






2025年最新UAV-DETR论文|无人机图像高效端到端物体检测
UAV-DETR论文|无人机图像高效端到端物体检测
文章末尾部分 包含 YOLO11、YOLOv8、YOLOv10、RT-DETR、YOLOv7、YOLOv5 等模型 结合+ UAV-DETR无人机图像高效端到端物体检测 原创改进核心内容
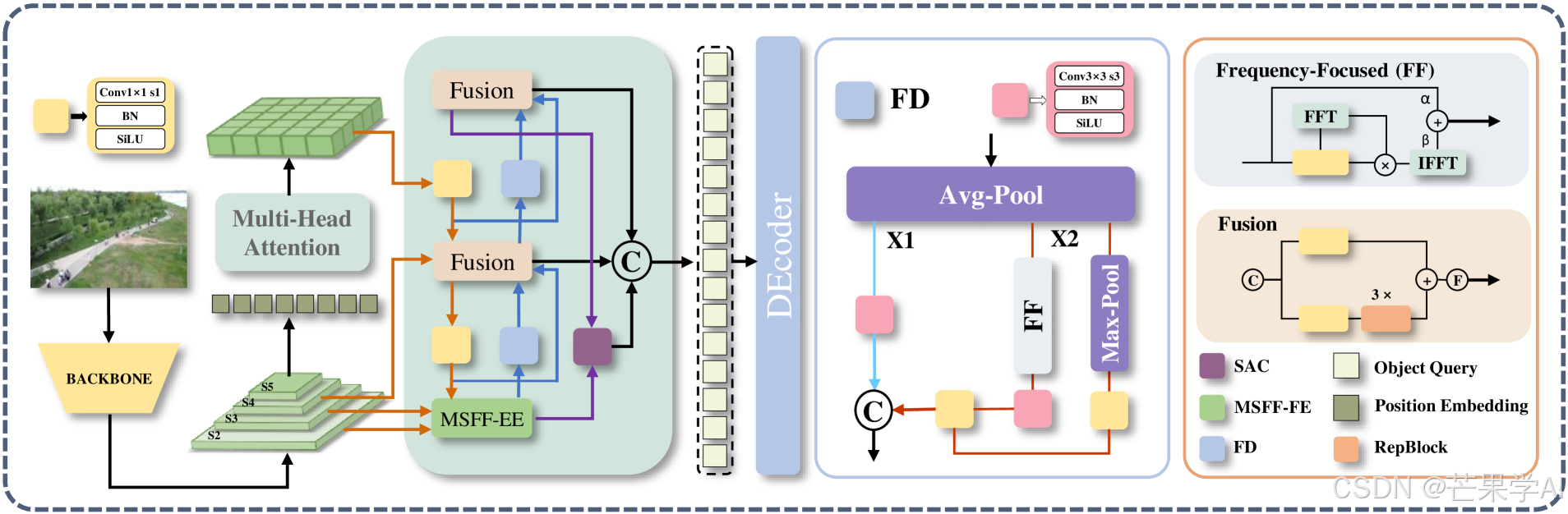
本文设计了 UAV-DETR,这是一种专为无人机图像设计的实时端到端目标检测器。通过引入 MSFF-FE 模块、FD 模块和 SAC 模块,UAV-DETR 缓解了航拍图像中检测小目标和遮挡目标的困难。
论文信息:Efficient End-to-End Object Detection for Unmanned Aerial Vehicle Imagery
论文链接:https://arxiv.org/abs/2501.01855
在 VisDrone 和 UAVVaste 数据集上的实验结果表明,该方法在保持实时推理速度的同时,比现有相似计算成本的方法精度更高。未来将致力于提高其对噪声的鲁棒性,进一步完善模型性能。
1. UAV-DETR 论文理论部分解析
UAV-DETR: Efficient End-to-End Object Detection for Unmanned Aerial Vehicle Imagery核心内容总结

一、研究背景
(一)无人机目标检测的应用与挑战
配备摄像头的无人机(UAV)在众多领域得到广泛应用,无人机目标检测(UAV-OD)作为其中的核心技术备受关注。然而,现有的UAV-OD算法大多依赖手动设计的组件,像非极大值抑制(NMS)和基于人为经验生成的锚框,这些组件在不同任务中需要大量调优,在实际应用中既复杂又低效。
(二)端到端模型的现状与问题
端到端模型虽能避免手动设计组件的问题,但当前流行的端到端模型如检测变压器(DETR)及其改进版本,主要是针对自然图像设计的。在处理无人机图像时存在不足,因为无人机视觉中的目标特征比普通视觉更复杂,航拍图像面临小目标尺寸、遮挡等挑战,现有DETR模型计算成本高、实时性能差,不适合无人机图像分析的实时场景。
二、相关工作
(一)无人机图像中的目标检测
无人机图像目标检测在检测小目标和处理遮挡方面存在独特挑战,且常需部署在硬件平台上,要平衡实时性能和计算复杂度。现有研究方法包括粗到精处理流水线,这类两阶段方法精度高但计算开销大,不适合资源受限环境;还有优化的单阶段模型,旨在平衡检测精度和效率;此外,许多工作致力于捕获更多与检测小目标相关的特征,大多聚焦于利用更高分辨率的特征图,部分方法还利用上下文信息来增强小目标检测。但总体上,对后处理技术研究有限,且这些方法主要在空间域提取详细特征和上下文信息,频域信息利用不足。
(二)实时端到端目标检测
许多单阶段UAV-OD模型基于YOLO系列模型,因其性能和实时能力较平衡,但这类检测器通常需要NMS进行后处理,不仅减慢推理速度,还引入超参数,导致速度和精度不稳定。相比之下,实时检测变压器(RT-DETR)是首个实时端到端目标检测器,它通过基于注意力的尺度内特征交互、基于CNN的跨尺度特征融合和不确定性最小化查询选择,在速度和精度上超越了最强大的YOLO模型,其端到端设计策略使其比YOLO系列模型更适合在无人机平台上部署。
(三)特征融合
特征融合技术旨在结合多尺度特征图以改进目标检测,但不同层次特征之间的语义差距带来挑战,特别是在检测小目标和密集分布目标时。直观的融合方法如对不同层特征图求和或连接,常导致空间特征不对齐。一些基于池化和采样的注意力机制研究尝试解决此问题,但这些方法主要关注空间特征融合,未考虑频域信息。虽有部分工作探索频域融合,但在跨空间和频域的有效多尺度融合方面存在不足。而本文提出的UAV-DETR在空间和频域进行多尺度特征融合,并通过学习偏移量解决特征不对齐问题,提升检测性能。
三、核心工作:UAV-DETR模型
(一)模型架构概述
UAV-DETR基于RT-DETR架构构建,通过三个关键组件进行增强,分别是多尺度特征融合与频率增强模块(MSFF-FE)、频率聚焦下采样模块(FD)和语义对齐与校准模块(SAC)。此外,引入内Scylla交并比(Inner-SIoU)替换广义交并比(GIoU)作为损失函数。
(二)多尺度特征融合与频率增强(MSFF-FE)
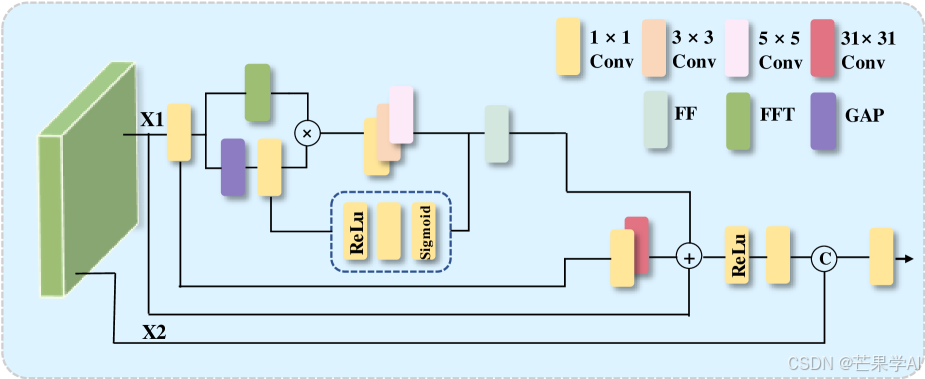
在传统特征融合中,高频分量容易丢失,MSFF-FE模块旨在通过结合多尺度的空间和频域信息来保留小目标细节。该模块采用跨阶段部分策略,将输入特征图 x ∈ R C × H × W x \in \mathbb{R}^{C ×H ×W} x∈RC×H×W划分为两部分: x 1 ∈ R C 1 × H × W x_{1} \in \mathbb{R}^{C_{1} ×H ×W} x1∈RC1×H×W和 x 2 ∈ R C 2 × H × W x_{2} \in \mathbb{R}^{C_{2} ×H ×W} x2∈RC2×H×W ,其中 C 1 = C 4 C_{1}=\frac{C}{4} C1=4C , C 2 = 3 C 4 C_{2}=\frac{3C}{4} C2=43C。
- 特征处理流程:
- 首先, x 1 x_{1} x1经过1×1卷积调整通道维度,再通过GELU激活函数引入非线性,得到 x c o n v x_{conv} xconv。
- 然后,对
x
c
o
n
v
x_{conv}
xconv进行全局平均池化(GAP)操作,接着进行傅里叶变换(F)和逆傅里叶变换(IF),实现频域增强,计算公式为:
x s p = ∣ I F ( C o n v 1 × 1 ( G A P ( x c o n v ) ) ⋅ F ( x c o n v ) ) ∣ x_{sp}=\left|IF\left(Conv_{1 × 1}\left(GAP\left(x_{conv}\right)\right) \cdot F\left(x_{conv}\right)\right)\right| xsp=∣IF(Conv1×1(GAP(xconv))⋅F(xconv))∣ - 为捕获多尺度信息,对
x
s
p
x_{sp}
xsp应用三个不同内核大小的卷积,公式为:
x s c = C o n v 1 × 1 ( x s p ) + C o n v 3 × 3 ( x s p ) + C o n v 5 × 5 ( x s p ) x_{sc}=Conv_{1 × 1}\left(x_{sp}\right)+Conv_{3 × 3}\left(x_{sp}\right)+Conv_{5 × 5}\left(x_{sp}\right) xsc=Conv1×1(xsp)+Conv3×3(xsp)+Conv5×5(xsp) - 之后,通过通道注意力机制进一步优化多尺度特征
x
s
c
x_{sc}
xsc,利用门控机制调制和细化,计算公式为:
x F = α ⋅ I F ( F ( C o n v 1 × 1 ( x s c ) ) ⋅ C o n v 1 × 1 ( x s c ) ) + β ⋅ x s c x_{F}=\alpha \cdot IF\left(F\left(Conv_{1 × 1}\left(x_{sc}\right)\right) \cdot Conv_{1 × 1}\left(x_{sc}\right)\right)+\beta \cdot x_{sc} xF=α⋅IF(F(Conv1×1(xsc))⋅Conv1×1(xsc))+β⋅xsc
其中 α \alpha α和 β \beta β是学习参数,用于平衡空间和频率分量,此公式被称为频率聚焦模块,将在网络后续阶段使用。 - 最后,增强后的特征在与未处理的
x
2
x_{2}
x2合并之前进行最终融合,公式为:
x f i n a l = x 1 + C o n v 31 × 31 ( x c o n v ) + C o n v 1 × 1 ( x c o n v ) + x F x_{final }=x_{1}+Conv_{31 × 31}\left(x_{conv }\right)+Conv_{1 × 1}\left(x_{conv }\right)+x_{F} xfinal=x1+Conv31×31(xconv)+Conv1×1(xconv)+xF
最终输出通过将 x f i n a l x_{final } xfinal与 x 2 x_{2} x2连接,再经过1×1卷积得到。
(三)频率聚焦下采样(FD)
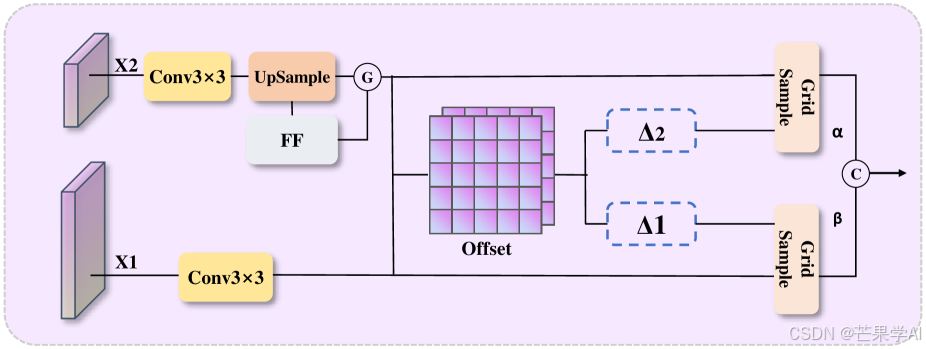
在频率聚焦下采样模块(FD)中:
- 下采样与特征分离:输入特征图 x ∈ R C × H × W x \in \mathbb{R}^{C ×H ×W} x∈RC×H×W首先使用内核大小为2、步长为1的平均池化进行下采样,得到池化后的特征图 x p x_{p} xp,然后将其分为两部分 x 1 x_{1} x1和 x 2 x_{2} x2,并对它们进行并行处理。
- 并行处理路径:
- 对于 x 1 x_{1} x1,使用步长为2、填充为1的3×3卷积进行处理,在降低空间维度的同时保留关键特征,得到 x 1 ′ x_{1}' x1′。
- 对于 x 2 x_{2} x2,一条路径应用频率聚焦模块增强重要特征分量,得到 x f x_{f} xf;另一条路径使用3×3内核、步长为2的最大池化,然后通过1×1卷积减少通道数,得到 x p ′ x_{p}' xp′。
- 输出合并:将 x f x_{f} xf和 x p ′ x_{p}' xp′沿通道维度连接,再通过1×1卷积将通道数减少到所需大小,得到 x 2 ′ x_{2}' x2′。最后,将 x 1 ′ x_{1}' x1′和 x 2 ′ x_{2}' x2′连接形成该模块的最终输出。
(四)语义对齐与校准(SAC)
语义对齐与校准(SAC)模块用于融合和对齐不同融合过程中获得的特征。
- 特征预处理:给定两个输入特征 x 1 ∈ R C 1 × H 1 × W 1 x_{1} \in \mathbb{R}^{C_{1} ×H_{1} ×W_{1}} x1∈RC1×H1×W1和 x 2 ∈ R C 2 × H 2 × W 2 x_{2} \in \mathbb{R}^{C_{2} ×H_{2} ×W_{2}} x2∈RC2×H2×W2,SAC模块首先通过单独的卷积层将通道数统一到公共维度 c c c。然后,使用双线性插值对 x 2 x_{2} x2进行上采样,使其空间维度与 x 1 x_{1} x1匹配。
- 频率增强与融合:为增强
x
2
x_{2}
x2,应用频率聚焦模块,选择性放大高频分量,生成频率增强特征
x
f
r
e
q
x_{freq }
xfreq。之后,将频率增强特征
x
f
r
e
q
x_{freq }
xfreq与原始上采样后的特征
x
2
x_{2}
x2融合,利用门控机制平衡空间和频域的贡献,计算公式为:
x f u s e d = G ( x 2 ) ⋅ x f r e q + ( 1 − G ( x 2 ) ) ⋅ x 2 x_{fused }=G\left(x_{2}\right) \cdot x_{freq }+\left(1-G\left(x_{2}\right)\right) \cdot x_{2} xfused=G(x2)⋅xfreq+(1−G(x2))⋅x2
其中 G G G是学习到的门控函数,用于确保空间和频域信息的自适应融合。 - 特征对齐与融合:为解决
x
1
x_{1}
x1和
x
f
u
s
e
d
x_{fused }
xfused之间的不对齐问题,SAC模块学习2D偏移量
Δ
1
\Delta_{1}
Δ1和
Δ
2
\Delta_{2}
Δ2 ,通过卷积层生成这些偏移量,利用基于网格的采样操作调整特征图的采样网格,以调整特征的空间坐标,确保两个特征对齐,公式为:
x 1 a l i g n e d = G r i d S a m p l e ( x 1 , Δ 1 ) x_{1}^{aligned }=GridSample\left(x_{1}, \Delta_{1}\right) x1aligned=GridSample(x1,Δ1)
x f u s e d a l i g n e d = G r i d S a m p l e ( x f u s e d , Δ 2 ) x_{fused }^{aligned }= GridSample \left(x_{fused }, \Delta_{2}\right) xfusedaligned=GridSample(xfused,Δ2)
最后,使用元素加权求和融合对齐后的特征,公式为:
x o u t p u t = α 1 ⋅ x 1 a l i g n e d + α 2 ⋅ x f u s e d a l i g n e d x_{output }=\alpha_{1} \cdot x_{1}^{aligned }+\alpha_{2} \cdot x_{fused }^{aligned } xoutput=α1⋅x1aligned+α2⋅xfusedaligned
其中 α 1 \alpha_{1} α1和 α 2 \alpha_{2} α2是学习到的注意力权重,用于平衡每个对齐特征的贡献。
(五)损失函数
RT-DETR使用GIoU损失进行边界框回归,在小目标检测时效果不佳,尤其是当交并比(IoU)值较低时。为解决此问题,UAV-DETR采用Inner-SIoU,它结合了Inner-IoU和SCYLLA-IoU(SIoU)。Inner-SIoU将辅助边界框缩放1.25倍以提高灵敏度并加速收敛,像SIoU一样,它添加角度和形状损失以减少角度和距离不匹配。
- Inner-IoU计算:对于给定的预测框
B
i
n
n
e
r
B^{inner }
Binner和真实框
B
g
t
i
n
n
e
r
B_{gt}^{inner}
Bgtinner ,Inner-IoU的计算方式为:
I n n e r − I o U = ∣ B i n n e r ∩ B g t i n n e r ∣ ∣ B i n n e r ∪ B g t i n n e r ∣ Inner-IoU =\frac{\left|B^{inner } \cap B_{gt}^{inner }\right|}{\left|B^{inner } \cup B_{gt}^{inner }\right|} Inner−IoU= Binner∪Bgtinner Binner∩Bgtinner
其中 B i n n e r B^{inner } Binner和 B g t i n n e r B_{gt}^{inner} Bgtinner分别表示扩展后的预测框和真实框,两个框的宽度和高度都缩放1.25倍, ∣ B i n n e r ∩ B g t i n n e r ∣ \left|B^{inner } \cap B_{gt}^{inner }\right| Binner∩Bgtinner 和 ∣ B i n n e r ∪ B g t i n n e r ∣ \left|B^{inner } \cup B_{gt}^{inner }\right| Binner∪Bgtinner 分别表示扩展框之间的重叠面积和并集面积。 - Inner-SIoU损失计算:Inner-SIoU损失定义为:
L I n n e r − S I o U = L S I o U + I o U − I n n e r − S I o U L_{Inner-SIoU }=L_{SIoU}+IoU- Inner-SIoU LInner−SIoU=LSIoU+IoU−Inner−SIoU
其中IoU是标准IoU损失, L S I o U L_{SIoU} LSIoU包括角度、距离和形状惩罚项。
四、实验
(一)实验设置
- 数据集:在两个目标检测数据集上进行定量实验,分别是VisDrone和UAVVaste。
- VisDrone-2019-DET数据集包含6471张训练图像、548张验证图像和3190张测试图像,图像从不同高度、不同地点的无人机拍摄,每张图像标注了10种预定义目标类别的边界框,实验使用其训练集和验证集分别进行训练和测试。
- UAVVaste数据集专为航拍垃圾检测设计,包含772张图像和3716个在城市和自然环境(如街道、公园、草坪)中手动标注的垃圾注释,实验选取其训练集进行训练,测试集进行测试。
- 实现细节:所有模型在NVIDIA GeForce RTX 3090上训练。UAV-DETR模型基于RT-DETR,设计了两种模型尺寸,分别使用ResNet18和ResNet50作为骨干网络。模型训练400个epoch,批次大小为4,采用提前停止机制,耐心值设为20。使用AdamW优化器,学习率为0.0001,动量为0.9。将输入图像缩放至640×640像素,使用RT-DETR模型的数据增强方法,并应用mixup和Mosaic技术,Mosaic概率设为1,mixup概率设为0.2。实验报告标准COCO指标,包括AP(在0.50 - 0.95均匀采样的IoU阈值上平均,步长为0.05)和 A P 50 AP_{50} AP50(IoU阈值为0.50时的AP)。
(二)对比实验
- VisDrone数据集结果:在VisDrone数据集上,UAV-DETR-R18相比基线RT-DETR-R18,AP提升3.1%, A P 50 AP_{50} AP50提升4.2%;UAV-DETR-R50相比基线,AP提升3.1%, A P 50 AP_{50} AP50提升4.1%。UAV-DETR-R18在计算成本低于100 GFLOPs的方法中精度最高,与计算成本相似的其他目标检测器相比,UAV-DETR在精度上也更优,甚至与像PP-YOLOE-P2-Alpha-l这类受益于大量预训练的方法相比,UAV-DETR仍表现出色。
- UAVVaste数据集结果:在UAVVaste数据集上选择UAV-DETR-R18进行评估,因其在计算效率和检测精度间达到最佳平衡,适合在小数据集上评估。与其他模型相比,UAV-DETR仍保持竞争优势,相比基线,AP提升3.3%, A P 50 AP_{50} AP50提升3.6%。结果表明该方法在无人机图像目标检测中可行且有效,且模型性能不受数据量大小影响,不依赖大量标注数据。
(三)消融实验
在VisDrone数据集上使用UAV-DETR-R18进行消融实验,分析每个组件对检测精度的影响。
- 组件影响分析:基线RT-DETR-R18的AP为26.7, A P 50 AP_{50} AP50为44.6。引入Inner-SIoU后,AP提升至27.1,表明改进损失函数对性能有积极影响。添加MSFF-FE模块后,AP进一步提升至28.4,体现了多尺度特征融合和频率增强的优势。加入FD模块使 A P 50 AP_{50} AP50提升至47.1,融入SAC模块后,AP达到28.9, A P 50 AP_{50} AP50提升至47.7。当所有组件结合时,UAV-DETR-R18达到最高性能,AP为29.8, A P 50 AP_{50} AP50为48.8,展示了每个模块对检测精度的累积影响。
- Inner-SIoU参数选择:实验表明,将Inner-SIoU的比例设为1.25是合适的选择。
- 模型性能指标计算:计算基线和UAV-DETR模型的每秒帧数(FPS),结果显示UAV-DETR能够满足实时要求。
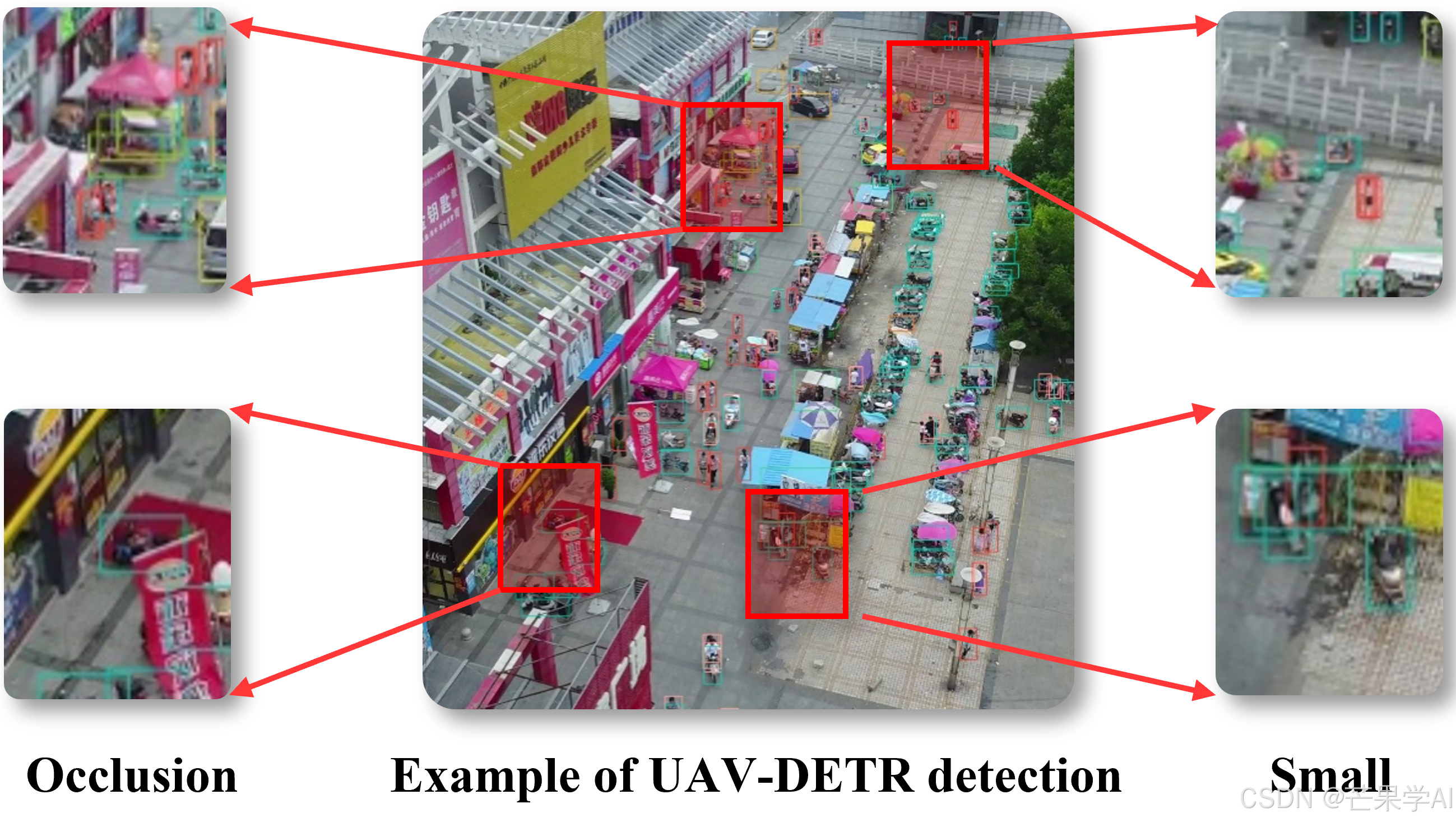
(四)可视化
通过绘制VisDrone数据集中小目标的热图(聚焦于边界框预测的反向传播),对比基线模型和UAV-DETR。结果显示,UAV-DETR在定位小目标方面能力显著提升,其热图中小目标的热值更高,表明能更有效捕获小目标特征,且更关注小目标周围信息,在定位遮挡目标方面表现良好。但模型偶尔会聚焦于无关区域,这是未来需要解决的问题。

(五)讨论
UAV-DETR与其他UAV-OD模型相比有两个关键差异:一是无需NMS和锚框设置,降低了模型部署的复杂性;二是在特征融合中利用了双域信息,使其在相似计算成本下精度更高。
- 性能提升原因:
- 模型保留了更多高频特征,在传统特征融合和下采样过程中高频特征易丢失,而MSFF-FE和FD模块使模型在特征融合和下采样时能结合空间和频域信息,保留重要高频分量,这对检测小目标至关重要。
- 模型能更好地利用上下文信息,当小目标难以基于精细细节检测时,其周围语义上下文很关键,频域操作帮助模型捕获全局模式,提高检测精度。但频域操作可能导致不同特征图的语义和空间信息不对齐,SAC模块通过对齐不同融合路径的特征,提升了整体检测性能,消融实验也证明了这些模块的有效性。
- 研究展望:研究结果表明利用频域信息可提升UAV-OD性能,为UAV-OD任务中更好地使用频率信息提供了思路。未来工作将聚焦于提高模型对噪声的鲁棒性。
五、芒果YOLO系列改进:基于 UAV-DETR 原创改进内容🚀🚀🚀
5.1 将 ARConv 改进到 YOLO11 中 - 基于 UAV-DETR 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLO11改进173:2025年1月最新论文UAV-DETR出品:即插即用:多尺度频率增强模块和频率聚焦下采样模块,无人机图像的高效检测变压器,大幅涨点
5.2 将 ARConv 改进到 YOLOv8 中 - 基于 UAV-DETR 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLOv8改进185:2025年1月最新论文UAV-DETR出品:即插即用:多尺度频率增强模块和频率聚焦下采样模块,无人机图像的高效检测变压器,大幅涨点
5.3 将 ARConv 改进到 YOLOv10 中 - 基于 UAV-DETR 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLOv10改进138:2025年1月最新论文UAV-DETR出品:即插即用:多尺度频率增强模块和频率聚焦下采样模块,无人机图像的高效检测变压器,大幅涨点
5.4 将 ARConv 改进到 RT-DETR 中 - 基于 UAV-DETR 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLOv8改进185:2025年1月最新论文UAV-DETR出品:即插即用:多尺度频率增强模块和频率聚焦下采样模块,无人机图像的高效检测变压器,大幅涨点 适用于 ultralytics 版本的 RT-DETR
5.5 将 ARConv 改进到 YOLOv7 中 - 基于 UAV-DETR 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLOv7原创改进
5.6 将 ARConv 改进到 YOLOv5 中 - 基于 UAV-DETR 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLOv5原创改进


















 131
131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











