










R-CNN系列推演:
每一篇都是前一篇或者前几篇的改造版,所以按顺序看会比较好。
论文题目:Fast R-CNN
下载地址:https://arxiv.org/pdf/1504.08083.pdf
看这篇论文之前建议先过一下下面这两篇论文:
这篇论文是在R-CNN以及SPP的基础上进行的改进,题目写的也非常直白, Fast R-CNN 更快的R-CNN,这篇论文的东西不是很多,精读R-CNN之后我觉得泛读一下这篇就可以了。
R-CNN和SPP模型回顾
SPP是R-CNN的改进版,这篇论文是基于R-CNN和SPP写的,所以先回顾一下这俩模型,完整的精读泛读可以看上面的连接,懒得看的直接看下面的表格,一目了然。
| R-CNN | SPP |
|---|---|
| 一张图片提取2000个候选框 ,并强制缩放到固定尺寸后送给CNN | 整张图片直接送给CNN |
| CNN提取每个候选框的feature map | CNN得到整张图的feature map,通过SS得到候选区域与feature map直接映射得到特征向量 |
| 将CNN提取的feature map 送给SVM分类,送给BB回归进行定位修复 | 映射的特征向量给SSP,SSP输出固定大小的特征向量,再给 FC,再SVM+回归 |
Fast R-CNN提出背景
R-CNN有诸多缺点,比如训练速度慢,需要多阶段,重复计算等等。即使改进之后的SPP虽然不需要先提取2000个候选框了,也不需要固定输入大小了,但也没有办法逃脱多阶段的训练模式。
这两个模式都需要feature map,将其存储在磁盘上,并且都需要SVM+BB回归。
所以就有几个大问题待解决,训练速度的问题,存储空间占用的问题,目标识别过程慢的问题(R-CNN在GPU上要47秒)。
作者提出的改进方法
ROI池化
关于ROI:
region of interest,可以理解为特征图上的框,在Fast RCNN中, RoI是指Selective Search完成后得到的“候选框”在特征图上的映射,在Faster RCNN中,候选框是经过RPN产生的,然后再把各个“候选框”映射到特征图上,得到RoIs。
在之前的SPP和R-CNN论文中已经说过,全连接需要固定尺寸的输入,R-CNN的做法是直接强制变换输入图片尺寸固定为227 * 227。 SPP的做法是不强制变换输入尺寸,在CNN之后加入SPP金字塔池化结构,SPP可以输出固定尺寸的大小给FC。
作者在本文中提出使用ROI 池化做法代替SPP模块。
ROI 池化具体操作:
- 1.首先,RoI 池化层将接收卷积特征图作为输入;
- 2.针对每一个输入图像中的 RoI,在卷积特征图中得到映射区域;
- 3.将这个 RoI 进行区域分割为 H×W 的网格,以 7×7 为例,则将从 RoI 的-映射区域中划分出 49 个分割区域;
- 4.在每个区域中进行 max pooling 操作,即选出区域最大值;
- 5.提取 7×7 的 RoI 特征图。
在知乎上看到一个动图可以帮助理解:

每个 RoI 在输入时具有四个信息(r, c, h, w),其中 r 和 c 代表 RoI 方格区域左上角的顶点左边,用来表征位置坐标,h 和 w 则分别代表 RoI 区域方格的长度和宽度。
因此采用 RoI pooling 无论输入过程中 RoI 的大小,输出都是固定大小的feature map,同时加速了处理速度。
Multi-task loss
SSP正向传播需要处理整个ROI的感受野,这是非常低效的,作者提出了一种新的方法,可以在训练期间共享特征。
一个minibatch的R个RoI来源于N张图片,即从每张图片中采样R/N个RoIs,而来自同一张图片的RoI在前向和反向传播中可以贡献计算和内存,通常N=2,R=128,这样的训练方案通常要比从128张不同图片中采样快64倍,加快了速度还节约了内存。
另一个就是SPP中有多级的训练过程,就是单独训练SVM和BB的那一块,这里作者提出了整合的方法,就是将分类和回归放到一个网络里,他们共享loss。
Fast R-CNN将不再使用SVM作为分类器,而是直接用softmax。
softmax层用于分类,输出K+1维数组p,表示属于K类和背景的概率。
bbx层用于调整候选区域位置,输出4*K维数组t,表示分别属于K类时,应该平移缩放的参数。
截断的SVD
作者继续思考可以加速他模型的方法,在普通的分类任务里,就是CNN提取特征最后加全连接,基本上走一边全连接就行了,而在目标检测任务中,要处理很多候选框,就是上面提到的ROI,每一个候选框都得走一边全连接,在向前传播中很多的时间花费在了全连接层的计算上,进而提出了截断的SVD分解加速全连接层计算的策略。
关于SVD,就全是数学了,感兴趣的可以看一下,SVD原理详解。
Fast R-CNN整体结构
整合上面的思路提出了Fast R-CNN模型图:
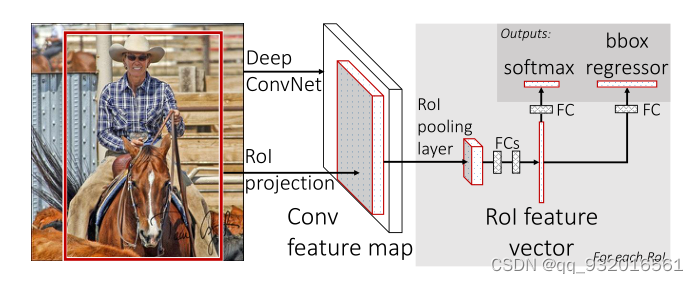
抽象之后的流程图:
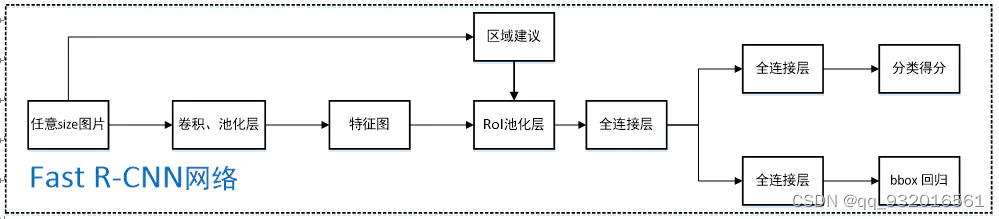
步骤:
- 1.将整个图片和一组候选框输入CNN(卷积+池化)。
- 2.CNN提取出来feature map。
- 3.对每个候选框,使用Rol池化层从feature map中提取固定长度的特征向量。
- 4.将特征向量送入全连接。
- 5.全连接之后送入softmax进行分类。
- 6.全连接之后的另外一条路是送入bounding-box回归(BB)修正候选框位置。
5和6这两个步骤是并列的输出层,就是在上面说到的合并loss的操作方法。
小总结
这篇论文在最后有很多问答式的小章节我觉得挺有意思,在之前看的论文中很少出现,总结一下问答中的几个点:
- 多尺度训练虽然在精度上有一定提升,但时间代价也比较大。
- Softmax略优于SVM。
- 深度神经网络分类器使用更多的候选区域没有帮助,甚至稍微有点影响准确性。
其实可以发现,本文模型FRCN的候选框提取依旧使用的是SS算法,这和之前的R-CNN和 SPP是一样的,非常耗时。
更新一下对比表格:
| R-CNN | SPP | Fast R-CNN |
|---|---|---|
| 一张图片提取2000个候选框 ,并强制缩放到固定尺寸后送给CNN | 整张图片直接送给CNN | 整张图片+一组候选框送给CNN |
| CNN提取每个候选框的feature map | CNN得到整张图的feature map,通过SS得到候选区域与feature map直接映射得到特征向量 | CNN得到feature map 通过ROI池化层得到特征向量 |
| 将CNN提取的feature map 送给SVM分类,送给BB回归进行定位修复 | 映射的特征向量给SSP,SSP输出固定大小的特征向量,再给 FC,再SVM+回归 | 特征向量送入FC 再接 一个合并网络(softmax分类+BB回归) |

















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











