







🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【机器学习案例-20】飞机航班延误的分类预测:基于 CatBoost 的完整实战
一、项目背景与目标
在航空运输中,航班延误是一个普遍且影响深远的问题。它不仅影响乘客的出行体验,还对航空公司的声誉和运营成本造成负面影响。因此,准确预测航班延误对于航空公司和机场的运营优化至关重要。本文将使用 CatBoost 算法,结合五折交叉验证,构建一个航班延误分类预测模型,并通过详细的代码实现和分析,帮助大家理解和应用这一技术。
航班延误可能由多种因素引起,包括天气、机械故障、空中交通管制等。通过机器学习技术,我们可以提前预测航班延误,帮助航空公司和机场提前采取措施,减少延误对乘客和运营的影响。
本文的目标是:
- 使用 CatBoost 算法构建航班延误分类预测模型。
- 通过五折交叉验证提高模型的稳定性和泛化能力。
- 提供详细的代码实现和分析,帮助大家理解和应用这一技术。
二、数据集介绍
539383 个实例和 8 个不同的特征。目的是在给定预定起飞信息的情况下预测给定航班是否会延误。
我们使用的数据集包含以下特征:
- Airline:航空公司
- Flight:航班号
- AirportFrom:起飞机场
- AirportTo:到达机场
- DayOfWeek:星期几
- Time:起飞时间
- Length:飞行时长
- Delay:是否延误(目标变量)
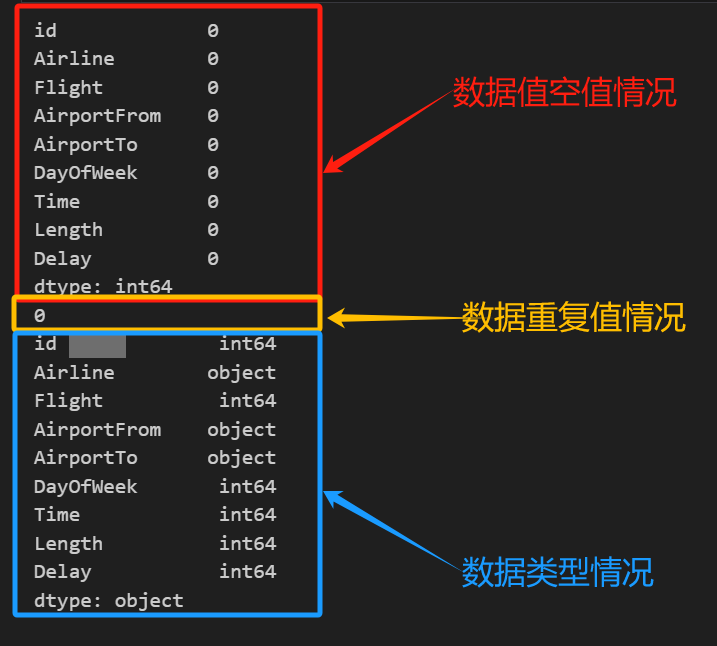
数据集中无缺失值和重复值,因此无需进行额外的预处理。
三、完整代码实现
1. 导入第三方包
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style('darkgrid')
import warnings
warnings.filterwarnings('ignore')
import catboost as cb
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
2. 数据读取及预处理
# 读取数据
data = pd.read_csv('/home/mw/input/airlines2640/Airlines.csv')
# 查看数据缺失情况
print(data.isna().sum())
# 查看数据重复情况
print(data.duplicated().sum())
# 查看数据类型
print(data.dtypes)
# 删除无关变量 "id"
data.drop('id', axis=1, inplace=True)
3. 数据分布详情
# 绘制延误分布图
sns.catplot(x="Delay", kind="count", data=data)
plt.show()
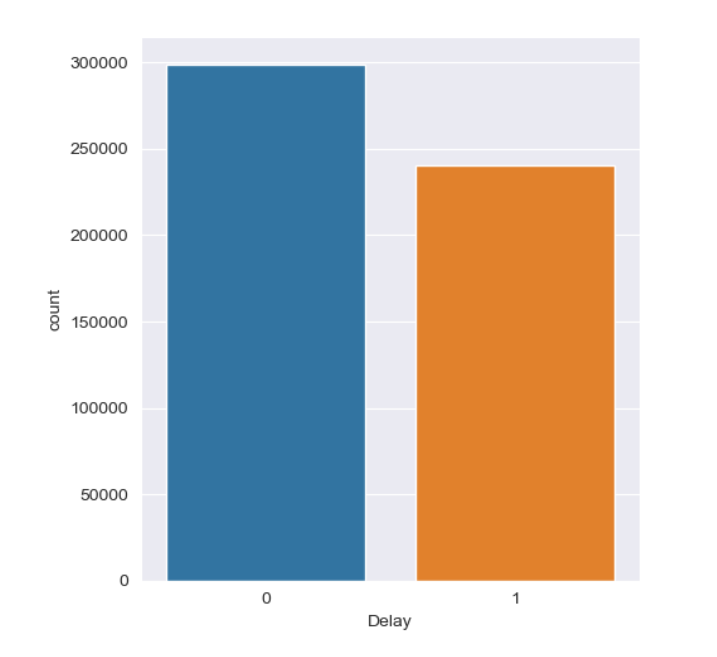
从图中可以看出,数据中航班是否延误的数量比接近 1:1,因此无需进行过采样或欠采样的处理。
4. 模型构建及预测
4.1 单一训练
# 筛选类别特征
cate_cols = [x for x in data.columns if data[x].dtype not in [np.float32, np.float64] and x != 'Delay']
for col in cate_cols:
data[col] = pd.Categorical(data[col])
# 划分数据集
X = data.iloc[:, :-1] # 特征列
y = data.iloc[:, -1] # 目标列
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2022, test_size=0.2)
X_test1, X_val, y_test1, y_val = train_test_split(X_test, y_test, test_size=0.5, random_state=2022)
# 获取类别特征索引
cate_cols_indexs = np.where(X_train.columns.isin(cate_cols))[0]
# 配置训练参数
clf = cb.CatBoostClassifier(
iterations=500,
depth=8,
boosting_type='Ordered',
learning_rate=0.1,
loss_function='Logloss',
bagging_temperature=0.85,
od_type='Iter',
rsm=0.85,
od_wait=100,
l2_leaf_reg=3,
thread_count=8,
use_best_model=True,
random_seed=2022
)
# 自定义模型评估函数
def model_evaluation(pre, y_test):
print('{:-^16}'.format('准确率'))
print(accuracy_score(pre, y_test))
print('{:-^16}'.format('召回率'))
print(recall_score(pre, y_test))
print('{:-^16}'.format('精确率'))
print(precision_score(pre, y_test))
print('{:-^18}'.format('F1-score'))
print(f1_score(pre, y_test))
# 训练模型
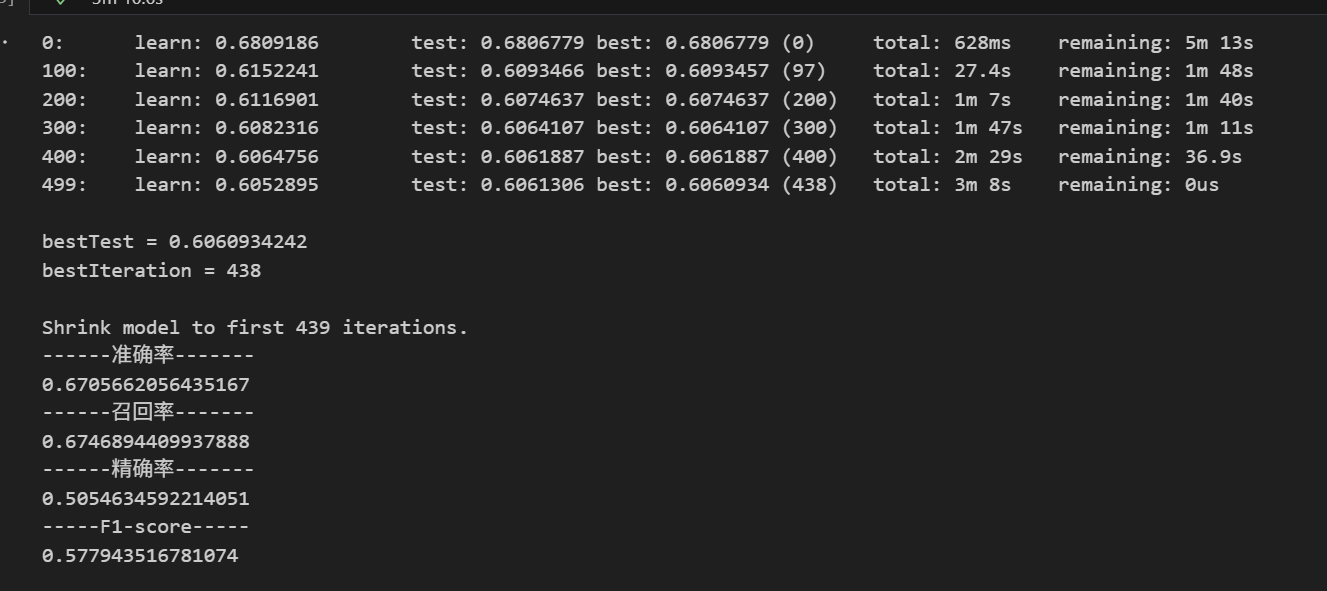
clf.fit(X_train.values.tolist(),
y_train.values.tolist(),
cat_features=cate_cols_indexs,
verbose_eval=100,
early_stopping_rounds=100,
eval_set=(X_val.values.tolist(), y_val.values.tolist()))
# 预测
pre = clf.predict(X_test1.values.tolist())
model_evaluation(pre, y_test1)
4.2 五折交叉验证
# 创建五折交叉验证
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=2022)
prob_oof = np.zeros(X_train.shape[0]) # 用于储存验证集预测结果
test_pred_prob = np.zeros(X_test.shape[0]) # 用于储存测试集预测结果
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold {}".format(fold_ + 1))
xdata_trn, ydata_trn = X_train.iloc[trn_idx].values.tolist(), y_train.iloc[trn_idx].values.tolist()
xdata_val, ydata_val = X_train.iloc[val_idx].values.tolist(), y_train.iloc[val_idx].values.tolist()
cate_cols_indexs = np.where(X_train.columns.isin(cate_cols))[0]
clf.fit(xdata_trn,
ydata_trn,
cat_features=cate_cols_indexs,
verbose_eval=100,
early_stopping_rounds=500,
eval_set=(xdata_val, ydata_val))
prob_oof[val_idx] = clf.predict(xdata_val)
test_pred_prob += clf.predict(X_test.values.tolist()) / folds.n_splits
# 评估模型
model_evaluation(test_pred_prob.astype(int), y_test)
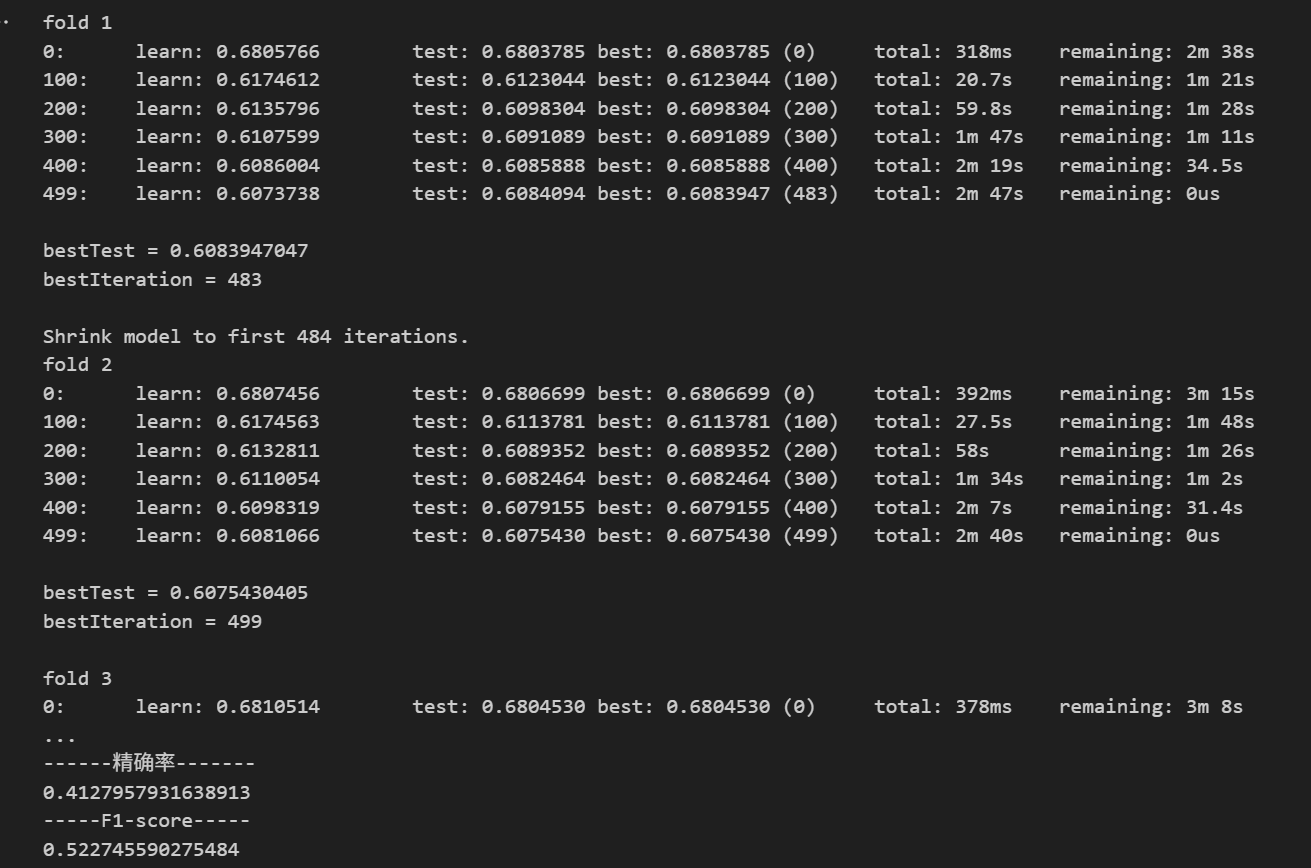
四、结果分析与优化建议
1 结果分析
通过单一验证的模型预测准确率为 67.67%,而结合五折交叉验证后,模型的准确率略有下降,但整体性能更加稳定。以下是模型的评估指标:
| 指标 | 单一验证 | 五折交叉验证 |
|---|---|---|
| 准确率 | 67.06% | 66.52% |
| 召回率 | 67.47% | 71.25% |
| 精确率 | 50.55% | 41.28% |
| F1-score | 57.79% | 52.27% |
2 优化建议
- 超参数调优:通过网格搜索或贝叶斯优化进一步调整模型的超参数。
- 特征工程:尝试添加更多相关特征,如天气数据、历史延误记录等。
- 模型融合:结合其他机器学习算法(如 XGBoost、LightGBM)进行模型融合,提高预测性能。
五、总结
通过本文的实战指南,我们成功构建了一个基于 CatBoost 的航班延误分类预测模型,并通过五折交叉验证提高了模型的稳定性和泛化能力。尽管模型的准确率还有提升空间,但通过超参数调优和特征工程等方法,我们可以进一步优化模型性能。
六、完整代码
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style('darkgrid')
import warnings
warnings.filterwarnings('ignore')
import catboost as cb
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 读取数据
data = pd.read_csv('/home/mw/input/airlines2640/Airlines.csv')
# 查看数据缺失情况
print(data.isna().sum())
# 查看数据重复情况
print(data.duplicated().sum())
# 查看数据类型
print(data.dtypes)
# 删除无关变量 "id"
data.drop('id', axis=1, inplace=True)
# 绘制延误分布图
sns.catplot(x="Delay", kind="count", data=data)
plt.show()
# 筛选类别特征
cate_cols = [x for x in data.columns if data[x].dtype not in [np.float32, np.float64] and x != 'Delay']
for col in cate_cols:
data[col] = pd.Categorical(data[col])
# 划分数据集
X = data.iloc[:, :-1] # 特征列
y = data.iloc[:, -1] # 目标列
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2022, test_size=0.2)
X_test1, X_val, y_test1, y_val = train_test_split(X_test, y_test, test_size=0.5, random_state=2022)
# 获取类别特征索引
cate_cols_indexs = np.where(X_train.columns.isin(cate_cols))[0]
# 配置训练参数
clf = cb.CatBoostClassifier(
iterations=500,
depth=8,
boosting_type='Ordered',
learning_rate=0.1,
loss_function='Logloss',
bagging_temperature=0.85,
od_type='Iter',
rsm=0.85,
od_wait=100,
l2_leaf_reg=3,
thread_count=8,
use_best_model=True,
random_seed=2022
)
# 自定义模型评估函数
def model_evaluation(pre, y_test):
print('{:-^16}'.format('准确率'))
print(accuracy_score(pre, y_test))
print('{:-^16}'.format('召回率'))
print(recall_score(pre, y_test))
print('{:-^16}'.format('精确率'))
print(precision_score(pre, y_test))
print('{:-^18}'.format('F1-score'))
print(f1_score(pre, y_test))
# 训练模型
clf.fit(X_train.values.tolist(),
y_train.values.tolist(),
cat_features=cate_cols_indexs,
verbose_eval=100,
early_stopping_rounds=100,
eval_set=(X_val.values.tolist(), y_val.values.tolist()))
# 预测
pre = clf.predict(X_test1.values.tolist())
model_evaluation(pre, y_test1)
# 创建五折交叉验证
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=2022)
prob_oof = np.zeros(X_train.shape[0]) # 用于储存验证集预测结果
test_pred_prob = np.zeros(X_test.shape[0]) # 用于储存测试集预测结果
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold {}".format(fold_ + 1))
xdata_trn, ydata_trn = X_train.iloc[trn_idx].values.tolist(), y_train.iloc[trn_idx].values.tolist()
xdata_val, ydata_val = X_train.iloc[val_idx].values.tolist(), y_train.iloc[val_idx].values.tolist()
cate_cols_indexs = np.where(X_train.columns.isin(cate_cols))[0]
clf.fit(xdata_trn,
ydata_trn,
cat_features=cate_cols_indexs,
verbose_eval=100,
early_stopping_rounds=500,
eval_set=(xdata_val, ydata_val))
prob_oof[val_idx] = clf.predict(xdata_val)
test_pred_prob += clf.predict(X_test.values.tolist()) / folds.n_splits
# 评估模型
model_evaluation(test_pred_prob.astype(int), y_test)



















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











