








何为模型
- 状态转移概率:
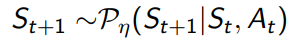
- 状态价值奖励:
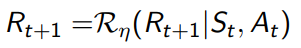
我们通常假设状态转移和价值之间是独立的
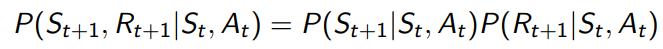
如何学到模型
通过环境交互,behavior policy采样一系列状态转移{S1,A1,R2,…,ST},使用监督的办法学习状态转移和价值函数。

模型的种类
Table Lookup Model
Linear Expectation Model
Linear Gaussian Model
Gaussian Process Model
Deep Belief Network Model …
Table lookup Model
就是数数,是说采样了若干条轨迹,先计算有多少个(s,a)状态对,然后再分别计算这些状态对中转移到某个状态s’的个数和得到的奖励总和,在用这些个数和奖励总和除以状态对数得到概率转移模型和奖励模型。


寻找最优策略算法
在基于环境的RL中,我们把采样来源分为Real experience和Simulated experience,Real experience来源于真实模型即环境,Simulated experience来源于我们学习的模型。
value-base Dyna算法
Dyna算法是从环境学习到一个模型,然后在真实模型和学习到的模型中学习价值函数。
policy-base 算法
与控制论紧密相关,例如下面这个算法:

这里第二步是通过强监督训练来找到模型f(s,a),然后第三步用LQR可以求解最优的轨迹。
改进1:
执行第三步(算法1中)得到动作,得到{s,a,s’}加入集合D中继续优化模型,一直如此形成一个循环。
为了克服漂移,偏离最优轨迹。

改进2:
第三步得到动作(算法1中)后,我们只执行一步,得到的状态价值对加入集合D中,然后再重复第三步(算法1中),还是执行第一步,并加入集合D,依次循环。
改进1中在优化模型之前就执行第三步的操作,这就导致一开始就离我们的最优轨迹非常远。

最后得到学习模型和策略相结合的算法:

环境模型
大型神经网络,线性高斯动态函数。















 35
35











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









