







文本向量嵌入表示在自然语言处理领域中具有重要性,其重要性体现在以下几个方面:
-
语义表示:文本向量嵌入能够将文本转换为连续的向量空间表示,从而捕捉词语、短语甚至句子的语义信息。这种表示能够帮助计算机更好地理解和处理自然语言。
-
特征提取:文本向量嵌入可以作为特征提取的基础,用于各种自然语言处理任务,如文本分类、命名实体识别、情感分析等。通过将文本转换为向量表示,可以更好地应用传统的机器学习算法进行处理。
-
相似度计算:基于文本向量嵌入表示,可以计算文本之间的相似度,从而进行信息检索、推荐系统等任务。这种相似度计算对于理解文本之间的关联性非常重要。
-
模型输入:在深度学习模型中,文本向量嵌入通常作为模型的输入,用于训练和推断。合适的文本向量嵌入表示可以直接影响模型的性能和效果。
-
跨模态融合:在多模态任务中,文本向量嵌入可以与其他模态的嵌入进行融合,实现跨模态信息的整合和处理。
MTEB: Massive Text Embedding Benchmark榜单
论文:https://arxiv.org/abs/2210.07316
部分论文内容:
 GitHub:GitHub - embeddings-benchmark/mteb: MTEB: Massive Text Embedding Benchmark
GitHub:GitHub - embeddings-benchmark/mteb: MTEB: Massive Text Embedding Benchmark
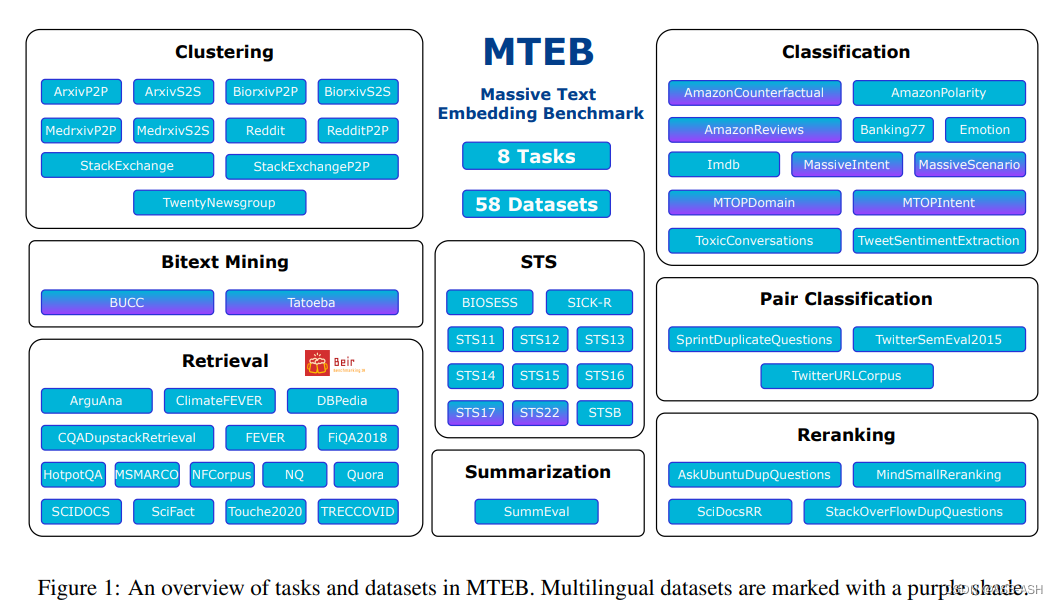
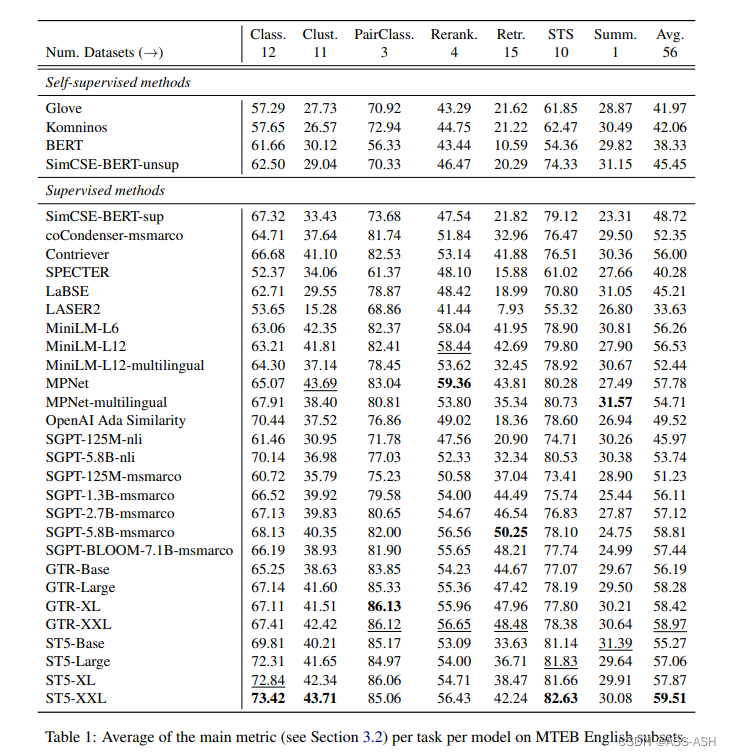
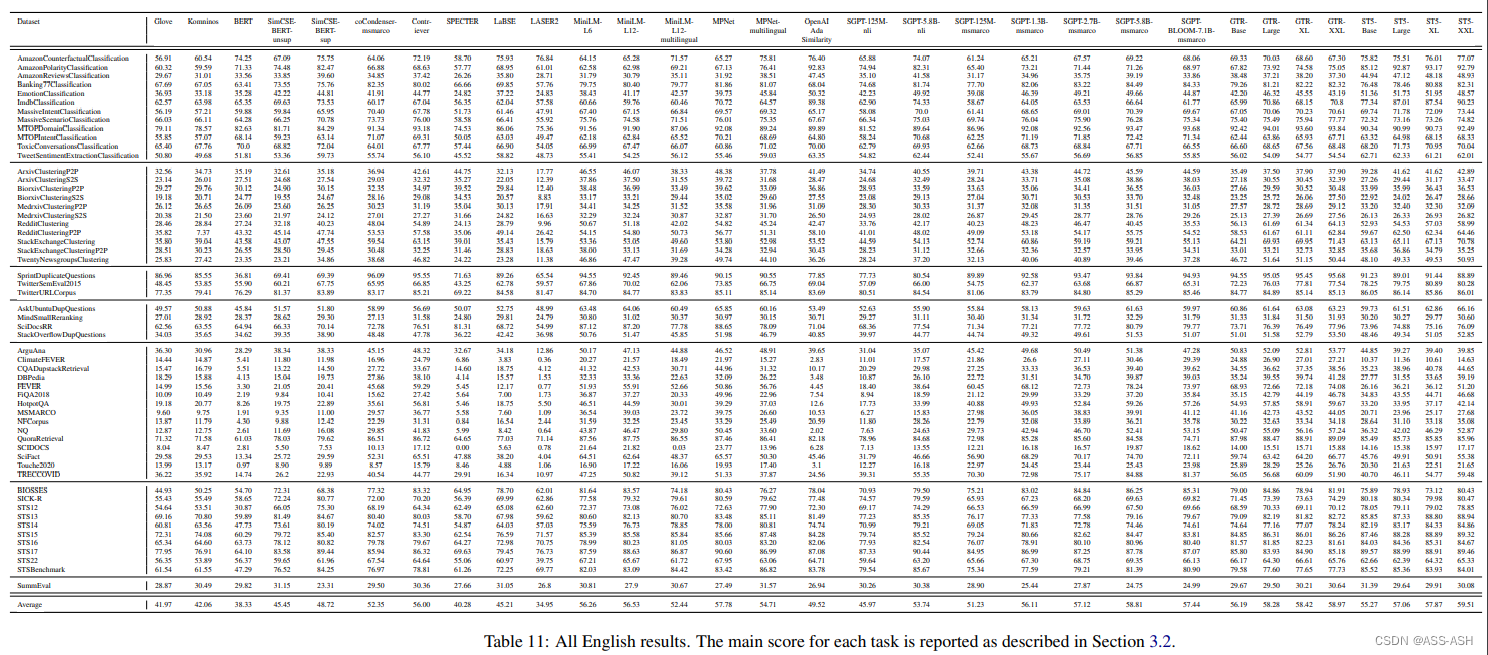
MTEB包含8个语义向量任务,涵盖58个数据集和112种语言。通过在MTEB上对33个模型进行基准测试,建立了迄今为止最全面的文本嵌入基准。其中没有特定的文本嵌入方法在所有任务中都占主导地位。这表明该领域尚未集中在一个通用的文本嵌入方法上,并将其扩展到足以在所有嵌入任务上提供最先进的结果。
也可直接访问huggingface上的榜单,清晰展示了各类任务、各种语言条件下的各种向量表示模型的评估结果:
地址1:https://huggingface.co/spaces/mteb/leaderboard
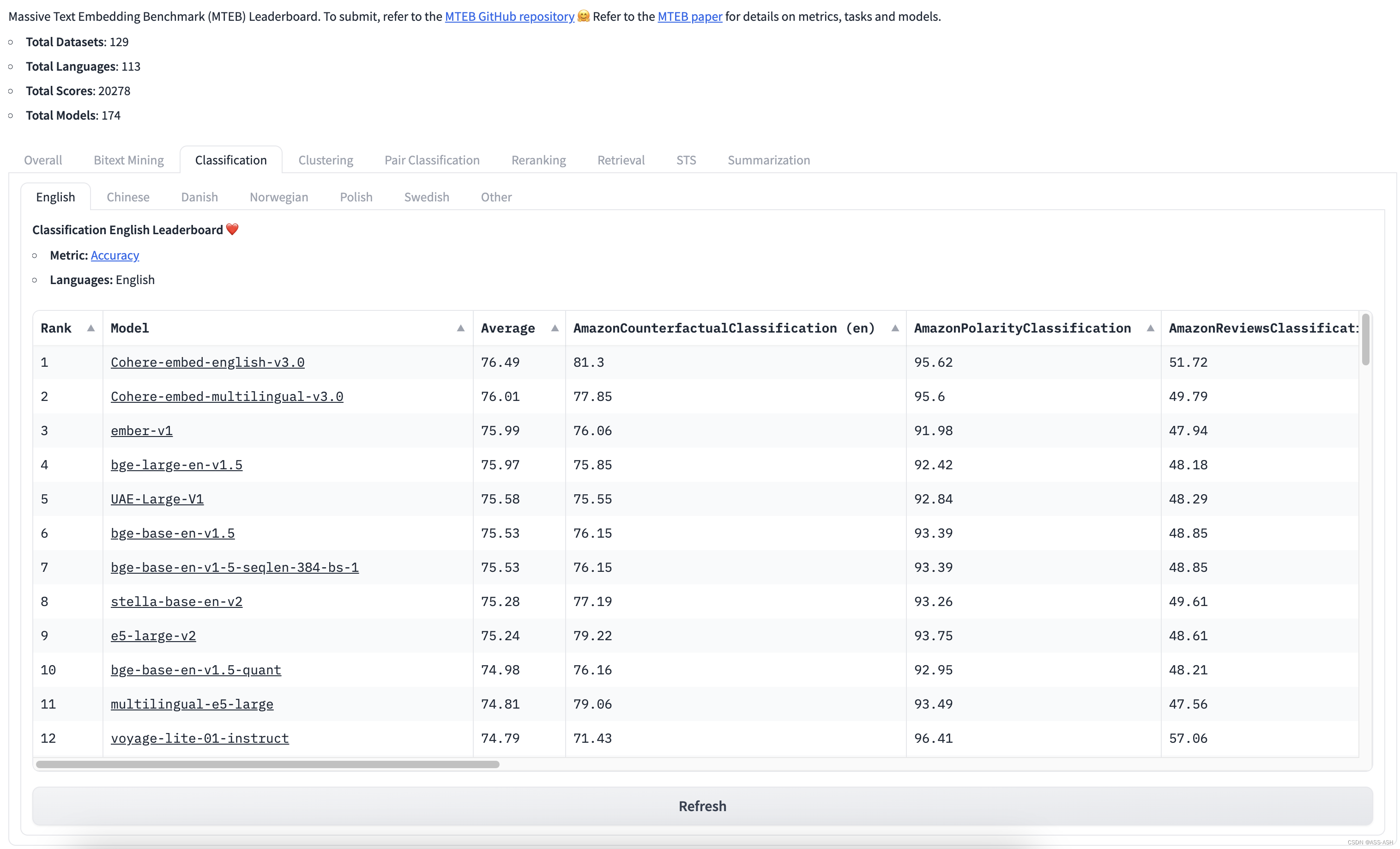
地址2:魔搭社区
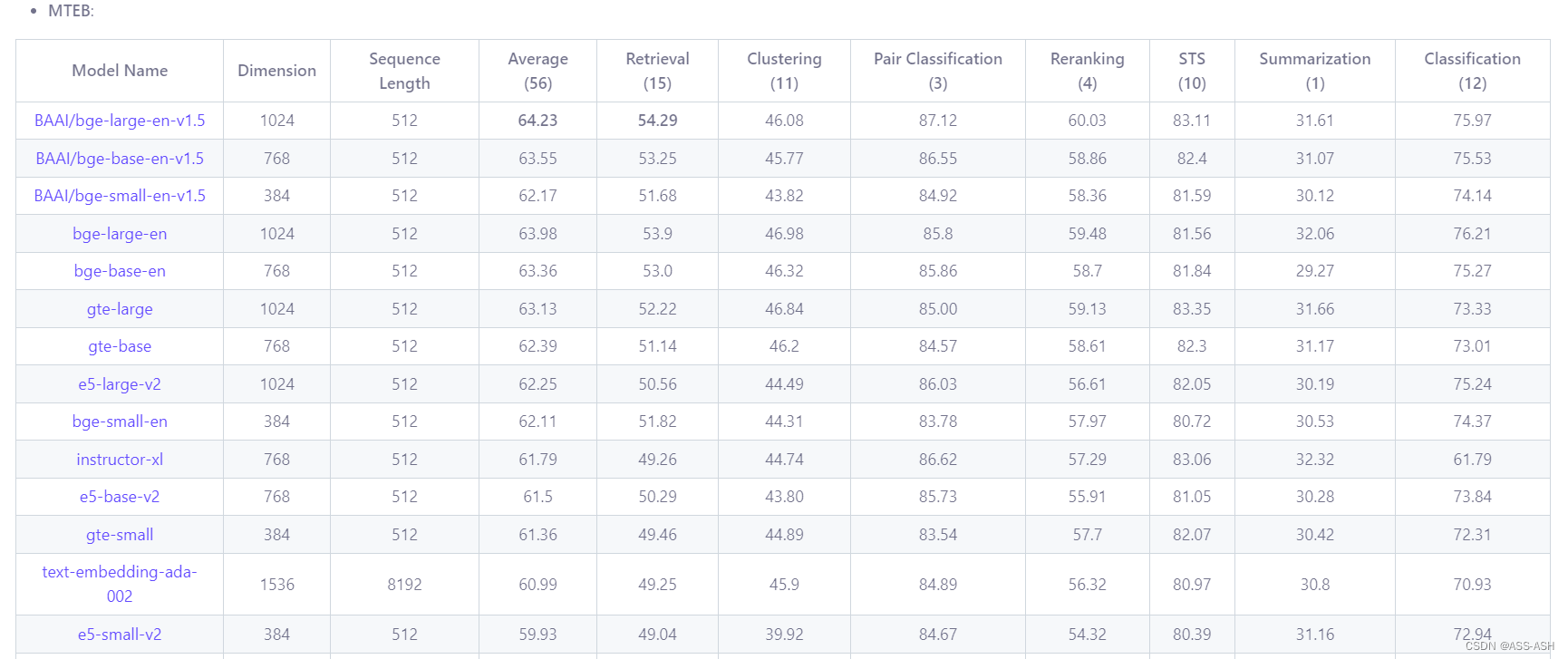
全部:
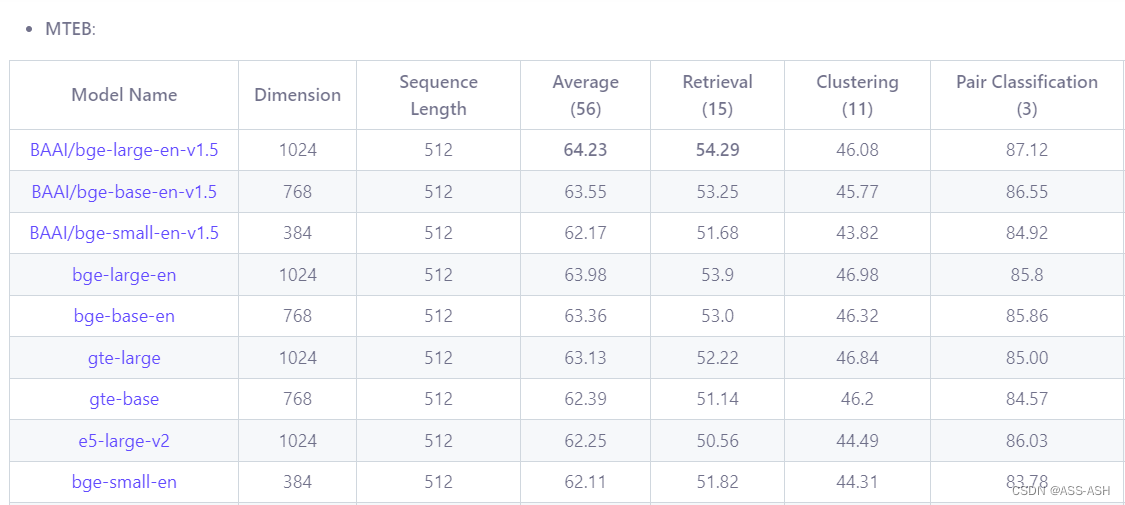
局部:
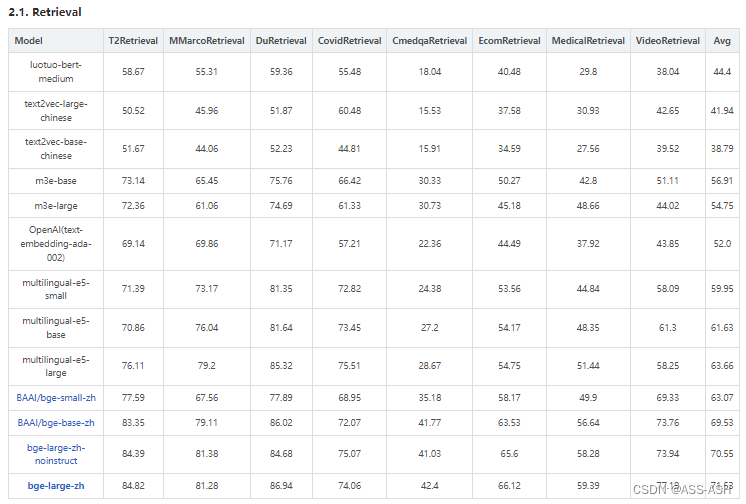
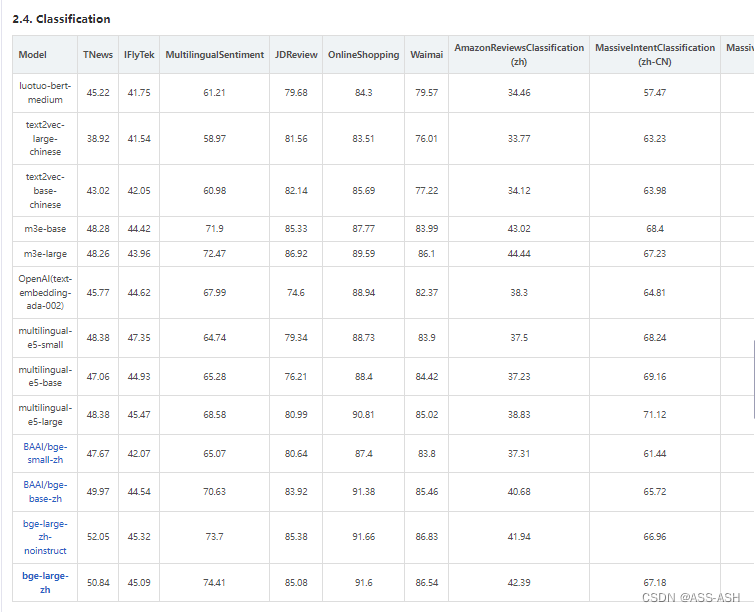
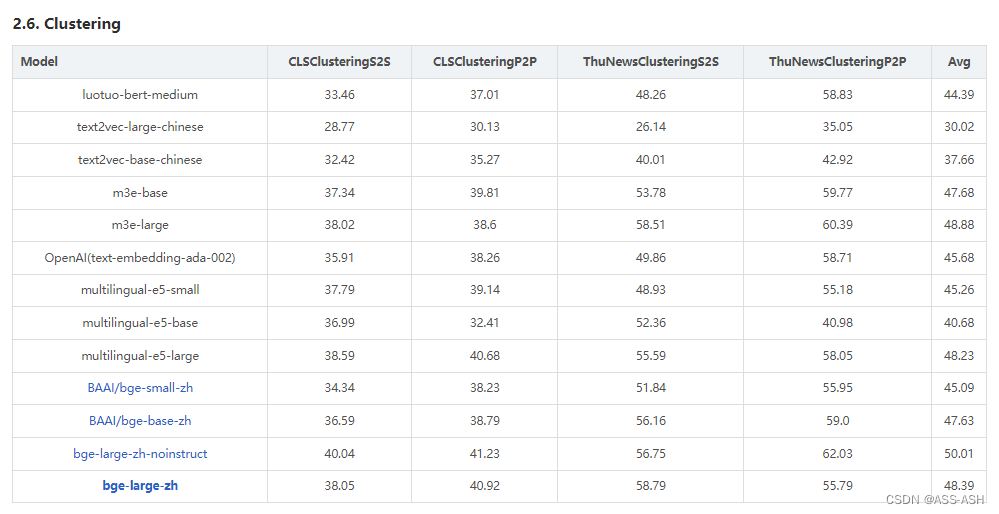
C-MTEB:Chinese Massive Text Embedding Benchmark榜单
目前最新的针对中文文本进行向量表示的榜单,按应用场景进行划分,并且在每个任务下还有一个在不同数据集上的独立榜单。
地址:Chinese Massive Text Embedding Benchmark
总榜单:

分榜单(以检索、分类、聚类任务为例):
模型本地下载
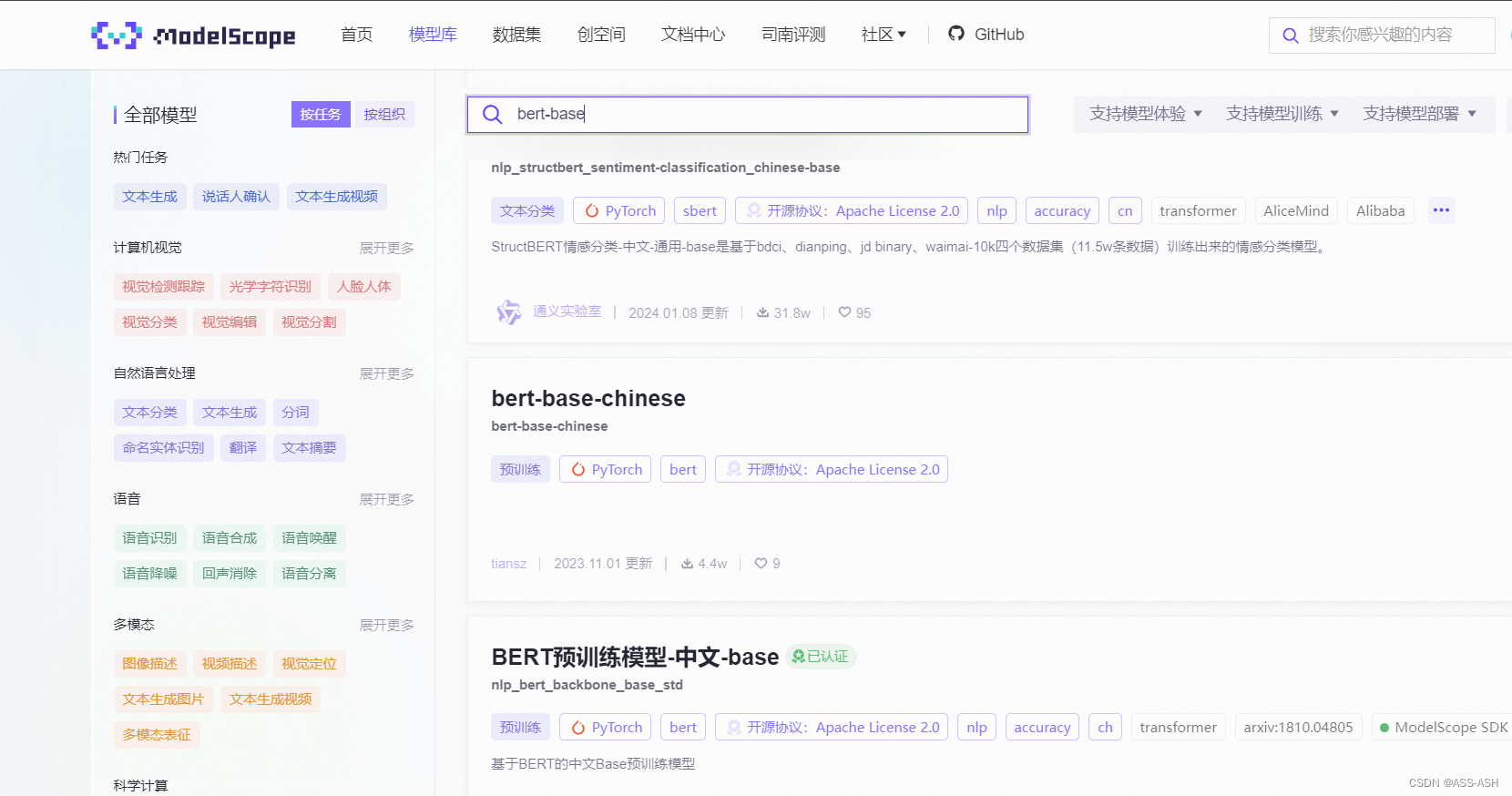
可根据需要在各项目对应地址的榜单中点击链接进行下载,也可以直接访问huggingface官网,在其中搜索模型进行下载,若不方便访问外网或下载速率较慢,也可以在modelscope官网搜索相关模型进行下载。
Huggingface官网:https://huggingface.co/
ModelScope官网:魔搭社区
以下为ModelScope官网下载示例:

















 1930
1930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









