期发送一次突写的数据,8*8=64,一个时钟周期也就是32位,而DDR3与IP核交互数据时,需要64/2(双沿)/8(单位数据位宽)=4; DDR3与IP核交互完成一次突发所需要的时钟周期,和用户和IP核完成一次突发所需要的时钟周期之比,就为DDR3的这两种模式。
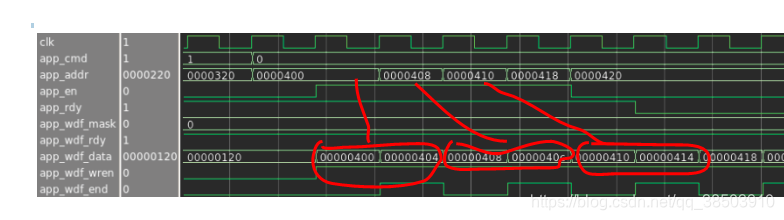
同样的4:1也是如此,只不过在用户端与IP核交互时,一次突写只需要一个时钟周期。而DDR3与IP核交互数据不变。
DDR3有许多的时钟,不管是什么时钟,我们都需要弄清楚,从最开始调用IP核说明: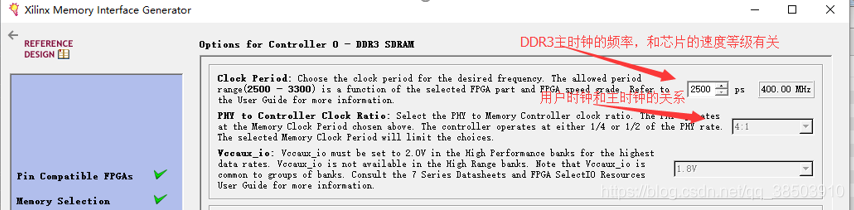 这个Clock Peried就是DDR3的时钟,为400M,和芯片的种类和速度等级有关。而下 面的4:1就是上面所说到的DDR3的两种模式,也就是用户时钟和DDR3时钟的关系。
这个Clock Peried就是DDR3的时钟,为400M,和芯片的种类和速度等级有关。而下 面的4:1就是上面所说到的DDR3的两种模式,也就是用户时钟和DDR3时钟的关系。

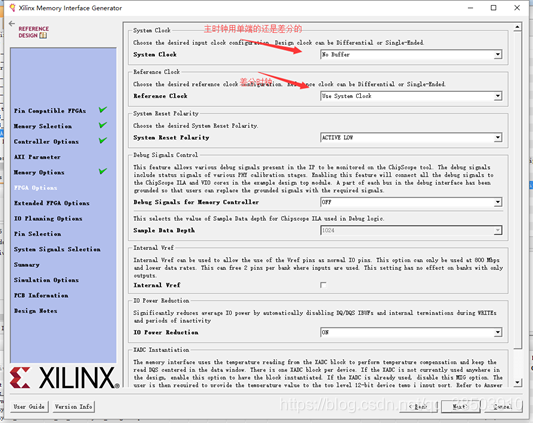
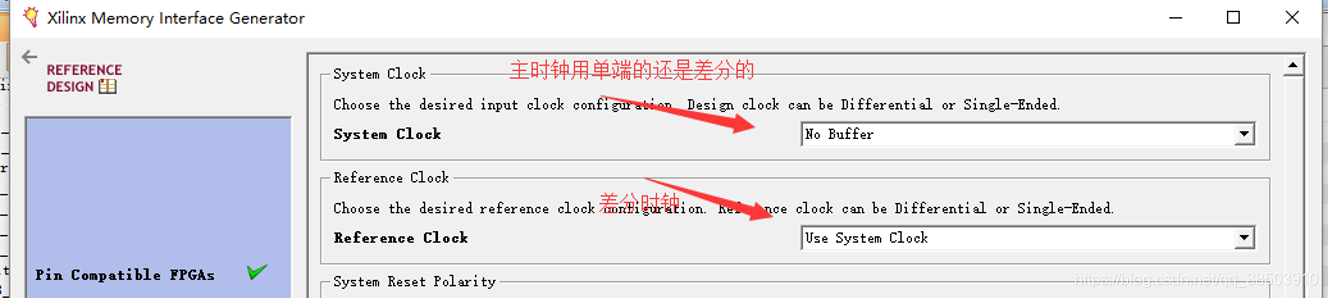 Input Clock Period :这个时钟是输入给DDR3 IP核的时钟,IP核中自带了一个PLL,它会将输入的时钟分倍频到DDR3所需要的时钟。如果输入到 IP 核的时钟是外部晶振生成的切单端,那就选择Singel_Ended ,如果是差分的,就选择Differential,但是现在我们决定用外部PLL产生一个200M的时钟,来给IP核,而PLL自带BUFFG,所以选择 No Buffer。
Input Clock Period :这个时钟是输入给DDR3 IP核的时钟,IP核中自带了一个PLL,它会将输入的时钟分倍频到DDR3所需要的时钟。如果输入到 IP 核的时钟是外部晶振生成的切单端,那就选择Singel_Ended ,如果是差分的,就选择Differential,但是现在我们决定用外部PLL产生一个200M的时钟,来给IP核,而PLL自带BUFFG,所以选择 No Buffer。
Reference Clock :参考时钟,利用这个参考时钟,来生成用户的100M时钟(ui_clk),它的精度要求范围为199M-201M,如果上面选择输入时钟为200M,则这个可以用输入的系统时钟来代替,如果不是则需要另外开一个接口输入进来200M的时钟。
- IP核的读写时序:
- 写时序:
IP核往DDR3里面写入数据时,需要向AXI总线那样,给出一定的握手信号才能完成。
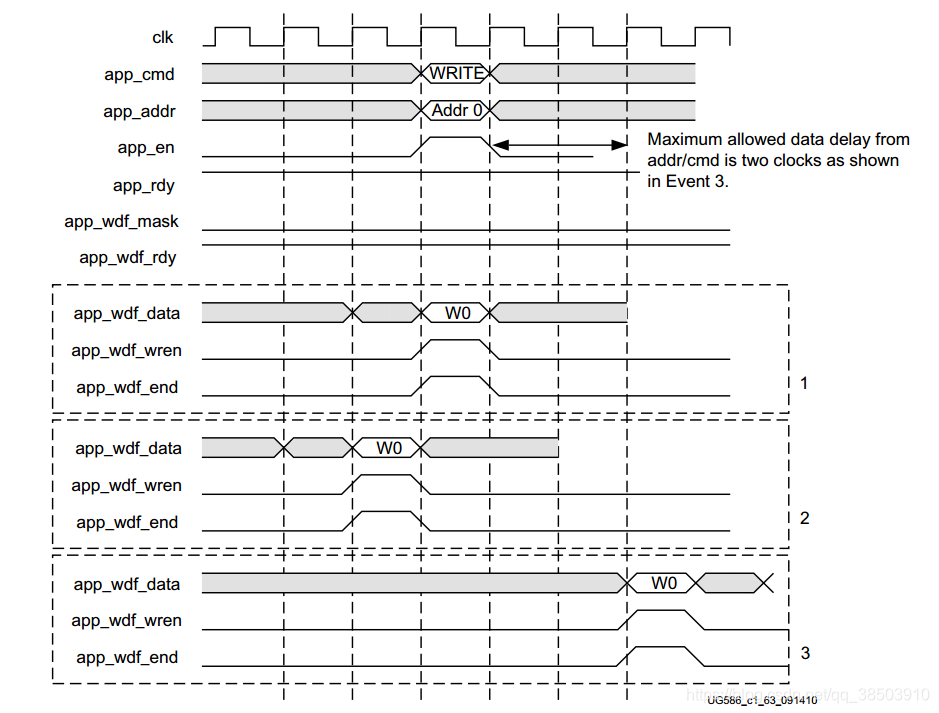
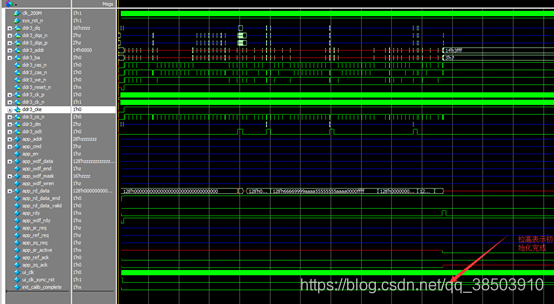
由上图可知:在采用4:1的模式下,数据(app_wdf_data[127:0])和写使能(app_wdf_wren)和数据突写结束信号(app_wdf_end)同时出现,标志着此时数据有效,但只有当准备信号(app_wdf_rdy)信号有效时,才标志着数据被暂时的缓存到了IP核中,只有当给出了写的命令,和地址,而且app_en 和 app_rdy同时拉高,表示命令(3’b000)和地址被接受,就会将缓存在IP核中的数据,真正的写入到了DDR3中。写的命令和地址,可以提前与数据,也可以同时或者落后,但是数据落后的时间不应超过两个时钟周期。
为了确保能正确的将数据送入到DDR3中,我们只选择一种模式,而且是和Spartan一样的先给出数据,再给出命令。
- 读时序:
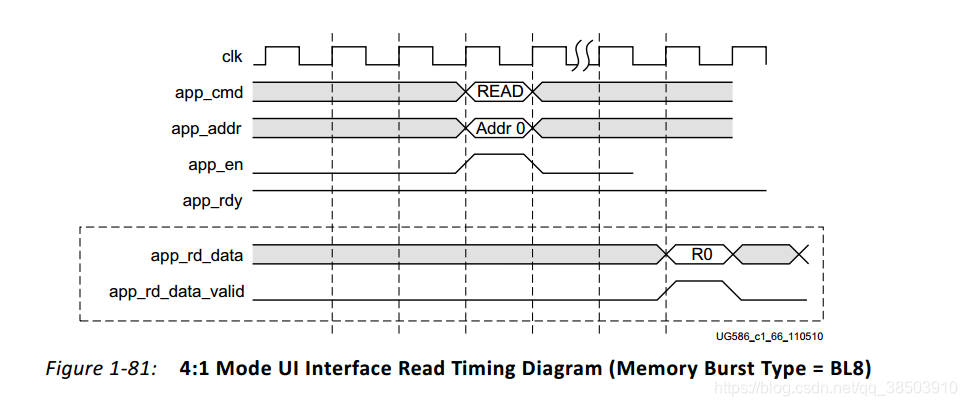
在 4:1的模式下,首先给出读的命令(3‘b001)和地址,当app_en和app_rdy信号同时有效时,表示命令和地址被接受,在接下来的一段时间内,IP核会将所读地址的数据读出来并且伴随着一个有效的同步信号(app_rd_data_valid)。
- 读写时序总结:无论是读还是写,都会是分为两个部分,命令端和数据端。
对于写来说,先给出数据端(app_wdf_data[127:0], app_wdf_end, app_wdf_wren, app_wdf_rdy),等数据端被IP核接受了之后,发送命令端的信号(app_cmd,app_addr,app_en,app_rdy),将数据写入到DDR3中,只有这几个信号之间相互配合,才能将数据写入到DDR3中,完成一次数据写的突发。
对于读来说,是先给出命令端信号(app_cmd, app_addr, app_en, app_rdy),当IP核接受到这些命令之后,就会将数据端的信号送出来(app_rd_data[127:0], app_rd_data_valid)。从而完成一次数据读的突发。
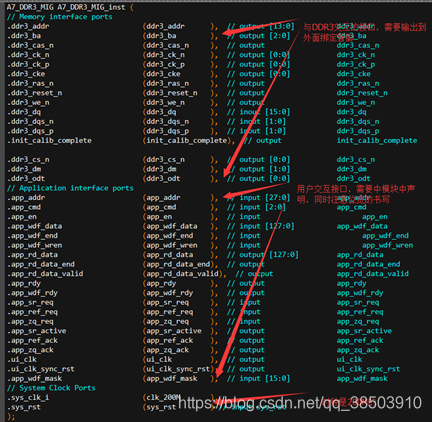
- IP核引脚及功能说明:
IP的引脚共分为两个部分,一个是和DDR3直接交互的引脚部分,另一个则是和用户端交互的。
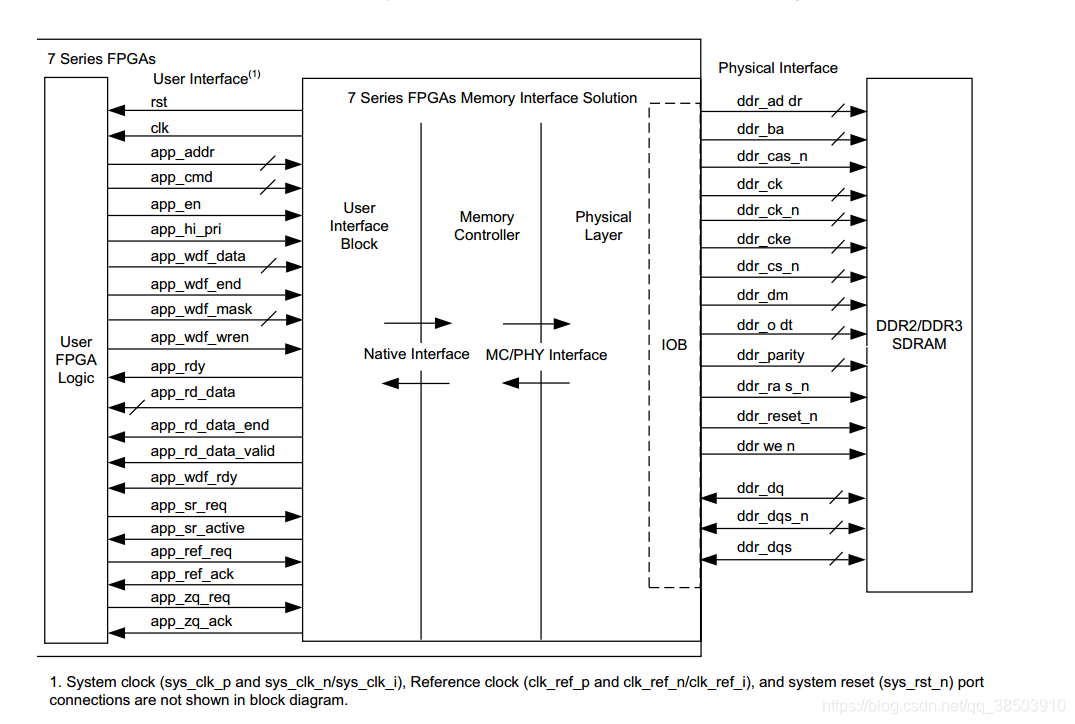
下面是对引脚的说明:
| Name | 输入输出 | 备注 |
| ddr3_dq[15:0] | inout | DDR3的数据位宽,传输数据的单位以它位基础,如果来8位,则是以字节为单位,而16位则是以Word为单位 |
| ddr3_dqs_n[1:0] | inout | 数据选通。读时是输出,边缘与读出的数据对齐。写时是输入,中心与写数据对齐。 |
| ddr3_dqs_p[1:0] | inout |
|
| ddr3_addr[13:0] | output | 和SDRAM一样采取行列复用的原则 2^3*2^14*2^10=2^27=128M |
| ddr3_ba[2:0] | output | BANK地址 |
| ddr3_ras_n | output | 行地址选通,低有效 |
| ddr3_cas_n | output | 列地址选通,低有效 |
| ddr3_we_n | output | 写使能,低有效 |
| ddr3_reset_n | output | DDR3的复位,低有效 |
| ddr3_ck_p | output | DDR3系统时钟,由200M倍频而来,差分对 |
| ddr3_ck_n | output |
|
| ddr3_cke | output | 时钟使能,高有效 |
| ddr3_cs_n | output | 片选,低有效 |
| ddr3_dm[1:0] | output | Data mask DDR3输入数据的掩码 |
| ddr3_odt | output | 片上终端使能 |
| app_addr[27:0] | input | 用户地址, |
| app_cmd[2:0] | input | 用户命令,3‘b000(写),3’b001(读) |
| app_en | input | 命令使能信号,拉高表示命令被使能 |
| app_wdf_data[127:0] | input | 写数据,表示需要往DDR3里写的数据 |
| app_wdf_end | input | 一次突发的结束 |
| app_wdf_mask[15:0] | input | 数据掩码。一位掩码可以掩掉8bit数据,掩码位宽等于数据位宽/8 |
| app_wdf_wren | input | 数据写使能 |
| app_rd_data[127:0] | output | 读数据,DDR3中读取出来的数据 |
| app_rd_data_valid | output | 读数据的同步信号 |
| app_rdy | output | IP核命令准备信号,拉高表示此时IP核能接受命令 |
| app_wdf_rdy | output | IP核写命令信号,拉高表示此时IP核能接受数据 |
| ui_clk | input | 用户时钟,用参考时钟分频而来 |
| ui_clk_sync_rst | input | 用户时钟复位 |
| init_calib_complete | output | DDR3初始化完成信号,一切对DDR3的操作应该在初始化完成之后。 |
IP核与DDR3交互的接口,不需要我们去关心,Xilinx已经帮我们做好了。对于DDR3,都是基于用户接口来操作的,所以需要将app接口的各种信号相互配合,灵活的运用起来,已达到我们想要的目的。
DDR3内部模块
在A7这块芯片中,DDR3 IP核的用户接口和AXI总线有类似的地方,并没有像Spartan6那样方便,DDR3需要同时和不同的模块进行交互时在,这样的接口就显得有些不足,并没有通用性,为了以后方便使用A7的DDR3,可以在Spartan6的基础上,将A7的DDR3接口和用户交互功能做到和Spartan一样,即保证了通用性,还具有一定的统一性。
下图为Spartan 6 中的DDR控制器:
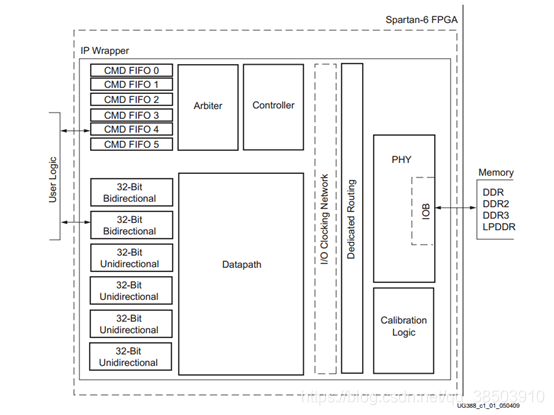
我们可以仿照Spartan6 作一个同样的:
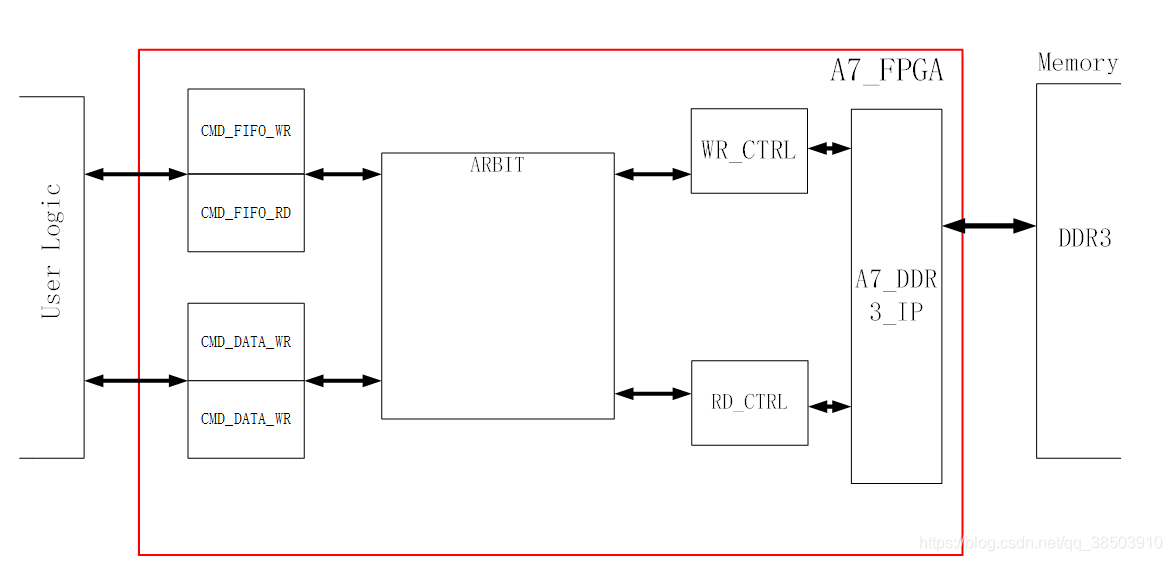
我们可以将红色的线条内的逻辑,和Spartan6 一样具有相同的功能,用户只需要将命令和数据存储到命令FIFO和数据FIFO中,仲裁状态就会判断是否去执行读和写,从而启动WR_CTRL 和RD_CTRL,利用WR_CTRL 和RD_CTRL去和A7_DDR3的IP和交互,完成数据的收发
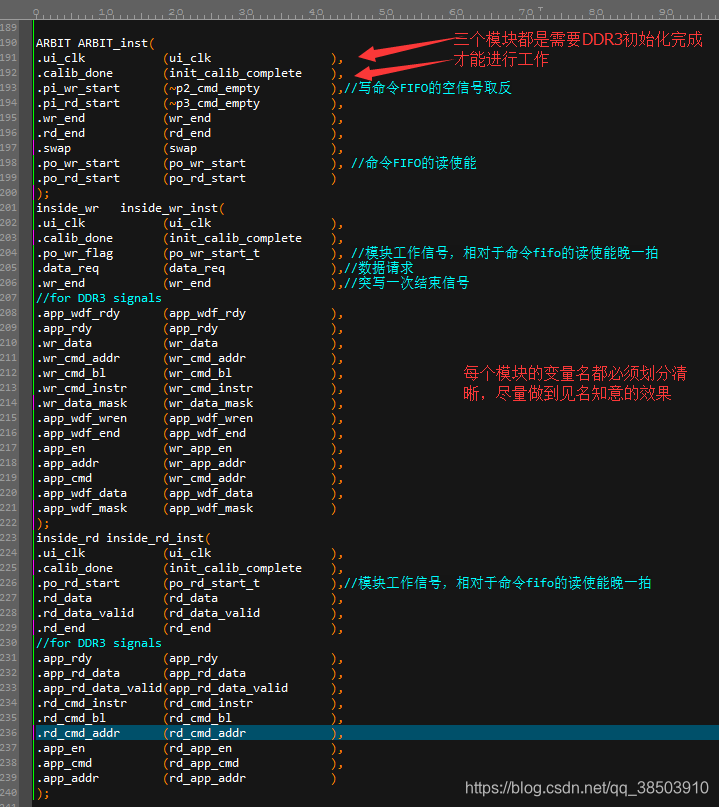
一.仲裁状态:
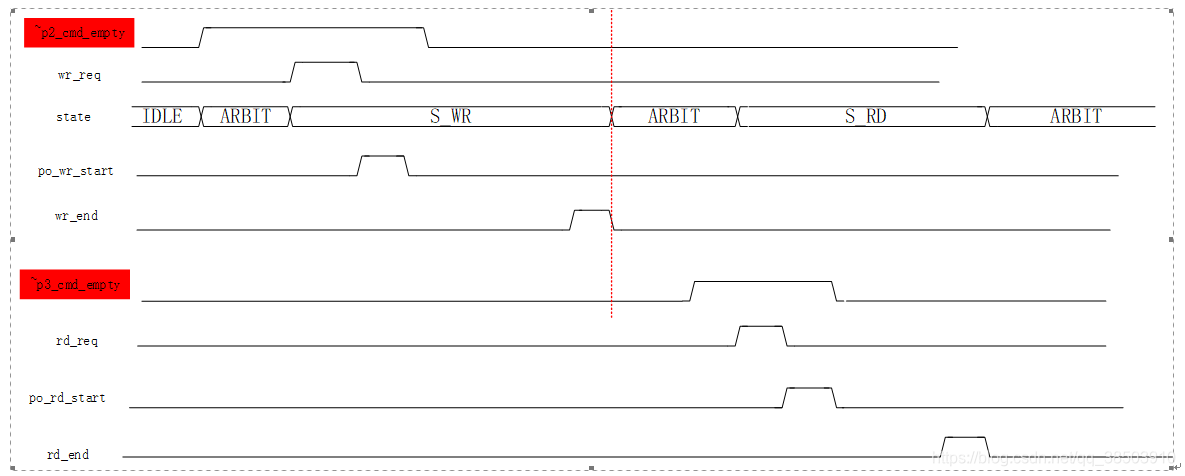
仲裁模块是用户端和读写端的桥梁,同时也是控制器,当读或者写的命令FIFO中不为空,表示用户端发出读写的请求,则启动仲裁模块,下图为仲裁模块的时序图:
 正在上传…
正在上传…当命令fifo不就为空时,状态机就会从仲裁状态跳转到相应的读写状态,同时产生一个内部读写模块的启动信号,这个启动信号又去读取命令fifo中数据传到相应的读写模块中,当完成一次自定义的突发时,读写模块回传一个结束标志,状态机又跳转到仲裁状态,等待下一次命令的到来。
接口定义解释:
| Name | 输入输出 | 备注 |
| ui_clk | Input | IP核中由参考时钟分屏出来的100M用户时钟 |
| calib_done | Input | IP核初始化完成信号,一切对IP核的操作需要在它拉高之后 |
| pi_wr_start | Input | 写命令FIFO的空信号取反,不空则表示有命令输入进来需要进行相对应的状态的跳转 |
| pi_rd_start | Input | 读命令FIFO的空信号取反,不空则表示有命令输入进来需要进行相对应的状态的跳转 |
| wr_end | Input | 写模块结束一次自定义突发长度时信号 |
| rd_end | Input | 读模块结束一次自定义突发长度时信号 |
| po_wr_start | Output | 写模块开始一次自定义突发长度时信号 |
| po_rd_start | Output | 写模块开始一次自定义突发长度时信号 |
二.内部读写模块:
1.写模块
对于写的操作,仲裁模块给出一个写的启动信号,然后模块开始工作,需要给出写的数据(app_wdf_data[127:0]),和写使能(app_wdf_wren),当IP核准备好接收这些数据时,就会把写准备拉高(app_wdf_rdy),那么数据就会被存入到IP核中,等到命令使能(app_en)和命令准备(app_rdy)同时拉高时,就会将数据写入到给出的地址当中。完成一次突发写的操作。用于DDR3的数据线为16位,一次固定突发为8,那么采用4:1的模式,用户数据位宽位128位,即一个用户时钟,就可以完成一次DDR3的突发,所以我们可以自定义IP核完成突发的个数。
下图为内部写的时序图:

当收到wr_start_flag时,启动并完成bl=64的一次写。由于两个rdy信号不受我们控制,所以需要计数器去控制命令端和数据端的个数。当写使能和些准备同时为高,当前数据被写入,还需要data_req信号输出到外部去请求数据。命令端和数据端的使能信号和准备信号同时拉高了突写次数时,就完成了一次突发,可以将使能信号拉低,同时计数器归零,以备下一次突发。关于app_en的启动,可以检测app_wdf_wren的上升沿来判断。
接口定义解释:
| Name | 输入输出 | 备注 |
| ui_clk | input | IP核中由参考时钟分屏出来的100M用户时钟 |
| calib_done | input | IP核初始化完成信号,一切对IP核的操作需要在它拉高之后 |
| po_wr_flag | input | 模块工作信号,相对于命令fifo的读使能晚一拍 |
| data_req |
| 数据请求 |
| wr_end |
| IP核突写一次用户自定义长度的结束信号 |
| app_wdf_rdy | input | IP核写准备信号,拉高表示能结束数据写入 |
| app_rdy | input | IP核命令准备信号,拉高表示能接受命令写入 |
| wr_data[127:0] | input | 外模块传进来需要向IP核写入的数据 |
| wr_cmd_addr[27:0] | input | 外模块传进来需要给IP核的写入地址 |
| wr_cmd_instr[5:0] | input | 外模块传进来需要给IP核的一次用户自定义的突写长度 |
| wr_cmd[2:0] | input | 外模块传进来需要向IP核写入的命令 |
| wr_data_mask[15:0] | input | 外模块传进来数据掩码,某一位为高则表示相应的字节数据被掩掉 |
| app_wdf_wren | output | IP核数据写使能 |
| app_wdf_end | output | IP核突写的结束信号 |
| app_en | output | 命令使能信号 |
| app_addr[27:0] | output | 用户地址 |
| app_cmd[2:0] | output | 用户命令 |
| app_wdf_data[127:0] | output | 用户写数据 |
| app_wdf_mask[15;0] | output | 用户数据掩码 |
2.读模块:
当仲裁模块传过来读的启动信号,RD_CTRL就会启动,读取一次用户自定义的突发长度的数据。 时序图如下:

启动信号拉高后,app_en和app_rdy这两个命令端的必须同时拉高用户自定义突发长度个时钟周期,同时给出读命令和地址,然后延迟几个时钟周期,就会产生app_rd_data[127:0]和app_rd_data_valid信号。当app_rd_data_valid为高,表示读数据有效,而且当app_rd_data_valid拉高了用户自定义突发长度时,表示一次用户自定的突写结束,此时传出一个rd_end信号,告诉仲裁模块退出读状态
3.内部连线:
当内部模块完成之后,由于各个模块相互约束,交错连接,连线成了设计的一个难点,需要十分的认真仔细,注意位宽,给各个信号取不易混淆的变量名,一步一步,从顶端输入输出,一步一步连接下去。在顶端先加入Spartan一样的接口:
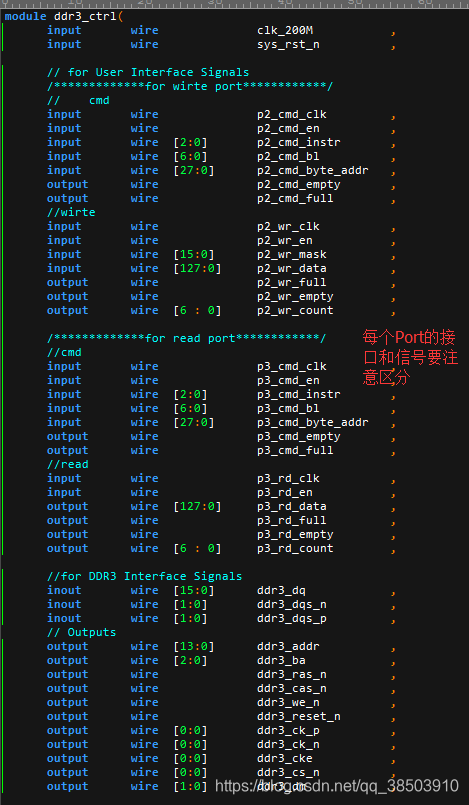
接下来就需要例化四个fifo,分别是命令的读和写的fifo,数据的读和写的fifo,命令fifo深度为16,位宽位({p2_cmd_instr[2:0],p2_cmd_bl[6:0],p2_cmd_byte_addr[27:0]})}因为对其去求量不大,可以采用分布式ram以减少逻辑资源的浪费。数据fifo可以用深度为64,位宽位144(p2_wr_mask[15:0],p2_wr_data[127:0]),读数据fifo中掩码的部分可以不用,用0代替。
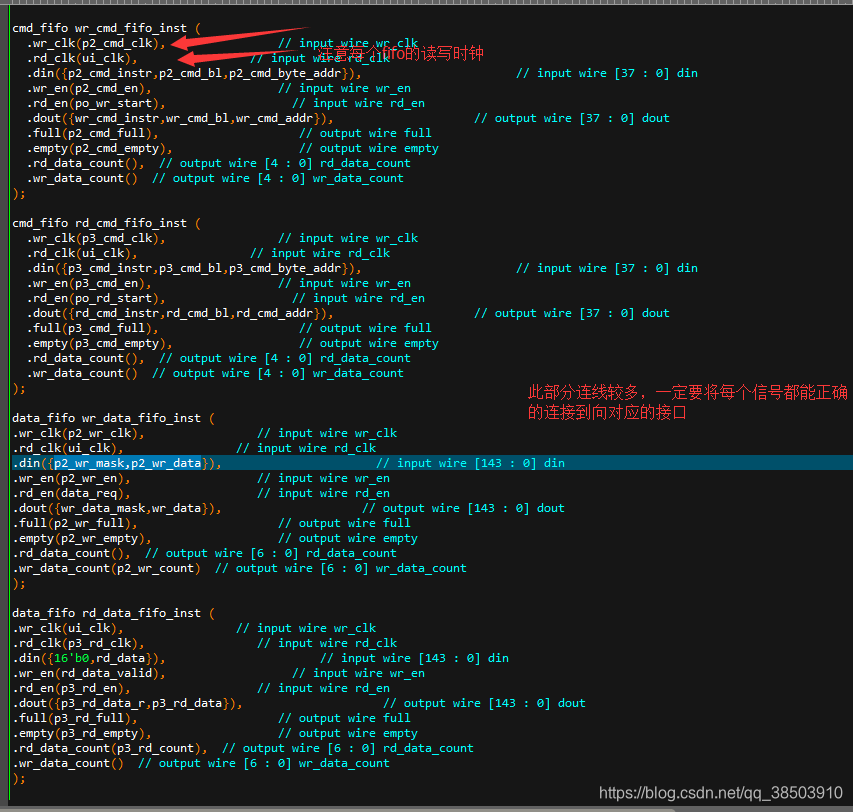
接下来就内部读和写模块,仲裁模块之间的相互接连,仲裁模块的启动信号是命令fifo的空信号,不空则跳转到相应的状态,同时读出命令fifo的数据给相对的读模块或者写模块,并且启动该模块,当完成时,传回一个结束信号,标志着此次突发完成,仲裁模块有重新判断命令FIFO的空信号,这样就使得各个模块循环起来。
连线完成之后,DDR3_CTRL模块就基本上和Spartan6的IP核一致了,具有通用性核统一性。
三.模块功能仿真,新建一个顶层,将DDR3_CTRL模块例化进去,通过控制P2 和 p3口,来达到写入数据,并且能读出来的效果。
创建一个data_gen模块用于产生测试数据和读写信号,先将0-3f 64个数据写入到DDR3_ctrl模块的写数据fifo中,然后在给一个写的命令,仲裁模块会判断是否写,并且启动内部的写模块,从而将存储在DDR3_ctrl的写数据FIFO中的数据写入到DDR3中,然后在data_gen模块中在产生一个读的命令,仲裁模块就会启动内部的读模块,从而将数据从DDR3中读取出来存到读数据的FIFO中。一次的读和写给出相同的地址和突发长度,就会将刚刚写入的数据读出来,以达到完成ddr3_ctrl模块测试的效果。
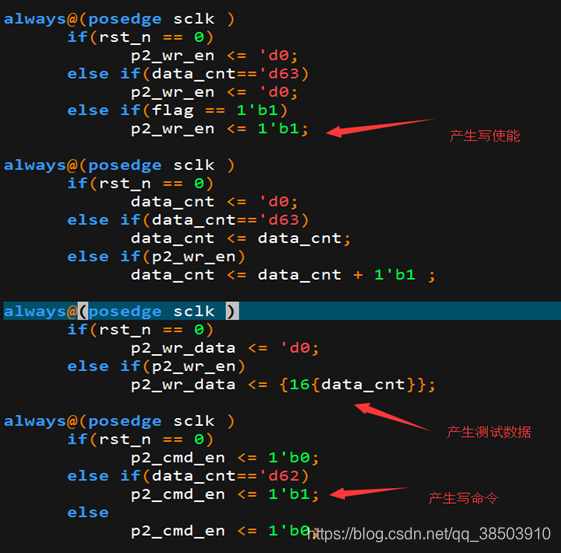
由上图所示,写入 0-3f数据后,又读出来0-3f,同时伴随着app_rd_data_valid同步有效信号,证明模块测试正确,达到了我们想要的目的。
DDR3 外部模块
一.外部读写模块测试。
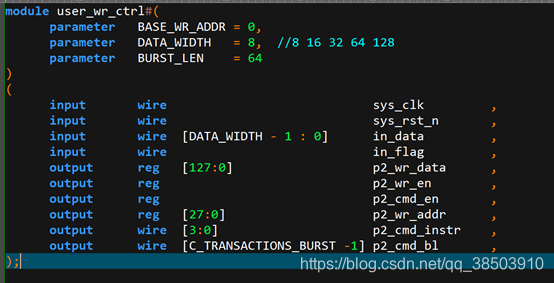
外部的读写模块不同于内部,是直接与用户交互的模块,所以分别取名user_wr_ctrl和user_rd_ctrl 以区分内部和外部读写模块。在外部模块中,通过控制DDR3_CTLR的用户接口,达到和DDR3读写交互的效果,可以适当添加一下全局的参数来增加其通用性。
- 写模块:
无论外部的数据是连续的还是间断的写入,都应该能将数据完整的写入到DDR3中,
所以在本模块中,应该起到一个适配的作用,将传过来的数据,在位宽和数量上进行一定的处理,假设数据是由串口过来的八bit数据图像数据,由于DDR3_ctrl的数据位宽位为28位,所以传给DDR3_ctr一次需要16次串口发过来的数据拼接在一起发送。本模块采用尝试采用全局参数的方法,不仅可以支持串口的8位数据拼接,也可以支持其他不同位宽的数据拼接。时序图如下:
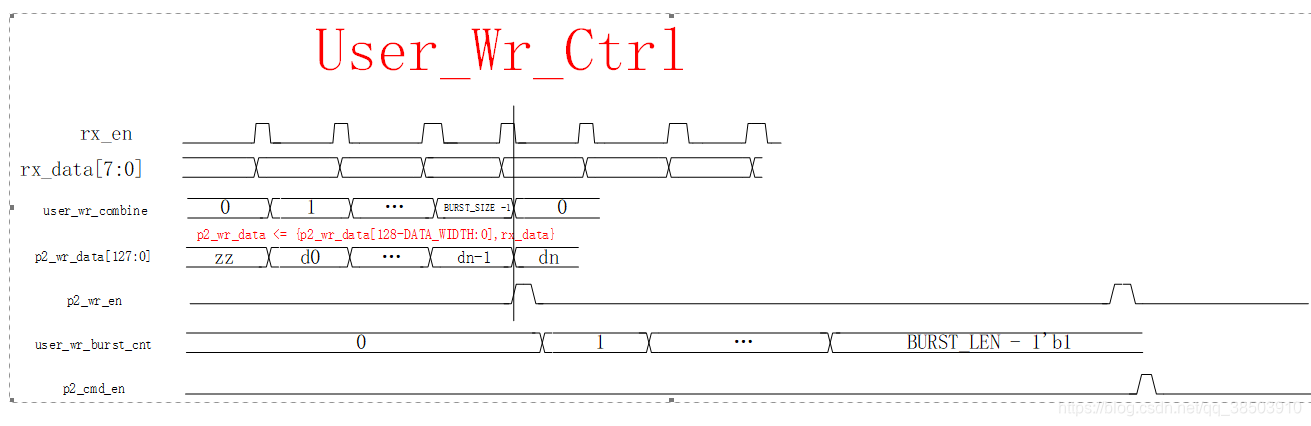
将传送过来的数据没拼接成128位时,就启动一次写使能,然后将128位数据写入到IP核中,等到突发的次数够了,启动一次写的命令,将IP核的数据,写入到DDR3中。
全局参数相关变量: 需要拼接的数据位宽,突写长度,读写基地址
利用二进制一位代表一个位宽的特点,采用下图函数计算参数的位宽:
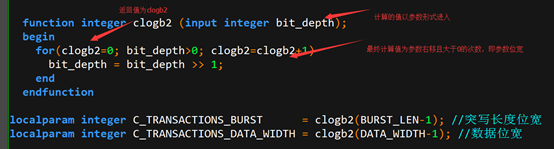
| Name | 输入输出 | 备注 |
| sys_clk | Input | 系统时钟 |
| sys_rst_n | Input | 系统复位 |
| in_data[8:0] | input | 输入数据 |
| in_flag | input | 输入数据的同步信号 |
| p2_wr_data[127:0] | output | 拼接起来的数据 |
| p2_wr_en | output | 传给DDR3_ctrl模块的写使能 |
| p2_cmd_en | output | 传给DDR3_ctrl模块的命令使能 |
| p2_wr_addr | output | 传给DDR3_ctrl模块的地址 |
| p2_cmd_instr | output | 传给DDR3_ctrl模块的命令 |
| p2_cmd_bl | output | 传给DDR3_ctrl模块的突写长度 |
- 读模块:
由于本次实验需要和HDMI联合进行图片的显示,由于两者的时钟不同,系统时钟为125M,而VGA的时钟为65M,所以需要在读模块中读取DDR3的数据,然后存储到一个用户fifo中,当HDMI场同步到来之后紧接着的第一个de有效信号表示显示的第一行,如果此时fifo的数据大于门限值,则可以将数据读出显示到HDMI上,而当fifo的数据小于一定的门限值时(可以是一行像素点的数据),读模块有继续向DDR3中读取数据,以此往复。形成循环。
时序图如下:
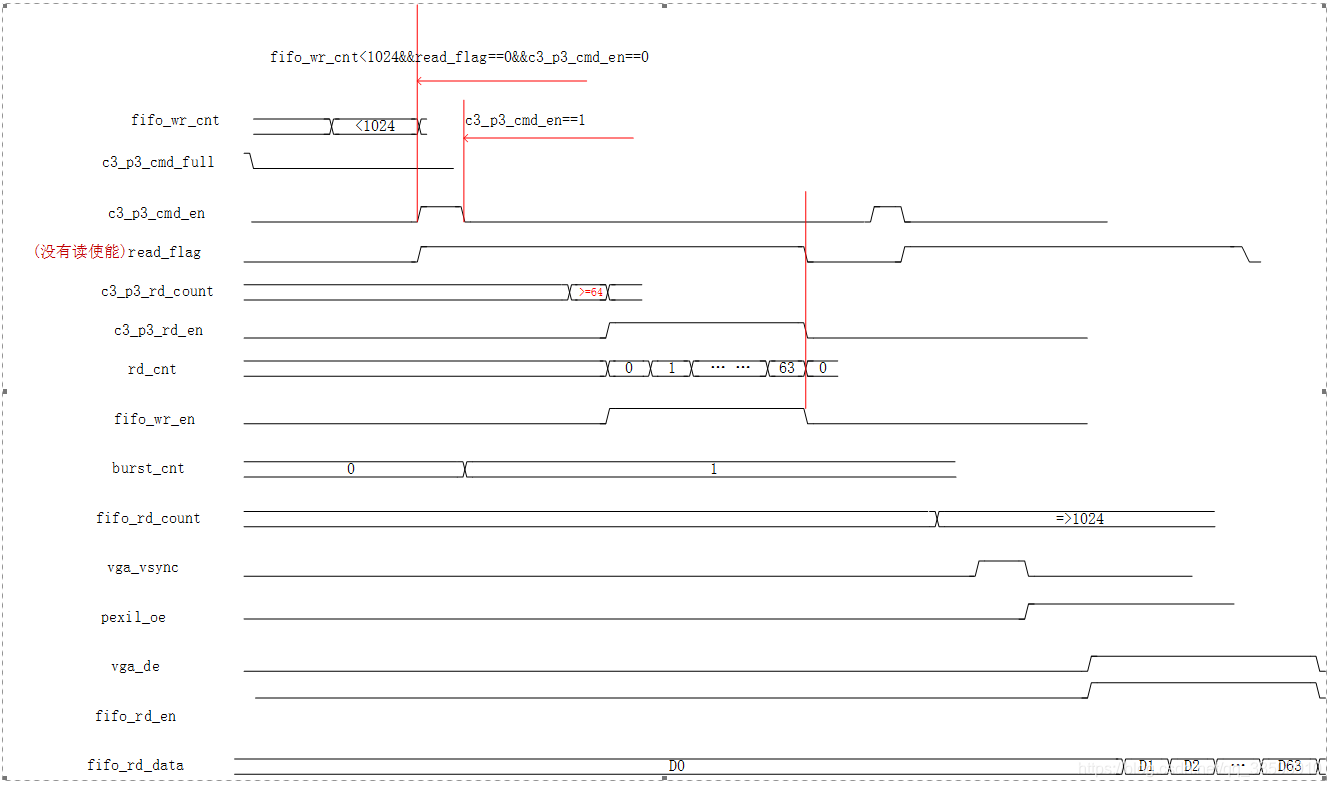
当fifo中的数据小于门限值时,需要向DDR3中读取数据填充fifo:先给一个读的命令(伴随着地址,命令,地址,完成之后地址加一,为下一次做准备),然后当DDR3_CTRL中读数据fifo存储到够一次突写的长度时,拉高读使能,将数据读出来并且存储到fifo中,当HDMI需要数据时(图像的第一行),打开读使能,并且正确的将128位数据合理的分拆成24位一组的RGB数据。这样的话,就完成了DDR3方面的工作。
模块引脚说明:
| Name | 输入输出 | 备注 |
| sys_clk | input | 系统时钟 |
| sys_rst_n | input | 系统复位 |
| vclk | input | VGA时钟,fifo的读时钟 |
| fifo_rd_en | input | Fifo的读使能,由HDMI模块给出 |
| v_sync | input | 场同步信号,用于同步图片 |
| pixel_rgb[23:0 | output | 像素点的RGB值,由fifo中读出 |
| p3_cmd_full | input | 读端口的命令fifo慢信号,不能再满的时候给出信号 |
| p3_rd_count | input | 读端口数据fifo存储的数量 |
| p3_rd_data[127:0] | input | DDR3中存储的RGB值,由 |
| p3_cmd_instr[2:0] | output | 传给DDR3_ctrl模块的命令 |
| p3_cmd_bl[6:0] | output | 传给DDR3_ctrl模块的突发长度 |
| p3_cmd_en | output | 传给DDR3_ctrl模块的命令使能 |
| p3_rd_en | output | 传给DDR3_ctrl模块的读使能 |
| p3_cmd_addr[27:0] | output | 传给DDR3_ctrl模块的读地址 |
拆分时序图如下:
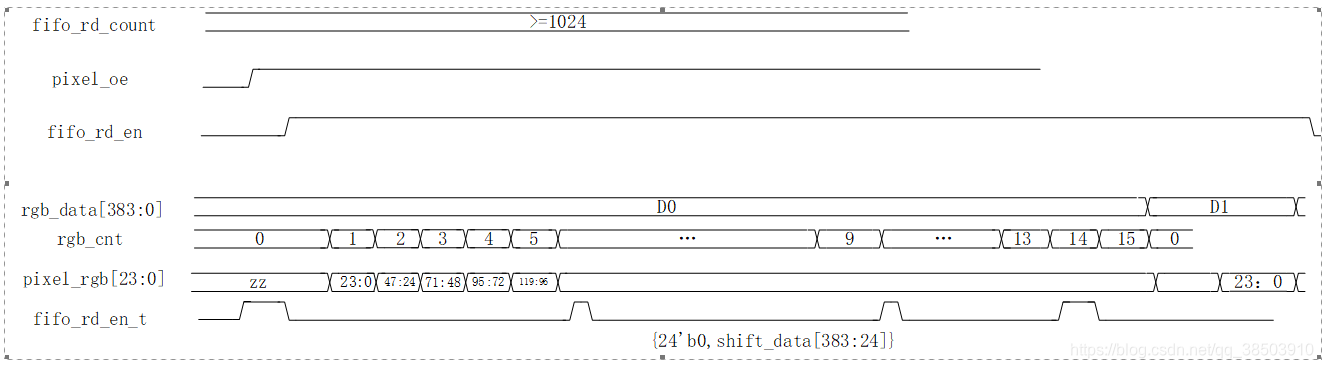
当fifo中有一定数量的值时,且场同步到了,此时拉高pixel_oe信号,作为数据和图像的同步信号,由于进来的数据为128位,而rgb的值为24位,不是整数倍的关系,股可以将128的数据每三个拼接在一起(128*3/24=16),先将384的shift_data填充满,当vga需要数据时,就将shift_data的低24位送出,然后右移24位,等全部移出后(rgb_cnt==15),在取出384位继续填充shift_data,以此往复,这样就循环起来了。
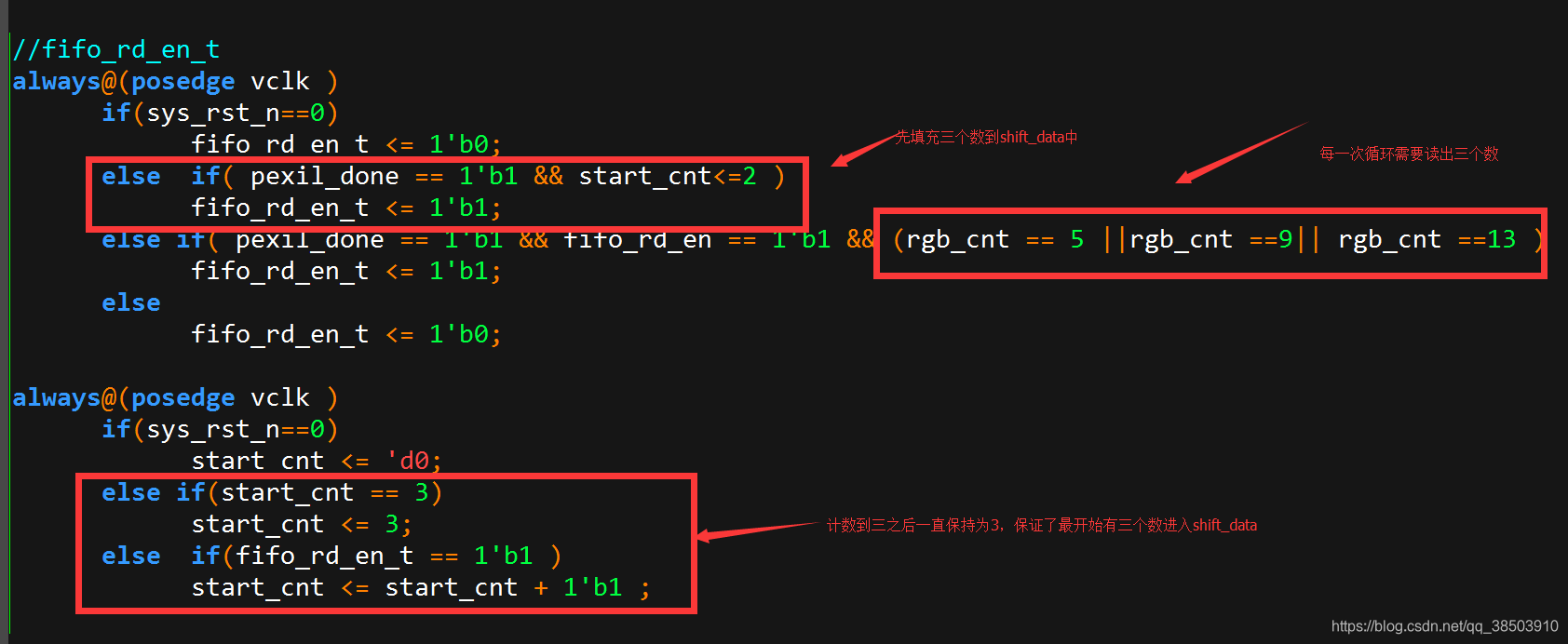
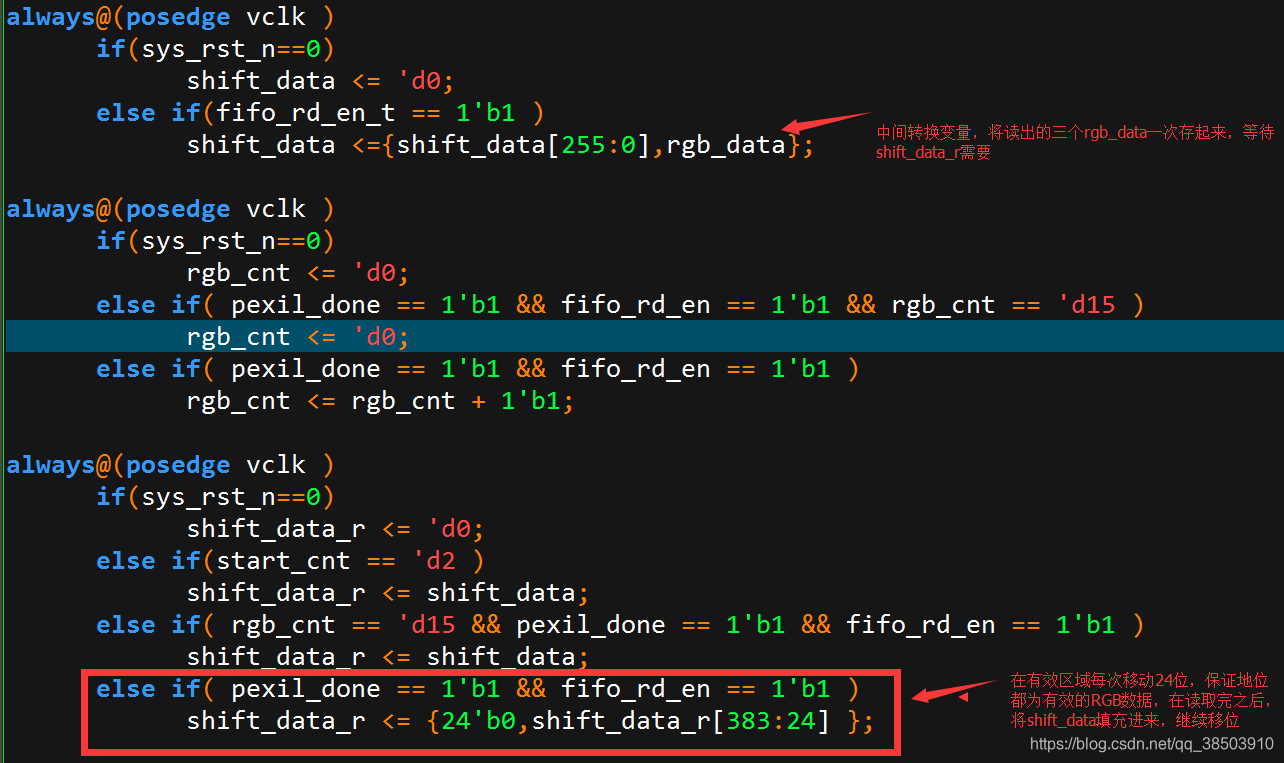
二.内外联合测试仿真,
当完成了内部和外部的读写,就可以用仿真来测试自己的逻辑是否正确,测试模块有多种写法,就写一个最简单的吧,在DD3R复位后,首先在测试模块data_gen中,连续给出8位的数据和同步信号,知道满足一次突写的长度,也就是64*128=8192,而8192/8=1024,0也就是连续需要1024个8位的数据和同步信号,给到外部的user_wr_ctrl之后,而user_wr_ctrl将数据写入到DDR3_Ctrl中的写数据fifo,之后等存储的数据达到了突写的长度,就给出一次命令,就fifo的中的数据存入到DDR3中,之后拉高一次p3口的写使能,测试数据是否会存储到外部user_rd_ctrl中的fifo。由于还没有加上HDMI模块,所以不好断定读模块是否正常,所以可以将先测试写模块。
Data_gen模块波形图:

User_wr_ctrl模块波形图
 insder_wr_ctrl模块波形图:
insder_wr_ctrl模块波形图:

由上波形图可以得出,数据在 User_wr_ctrl处拼接,然后送往内部写数据fifo,存到一定数据量时,就将数据存储到ddr3中,之后完成传出一个wr_end命令,标志这一次突发的写结束,初步达到了预期的效果,如果需要测试读模块是否正确的话,可以等加上HDMI模块之后,联合HDMI模块一起测试。这样的话,DDR3从调用到正常的使用自如,到这步算是初步完成了。
HDMI模块
一.HDMI介绍:
HDMI的全称是“High Definition Multimedia Interface” 高清多媒体接口,是2002年,来自电子行业的七家公司,日立,松下,飞利浦,Silicon Image,索尼,汤姆逊,东芝共同组建了HDMI高清多媒体接口组织HDMI,开始制定一种符合高清时代标准的全新数字化视频、音频接口技术,经过半年多的时间准备工作,HDMI founders在2002年12月9日正式发布了HDMI1.0版标准,标志着HDMI正式进入历史舞台。
DHMI传输原理如下:
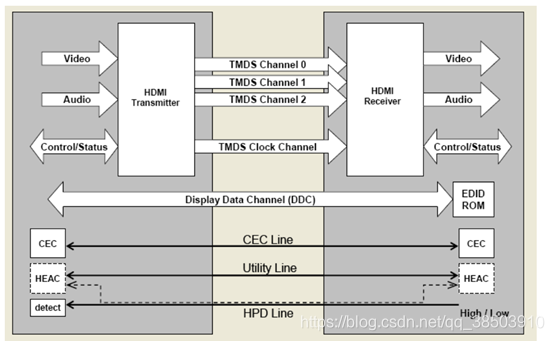
传输的方式是在VGA的基础上演变而来的,将VGA的时序,转化为4路TMDS通道(R,G,B,clk),HDMI使用最小跳变差分信号(TMDS)技术,差分信号上拉电压为+3.3v,端口阻抗为20欧姆,单端信号为400-600mV,标称为500mV,差分信号的逻辑摆幅在800-1200Mv之间,实际差分电压可以再150-1200Mv之间变化,而且偏置电压是由Sink端提供的。
HDMI相对VGA具有以下优点:
- 更好的抗干扰性能,且兼容性更好
- 支持24bit色深处理,且支持音频,
- 一根线缆实现数字音频,视频信号的同步传输,有效降低成本和繁杂程度。
- 支持热插拔技术。
想要利用HDMI进行图像的显示,需要将VGA的时序转化我HDMI的时序,需要经过如下图所示的几个步骤:
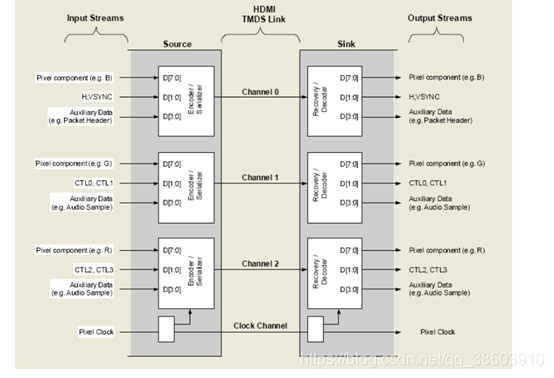
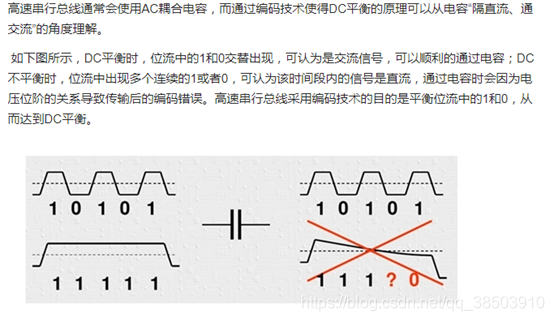
1.8b/10b编码
进行8b/10b编码是为了防止在发送数据的过程中连续出现多个0或者是1,这样的话在这段时间内,数据线的电流可视为直流电压,而直流电流会影响数据的传输,8B10B编码转换的作用就是让DC平衡,使得电路中0和1出现的次数向接近,以达到DC平衡的作用。
在Xilinx的官网上,可以找到8b/10b转换的V文件和相关文档。将其下载下来可以直接使用,我们只需要将其例化进来,然后就能直接使用,就8bit的R,G,B数据转换为10bit的数据。
encode模块接口说明:
| Name | 输入输出 | 备注 |
| clkin | Input | pixel clock input 数据同步时钟 |
| rstin | Input | async. reset input (active high) 异步,高有效 |
| din[7:0] | Input | 8bit数据输入 |
| c0 | Input | Contrl Port 0,控制端口,数据为B时连接VGA的行同步信号 |
| c1 | Input | Contrl Port 0,控制端口,数据为B时连接VGA的场同步信号 |
| de | Input | 数据有效信号 |
| dout[9:0] | output | 输出的10bit数据 |
2.par2ser并转串模块:
HDMI_trans模块中数据的发送是四路单bit串行数据发送,而VGA的数据是是由24bit R,G,B 8bit一组的并行数据,所以在数据发送的过程总需要并行数据转换为串行的数据, 在Vivado中,Xilinx为我们提供OSERDES的原语,作用是将并行数据串行化输出,
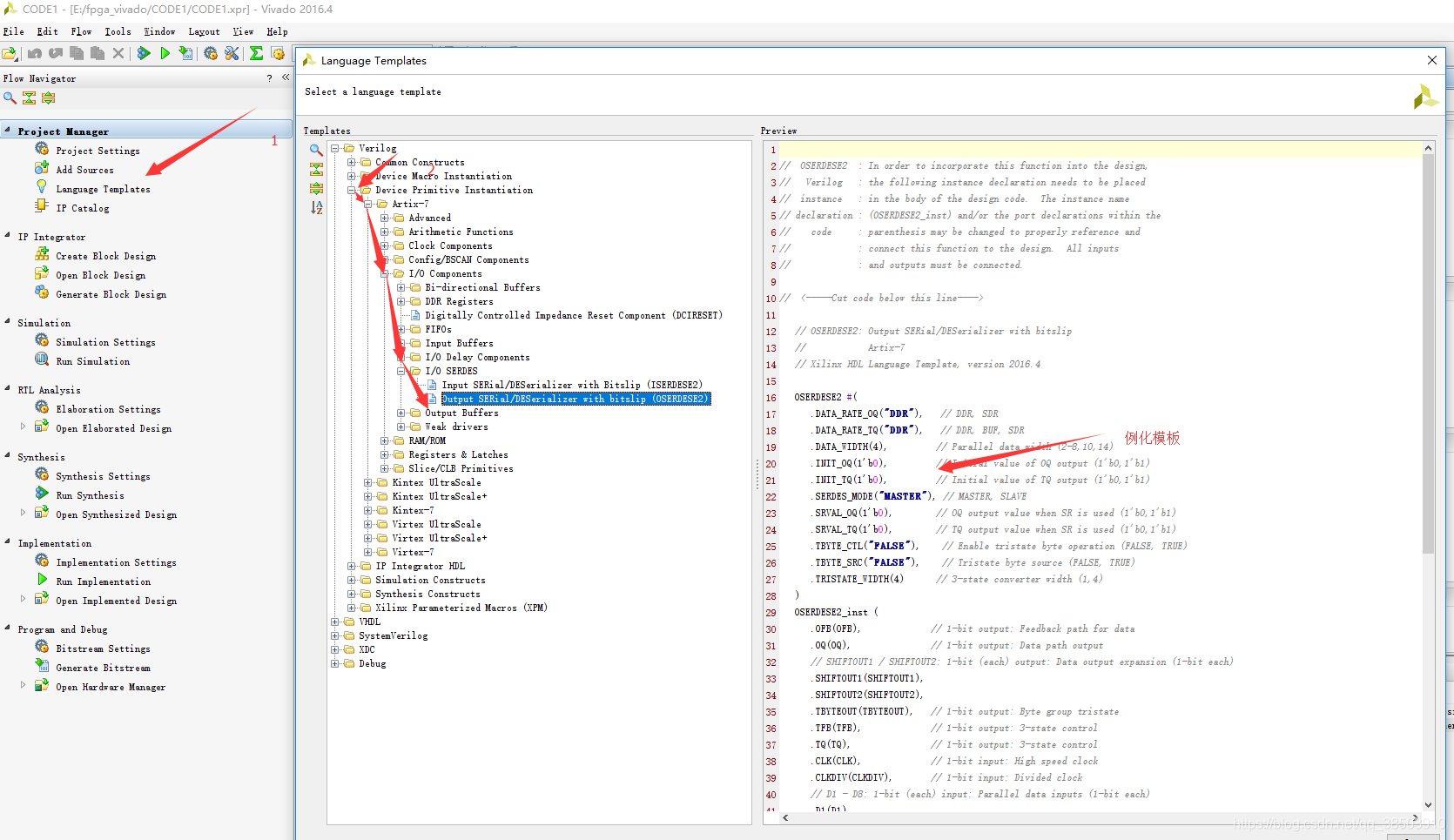
对于原语更多的介绍,必须要查找相关的Datasheet手册才能准确的了解清楚。在Xilinx官方的7_Series FPGAs SelectIO Resources中,给出来OSERDES的具体介绍:
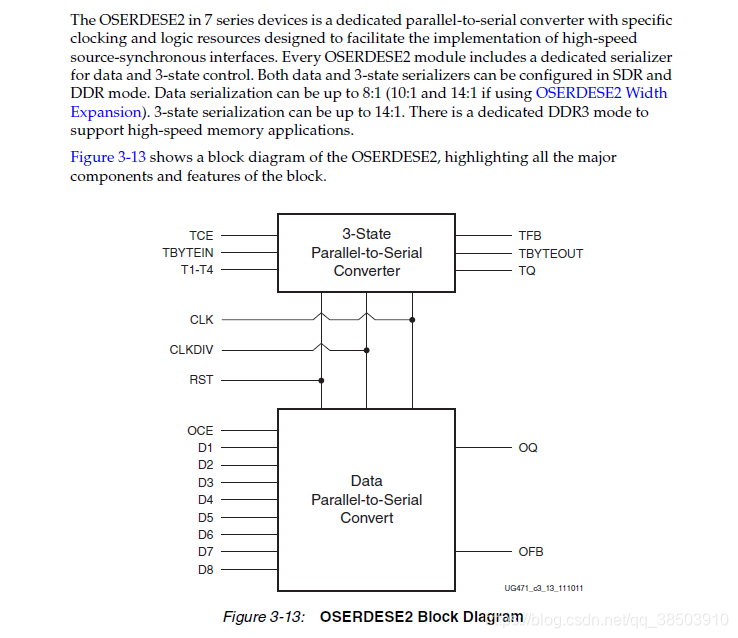
7系列的OSERDES具有支持多种模式和不同速率的并行转串行化输出的原语,同时支持三态门数据和双沿数据的转换,具有普遍性和统一性。在上一个模块这种,R,G,B的8bit数据已经变为10bit的具有DC平衡的数据,在本模块模块中需要使用到OSERDES的扩展模式(支持10bit数据输入),采用双沿模式输出串行数据,假设R,G,B的时钟为65M,如果采用单沿模式输出串行数据,则需要650M的同步时钟,而使用双沿模式,则只需要325M的时钟即可,减少了对时钟的要求,利于我们更好的做进一步的设计。
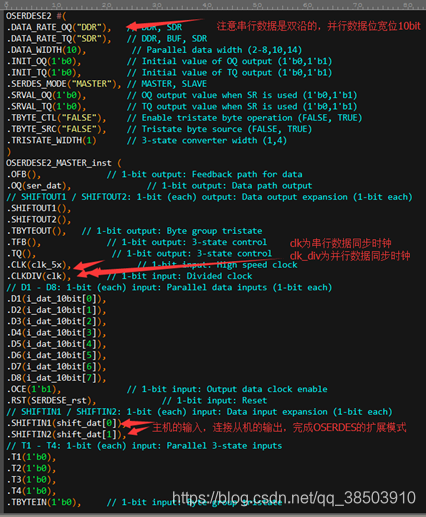
OSERDES原语参数说明:
由于数据为10bit,则需要使用OSERDES的扩展模式,需要将两个OSERDES级联在一起:

扩展模式的OSERDES,具有主机和从机,需要将主机的SHIFTIN1和2分别与从机SHIFTOUT1和2相连,数据的低8bit由主机进入,高两位由从机进入,串行数据的输出从主机的OQ口输出。在OSERDES中,数据的传送如下所示:

输入的并行数据由低到高依次从OQ端输出,如果时串行数据进入到ISERDES,则串行数据先进来的进入到高位。
OSERDES 参数说明:
| Name | 可选项 | 说明 |
| DATA_RATE_OQ | DDR, SDR | 输出串行数据的模式 |
| DATA_RATE_TQ | DDR, BUF, SDR | 三态数据输出模式 |
| DATA_WIDTH | 2-8,10,14 | 并行数据的位宽 |
| INIT_OQ | 1'b0,1'b1 | 初始化是OQ的值 |
| INIT_TQ | 1'b0,1'b1 | 初始化是OQ的值 |
| SERDES_MODE | MASTER, SLAVE | 选择这个OSERDES是主机还是从机 |
| SRVAL_OQ | 1'b0,1'b1 | 复位时第一个寄存器的值 |
| SRVAL_TQ | 1'b0,1'b1 | 传输三态数据时复位时第一个寄存器的值 |
| TBYTE_CTL | FALSE, TRUE | Only for use via the MIG tool. Set to FALSE |
| TBYTE_SRC | FALSE, TRUE | Only for use via the MIG tool. Set to FALSE |
| TRISTATE_WIDTH | 1,4 | 三态数据的位宽 |
OSERDES 接口说明:
| Name | 输入输出 | 说明 |
| OFB | output | 用于联合ISERDES所用 |
| OQ | output | 串行化数据的输出 |
| SHIFTOUT1 | output | 用于扩展模式,从机输出连接主机 |
| SHIFTOUT2 | output | 用于扩展模式,从机输出连接主机 |
| TBYTEOUT | output | Byte group tristate |
| TFB | output | 3-state control |
| TQ | output | 3-state control |
| CLK | Input | High speed clock 高速时钟,串行化数据的同步时钟 |
| CLKDIV | Input | Divided clock 分频时钟, |
| D1 – D8 | Input | 并行数据的输入 |
| OCE | Input | Output data clock enable,输出数据时钟使能 |
| RST | Input | Reset,高有效 |
| SHIFTIN1 | Input | 用于扩展模式,主机接收从机输入 |
| SHIFTIN2 | Input | 用于扩展模式,主机接收从机输入 |
| T1-T4 | Input | 三态数据 |
| TBYTEIN | Input | Byte group tristate |
| TCE | Input | 3-state clock enable |
因为HDMI是四路通道,还需要一路像素时钟来同步R,G,B的数据,为了让时钟尽可能的和串行数据同步化,所以可以让10‘b111110000也经过OSERDES来产生一路随路时钟同步数据,
在最后,由于HDMI端的输出是一对差分信号,差分信号的主要作用是为了抑制抗共模噪声,一对差分对在几乎相同的布局布线上,收到外面噪声的干扰几乎是一直,但因为是差分的,当接收端接收到了差分信号时,可以很好的解决掉噪声的干扰。所以,
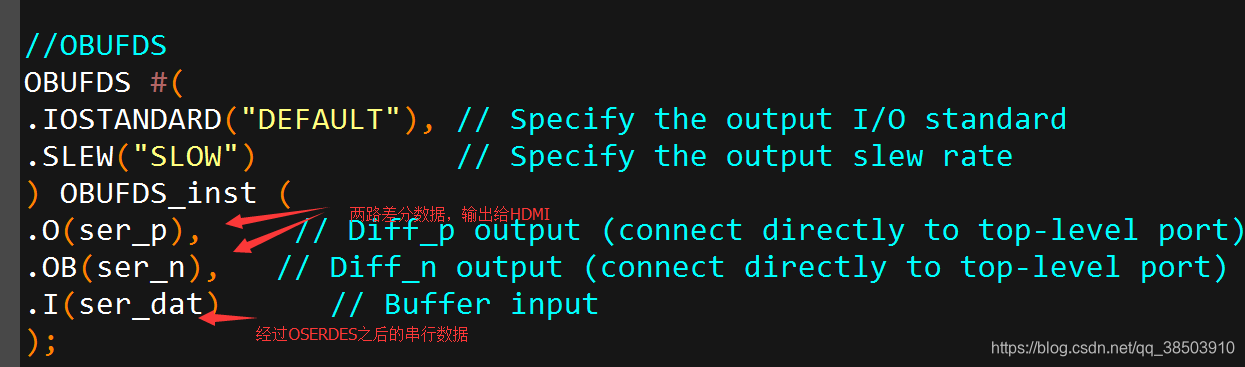
需要给串行化的数据添加一个OBUFDS(单端转差分)的原语
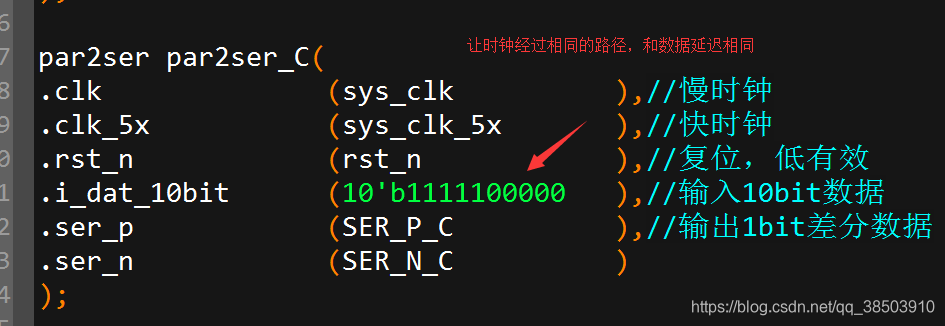
例化之后如下所示:
Par2ser模块接口说明:
| Name | 输入输出 | 说明 |
| clk | input | 慢时钟,10bit数据随路时钟 |
| clk_5x | input | 快时钟,串行化数据随路时钟 |
| rst_n | input | 复位,低有效 |
| i_dat_10bit | input | 输入10bit数据 |
| ser_p | output | 输出1bit差分数据 |
| ser_n | output |
|
至此,HDMI_TRANS的三个模块就完成了,先例化VGA_TIMING模块,将R,G,B像素点的值和行场同步信号传出去,在顶层需要将encode模块例化三次(R,G,B),然后10bit的数据进入par2ser模块转成单端的数据输出,同时不要忘了对时钟也需要经过par2ser模块,注意在顶层需要输出一个HDMI_OUT_En信号,高电平有效,为HDMI的使能。
- Modelsim仿真:
为了能观察的确切,将主时钟的时钟频率调到10M,5倍时钟为50M,这样的话就完
在Modelsim仿真时:出现了一个未知的错误:

好像说是encode模块没有定义时间,功能文件是不可不用定义的呀,只有tb测试文件才需要,在网上询问了一番,找到了解决的办法:对于这个错误,可以通过一个指令来屏蔽掉。具体如下:底层模块没有是`timescale或者timeunit/timepresicion定义,在仿真加载时会出错,而不是像之前版本一样作为告警。
解决:可以使用在vsim指令后加-supress 3009屏蔽该告警。
说的是好像ModelSim的版本不同导致的。
解决完之后,仿真波形如下:

由于RGB 赋值时连续一样,所以差分的串行输出也是一样,但并不影响结果。
HDMI_trans模块算是基本完成了,但是还没有和DDR3挂和关系,如果要和DDR3方面联系在一起,就需要将VGA_TIMNG的R,G,B数据的值,由DDR3模块传送过来,而DDR3的值由串口发送过来的图像数据,这样就完成了DDR3联合HDMI进行图片的显示,这就是我们下一步该做的。
DDR3联合HDMI
在完成了各个模块之后,将DDR3模块和HDMI模块统一在一起,用一个大的顶层串在一起。如下所示:
关于时钟方面:外部晶振过来的时钟为50M,我的方法时50先经PLL分别生成100M,125M和200M时钟DDR3时钟,在用100M的时钟去经过PLL生成65M和325M的HDMI时钟。由于模块有点多参杂在一起,我的想法是先用Modelsim进行一些简单的功能仿真,当Modelsim觉得差不多了,可以下板子试试,如若出错,可以用Modelsim联合ChipSocpe的方法,依靠抓取实际的波形,和仿真波形对比,基本上能解决很多问题。
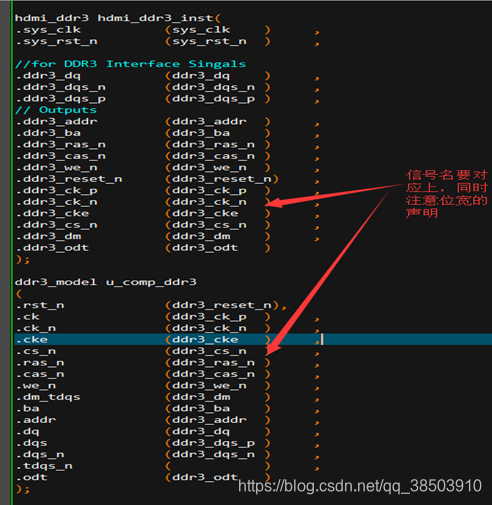
首先是添加XDC文件,先找到之前在DDR3 IP核中绑定过的管脚,其所在位置如下
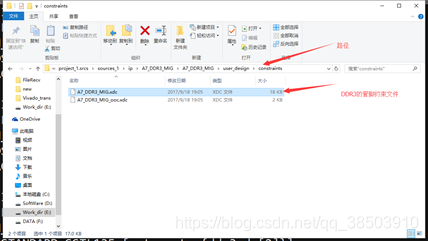
复制一份然后在其基础上添加别的管脚的约束,包括时钟复位,HDMI模块:
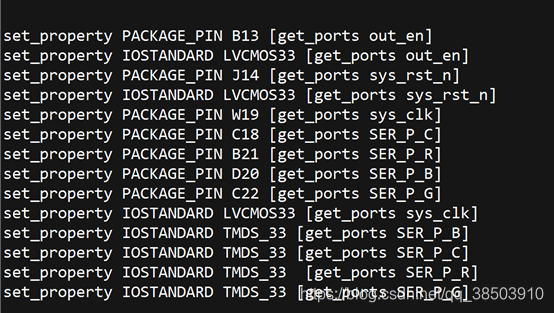
完成后启动ModelSim仿真,观察DDR3 和HDMI之间数据交互的情况:
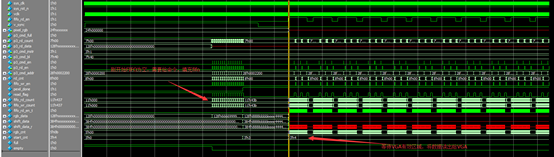
由上波形图可以看出,DDR3刚复位时,,外部的fifo为空,需要向DDR3_ctrl给出命令,读出数据填充,,当等到HDMI显示的第一行有效区域时,将fifo中数据读取走,送给HDMI显示,,当fifo数据小于门限值时,就会继续向DDR3读取数据,以此往复,循环起来,这样的话,HDMI和DDR3的读模块就结合起来了,上面已经完成DDR3的写,这次完成了读,就可以联合串口,发送数据到DDR3,在读取DDR3的数据到HDMI显示,这是本次工程的最终实验结果。
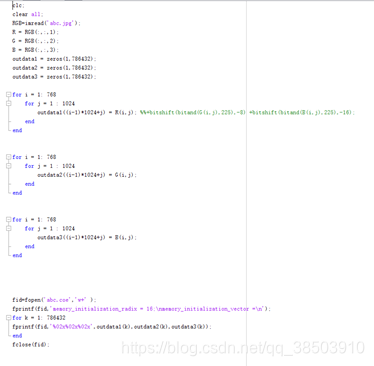
将以前用过的串口可以直接拿过来用,切记将串口参数改一下,波特率改为115200,系统时钟为125M,例化串口并添加相对应的管脚约束后,用matlab将一幅图片转化为24bit的RGB数据,然后将数据通过串口发送到DDR3中
Matlab代码如下:,
在下板子之后,出现了屏幕画面闪动的问题,就像平时在打游戏的时候有掉帧的情况,在Modelsim观察不出问题之后,调取ChipSocpe来抓取工程中的信号,首先观察user_rd_ctrl模块中的pixel_rgb[23:0], fifo_rd_en, fifo_rd_count[10:0], fifo_wr_count[10:0],
触发信号为fifo_rd_en的上升沿,时钟为VGA的65M时钟,
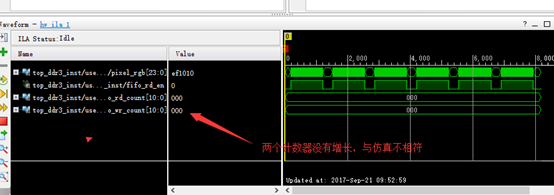
计数器在这个时刻为0,但是RGB却有值,说明计数器曾经到到过门限值,而打开了FIFO的读使能,但是现在却为0,中间肯定出了一些现在还未知的错误,这就需要在抓一下其他的波形来观察。
应当注意的是,当需要观察别的波形时,需要改变chipsocpe所添加的波形时,可以将原来观察的信号截图留下来,一边和之后的波形一起观察。
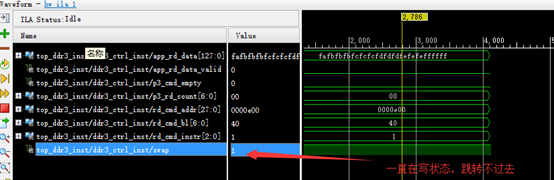
对着波形仔细找了下代码,发现swap是给出写命令或者读命令的条件,结果写反了,这也是自己一时粗心大意而造成的,改过之后,抓取波形图如下:
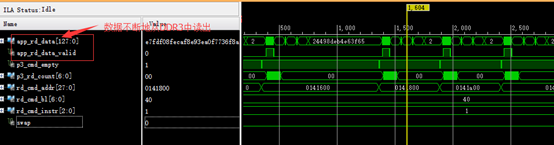
通过串口串口发送一幅(0-255)黑白渐变的图片数据,可以帮组我们更好的找出错误所在:

发送完成之后,在显示器上显示如下:


















 4872
4872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









