







论文名:Very deep convolutional networks for large-scale image recognition
下载地址:https://arxiv.org/pdf/1409.1556.pdf
正文
VGG是在AlexNet的基础上通过增加网络深度达到提高模型性能的目的,在2014年ImageNet竞赛中获得分类第二(第一是GoogLeNet),定位任务第一。
1.原理解析
其实VGG网络模型的设计思想很清晰,主要为了探究网络深度对模型精确度的影响,所以VGG的设计模仿了AlexNet,只是增加了卷基层conv的数量和减小卷积核尺寸,全连接层FC保留了AlexNet的结构,相比于AlexNet,VGG网络有如下优点:
1.卷积层的数量更多,提高模型的准确度
2.采用了较小的卷积核,减少模型的参数,VGG结构中只采用了3x3和1x1的卷积核
2.网络结构
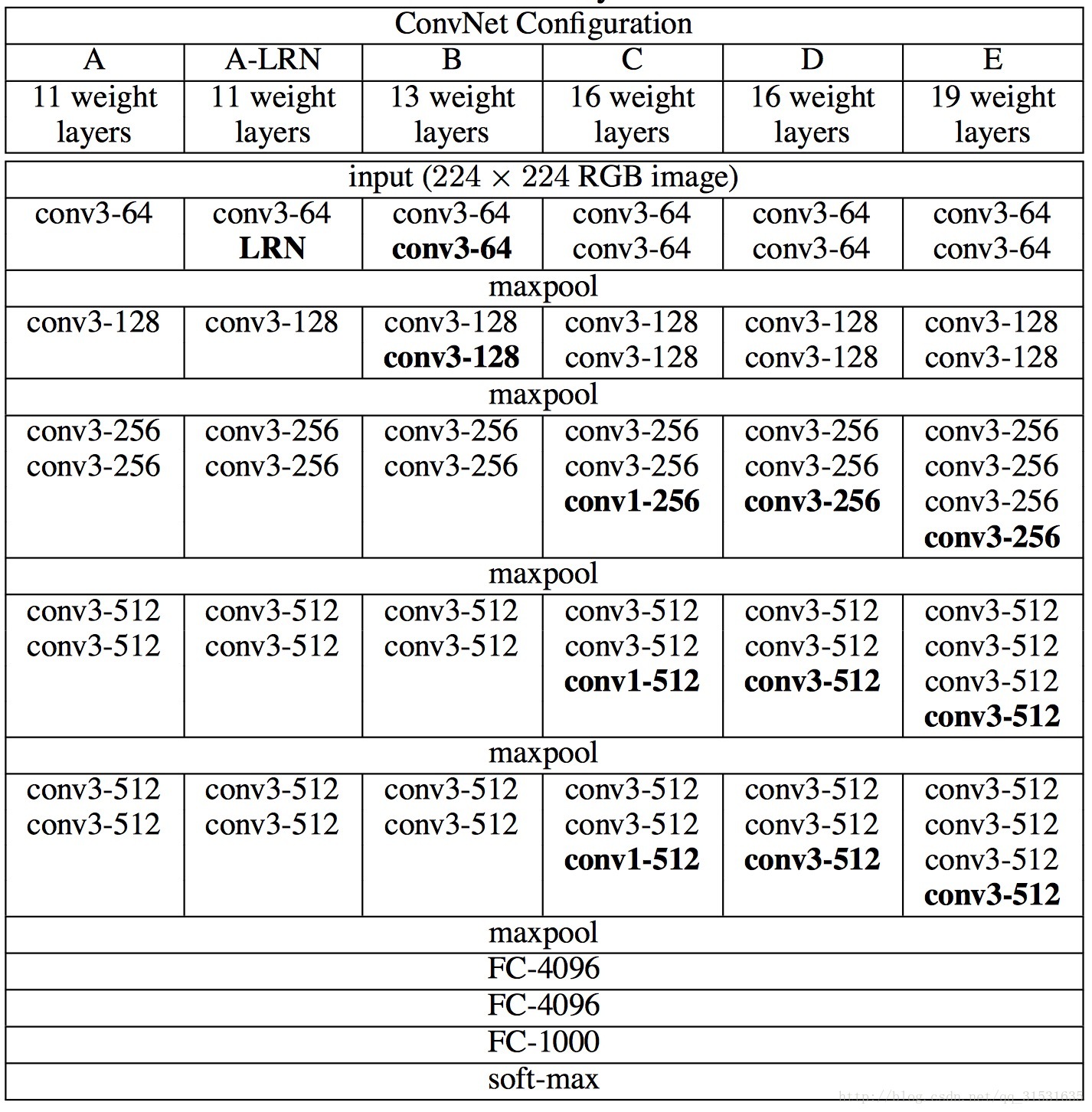
3.网络训练
dropput
增加网络的深度提高了模型的非线性表达能力,网络模型变的复杂,在训练过程中容易导致过拟合。解决这个问题,在当时大多采用dropout的方法;现如今基本已经弃用dropout,BN(batch norm)和数据增强Augmentation是防止过拟合的主要手段
训练技巧
VGG网络的训练是逐层增加的,先训练浅层网络,在训练好的浅层网络基础上增加网络层在进行训练,该论文中的VGG-16和VGG-19就是采用这种方法训练的,这两个模型的性能也是最好的。















 7177
7177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









