







学习目标:
- An All-in-One Network for Dehazing and Beyond
- 代码看完一部分
个人体会:
本文提出了AOD-Net,这是一种一体化的管道,可以通过端到端的CNN直接重建无雾图像。使用客观(PSNR,SSIM)对去雾效果进行评价。AOD-Net是根据重新制定的大气散射模型设计的,将T和A集成到新的变量中,减少单独计算带来的误差。
知识点:
- 图片评价指标
图像评价指标:PSNR和SSIM
PSNR越高,图像和原图越接近
SSIM一般取值范围:0-1,值越大,质量越好。 - 深度学习损失函数
内容解读:
1. 摘要:
摘要—本文提出了一种使用卷积神经网络 (CNN) 构建的图像去雾模型,称为多合一去雾网络 (AOD-Net)。 它是根据重新制定的大气散射模型设计的。 AOD-Net 不像以前大多数模型那样分别估计传输矩阵和大气光,而是直接通过轻量级 CNN 生成干净的图像。 这种新颖的端到端设计可以很容易地将 AOD-Net 嵌入到其他深度模型中,例如 Faster R-CNN,以提高模糊图像的高级任务性能。 在合成和自然模糊图像数据集上的实验结果表明,我们在 PSNR、SSIM 和主观视觉质量方面的性能优于现有技术。 此外,当将 AOD-Net 与 Faster R-CNN 连接并从头到尾训练联合管道时,我们见证了在模糊图像上的目标检测性能有了很大的提高。
2.主要挑战和瓶颈
1)没有端到端去雾:大多数用于图像恢复和增强的深度学习方法都完全采用了端到端建模:训练模型以直接从损坏的图像中回归干净的图像。示例包括图像去噪 [42]、去模糊 [31] 和超分辨率 [41]。相比之下,到目前为止还没有端到端的深度去雾模型,可以直接从模糊的图像中回归清晰的图像。虽然乍一看这可能看起来很奇怪,但需要意识到雾霾本质上会带来不均匀的信号相关噪声:由雾霾引起的表面的场景衰减与相机表面之间的物理距离相关(即,像素深度)。这与大多数假设与信号无关的噪声的图像退化模型不同,在这种情况下,所有信号都经过相同的参数化退化过程。因此,他们的恢复模型可以很容易地用一个静态映射函数建模。这同样不适用于去雾:退化过程因信号而异,恢复模型也必须是输入自适应的。
现有方法具有相同的信念,即为了从雾霾中恢复干净的场景,估计准确的介质传输图是关键 [1]、[3]、[27]。 通过经验法则单独计算大气光,基于物理模型恢复出清晰图像。 尽管是直观的,但这样的过程并不直接测量或最小化重建失真。 估计传输矩阵和大气光的两个单独步骤中的误差将累积并可能相互放大。 结果,传统的分离流水线导致次优的图像恢复质量。
2)缺少与高级视觉任务的衔接:目前,去雾模型依赖于两组评估标准:(1)对于合成模糊图像,其对应的清晰图像已知,通常计算PSNR和SSIM来测量确保恢复保真度; (2)对于没有清晰图像的真实自然模糊图像,唯一可用的去雾效果比较是主观视觉质量。然而,与图像去噪和超分辨率结果不同,他们视觉伪像的抑制效果是可见的(例如,在纹理和边缘上),现有技术的去雾模型之间的视觉差异[1],[3],[27]通常表现在全球的光照和色调中,并且通常太微妙而无法分辨。
一般图像恢复和增强,被称为低级视觉任务的一部分,通常被认为是中级和高级视觉任务的预处理步骤。众所周知,诸如物体检测和识别之类的高级计算机视觉任务的性能将在存在各种劣化的情况下恶化,并且然后在很大程度上受到图像恢复和增强的质量的影响。然而,根据我们的最佳知识,没有探索将去雾算法和结果与高级视觉任务性能相关联
3.主要贡献
在本文中,我们提出了一体化除雾网络(AOD-Net),这是一种基于CNN的除雾模型,具有两个关键创新,以应对上述两个挑战:
(1)我们是第一个提出端到端可训练的去雾模型,它直接从模糊图像中生成干净的图像,而不是依赖于任何单独的和中间的参数估计步骤。 AOD-Net是基于重新配制的大气散射模型设计的,因此保留了与现有工作相同的物理基础[3],[27]。然而,它建立在我们不同的信念之上,即物理模型可以以“更端对端”的方式制定,其所有参数在一个统一模型中估算。
(2)我们是第一个定量研究去雾质量如何影响随后的高级视力任务的人,这项任务是比较去雾效果的新客观标准。此外,AOD-Net可以与其他深层模型无缝嵌入,构成一个管道,在模糊图像上执行高级任务,具有隐式的去雾过程。由于我们独特的一体化设计,这种管道可以从头到尾联合调整,以进一步提高性能,如果用其他深度去雾方法替代AOD-Net是不可行的[3],[27]。
AOD-Net在合成模糊图像上进行训练,并在合成和真实自然图像上进行测试。实验证明了AOD-Net优于几种最先进的方法,不仅包括PSNR和SSIM(见图1),还包括视觉质量(见图2)。作为轻量级和高效率的型号,AOD-Net的耗费时间低至0.026秒,可以使用单个GPU处理一个480×640图像。当与更快的R-CNN [26]连接时,AOD-Net在改善模糊图像的物体检测性能方面明显优于其他去雾模型,当我们共同调整AOD-Net和fasterrcnn的流水线时,性能得到进一步提升。
本文从以前的会议版本[14]扩展而来。本文最引人注目的改进在于第四部分,我们对评估和增强物体检测的去雾进行了深入的讨论,并介绍了联合训练部分的细节和分析。我们还对AOD-Net的架构进行了更详细和全面的分析(例如第III-D节)。此外,我们还包括更广泛的比较结果。
4.AOD-NET: THE ALL-IN-ONE DEHAZING MODEL
在本节中,将解释所提出的 AOD-Net。 我们首先介绍了变换后的大气散射模型,在此基础上设计了 AOD-Net。 然后详细描述 AOD-Net 的架构。
4.1物理模型和转换公式

现存的诸如[27],[3]之类的工作遵循相同的三步程序:
1)使用复杂的深模型从模糊图像I(x)估计传输矩阵t(x);
2)使用一些经验方法估计A;
3)通过(3)估计清洁图像J(x)。
这样的过程导致次优解决方案,其不直接最小化图像重建误差。当将它们组合在一起以计算(3)时,t(x)和A的单独估计将导致累积或甚至放大的误差。
我们的核心思想是将两个参数t(x)和A统一为一个公式,即(4)中的K(x),并直接最小化像素域重建误差。为此,将(3)中的公式重新表示为下面的转换公式:
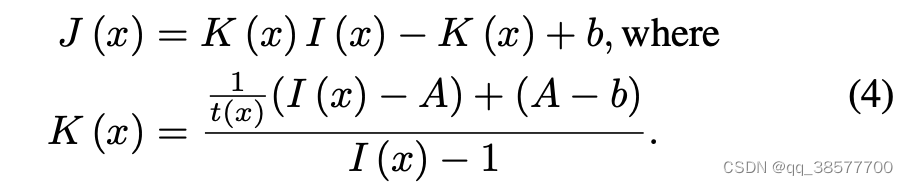

4.2网络设计
提出的aod-net包含两个模块:
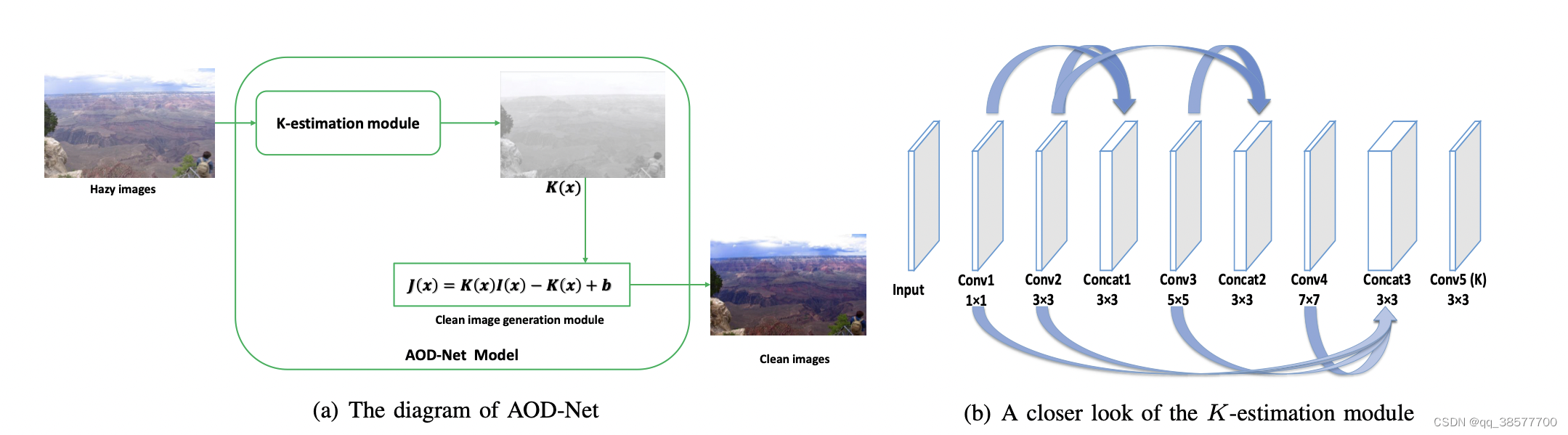
(a)k-estimation模块:从输入图像I(x)估计k(x)
(b)清晰图像生成模型:k(x)再去估计J(x)

5.实验结果
5.1 数据集和实现
创建合成数据集:NYU2深度数据集,大气光值[0.6,1.0],bita {0.4,0.6,0.8,1.0,1.2,1.4,1.6},取出27256个图像做训练集,3170个做测试集A,Middlebury立体数据集中取出800张full-size合成图像作为测试集B,此外,在自然雾霾图像上也评估了模型的泛化能力。
在训练过程中,使用高斯随机变量初始化权重。 我们使用ReLU神经元,因为我们发现它比[3]中提出的BReLU神经元在我们的特定环境中更有效。 动量和衰减参数分别设置为0.9和0.0001。 我们使用8个图像(480×640)的批量大小,学习率为0.001。 我们采用简单的均方误差(MSE)损失函数,并且很高兴地发现它不仅提升了PSNR,还提升了SSIM以及视觉质量。AOD-Net模型需要大约10个训练时期才能收敛,并且通常在10个时期之后表现得足够好。 在本文中,我们已经训练了40个时期的模型。 还发现将范数约束在[-0.1,0.1]内对clip the gradient (防止梯度爆炸)很有帮助。 该技术在稳定复发网络训练方面很受欢迎[25]。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









