






学习了扩散模型从原理到实战-异步社区-致力于优质IT知识的出版和分享 (epubit.com)这本教材后,对教材里所提的内容进行了自我消化,总结总结。
1. 扩散模型的基本原理

扩散模型简单来说分为2个过程:
- 退化过程:也有人叫做向前过程,就是在原有输入(X0)的基础上,按照一定的步长间隔(t)不断地添加随机噪声(ρ),直到最终得到一张纯噪声(XT)。
- 采样过程:就是一个去噪的过程,训练一个神经网络去逐渐地(t)从一张纯噪声(XT)中消除噪声(ρ),直到得到一张真正的图片(X0)。
扩散模型的本质是预测噪声,对一张具有噪声的输入量通过预测噪声进行逐步去噪,直至还原的过程。
扩散模型的数学推导过程有很多人介绍,可以参考【diffusion】扩散模型详解!理论+代码!_副本 - 飞桨AI Studio星河社区 (baidu.com),有较为详细的数学推导过程。但是对于我这种喜欢编程但是数学基础不好的初学者来说,更喜欢先调试和读懂好别人的程序代码,再去理解其数学原理。
2. 基于UNet搭建Diffusion Model(MNIST数据集)
(1)环境准备:先确保自己的环境中安装了如下Python包。建议使用Anaconda创建虚拟环境来管理,使用的是Pytorch GPU版本。建议使用GPU计算,否则算力不足程序跑的时间会很长。
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") #如果没有GPU则使用CPU
print(f'Using device: {device}')(2)数据集的导入和测试
MNIST数据集是个小型的经典数据集,包括0-9的手写数字图像。
dataset = torchvision.datasets.MNIST(root="mnist/", train=True, download=True, transform=torchvision.transforms.ToTensor())
#下载MNIST数据集到mnist文件夹中,设置为训练集
train_dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
#使用DataLoader将dataset设置乱序(shuffle),批处理量:8张
x, y = next(iter(train_dataloader))#取出第一个批次的X、Y
print('Input shape:', x.shape)
print('Labels:', y)
print(torchvision.utils.make_grid(x)[0].shape)
plt.imshow(torchvision.utils.make_grid(x)[0], cmap='Greys')
plt.show()运行结果如下:
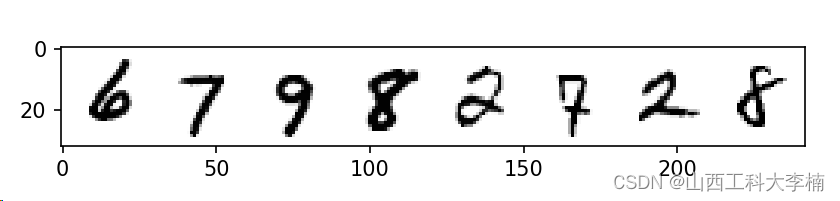
Using device: cuda
Input shape: torch.Size([8, 1, 28, 28])
Labels: tensor([6, 7, 9, 8, 2, 7, 2, 8])
torch.Size([32, 242])3. 扩散模型:退化过程
退化过程就是向内容假如噪声,一般加的是高斯噪声。但是如果想控制每次假如噪声的量,可以引入一个参数(amount)进行控制,代码如下:
noise = torch.rand_like(x) #生成高斯噪声
noise_x = x*(1-amount) + noise*amount #按照amount比例添加噪声当amount=0时,不添加任何高斯噪声;当amount=1时,将得到一个纯噪声。控制amount在0~1之间就能够实现内容X与噪声noise的混合。
使用corrupt(退化)函数对上述代码进行封装:注意张量形状:
#根据amount为输入x添加噪声,退化过程
def corrupt(x, amount):
noise = torch.rand_like(x) #根据X的Size生成一张0~1的张量,高斯分布
amount = amount.view(-1, 1, 1, 1) # 整理amount的形状,符合张量要求
return x*(1-amount) + noise*amount对添加了噪声的X的输出结果进行可视化,代码如下:
# 绘制输入数据:X为8张MNIST图片
fig, axs = plt.subplots(2, 1, figsize=(12, 5))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0], cmap='Greys')
# 添加噪声
amount = torch.linspace(0, 1, x.shape[0]) # amount包含8个数值,0-1逐步增强。
noised_x = corrupt(x, amount) #8张图片按次序逐步增强噪声
# 绘制添加噪声后的图像
axs[1].set_title('Corrupted data (-- amount increases -->)')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0], cmap='Greys')
plt.show()运行结果如下:
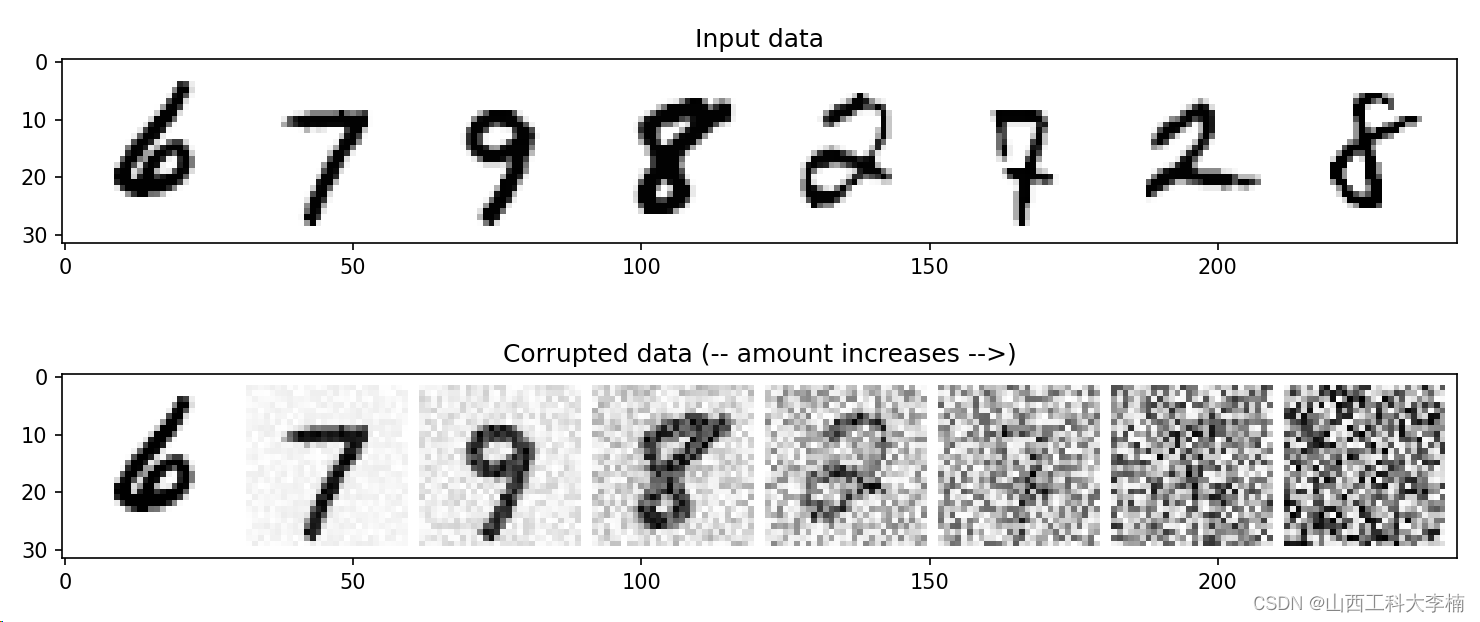
4. 扩散模型训练:
基于退化过程形成的带噪声数据,可以用于扩散模型的训练。扩散模型使用的是UNet网络,其结构图如下:
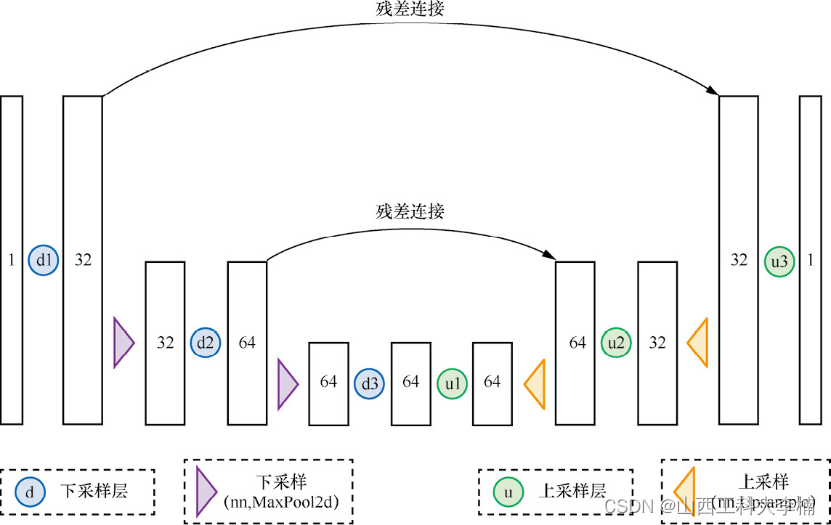
这个是UNet的基础结构,按照这个结构可以构造的UNet网络。代码如下:
class BasicUNet(nn.Module):
"""A minimal UNet implementation."""
def __init__(self, in_channels=1, out_channels=1):
super().__init__()
self.down_layers = torch.nn.ModuleList([
nn.Conv2d(in_channels, 32, kernel_size=5, padding=2),
nn.Conv2d(32, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 64, kernel_size=5, padding=2),
])
self.up_layers = torch.nn.ModuleList([
nn.Conv2d(64, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 32, kernel_size=5, padding=2),
nn.Conv2d(32, out_channels, kernel_size=5, padding=2),
])
self.act = nn.SiLU() # The activation function
self.downscale = nn.MaxPool2d(2)
self.upscale = nn.Upsample(scale_factor=2)
def forward(self, x):
h = []
for i, l in enumerate(self.down_layers):
x = self.act(l(x)) # 通过运算层和激活函数
if i < 2: # 除了第3层(最后一层)以外的层
h.append(x) # 排列残差连接使用的数据
x = self.downscale(x) # 下采样:最大池化,匹配下一层的输入
for i, l in enumerate(self.up_layers):
if i > 0: # 选择除了第1个上采样层以外的层
x = self.upscale(x) # Upscale上采样
x += h.pop() # 得到之前排列好的供残差连接使用的数据
x = self.act(l(x)) # 通过运算层和激活函数
return x
【1】针对nn.Conv2d(in_channels, 32, kernel_size=5, padding=2)做个记录和解释:
- in_channel:1输入图像通道数为1。对于灰度图像来说,通道数为1;对于RGB图像,通道数为3。
- out_channel32:这个数字表示输出特征图(卷积后的图像)的通道数。这里指的是,使用32个不同的卷积核来处理输入图像,每个卷积核生成一个特征图,因此总共有32个输出通道。
- kernel_size=5:这表示卷积核的大小为5x5。卷积核是滑过输入图像的一个小窗口,用于提取局部特征。
- padding=2:在卷积操作之前,会在输入图像的边缘周围添加2个像素的填充(padding)。这样做的目的是为了让卷积操作输出的特征图大小不会因为卷积而变小,或者只缩小很少。具体缩小多少取决于卷积核大小、步长等因素。
【2】激活函数用的是SILU函数:参看:【常用激活函数】Sigmiod | Tanh | ReLU | Leaky ReLU|GELU - 知乎 (zhihu.com)
![]()
【3】downscale:下采样层在经过卷积后使用最大池化。
【4】upscale:上采样采用了nn.Upsample()方法。用法可以参考nn.Upsample-CSDN博客。nn.Upsample是 PyTorch 中用于实现上采样(即放大特征图尺寸)的一个模块。上采样是一种常见的操作,特别是在深度学习中的图像处理任务,比如图像分割(如U-Net架构)和生成对抗网络(GANs)中,可以通过不同的方式实现上采样,包括最近邻插值、线性插值、双线性插值(对于2D数据),三次插值等。例如:
# 定义一个上采样层,选择上采样的尺寸或放大比例
# 例如,scale_factor=2将会把输入的高度和宽度都放大两倍
# mode定义了插值方法,如双线性插值
upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)定义好UNet网络后我们开始对网络进行训练:
# Dataloader (you can mess with batch size)
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# How many runs through the data should we do?
n_epochs = 10
# Create the network
net = BasicUNet()
net.to(device)
# Our loss finction
loss_fn = nn.MSELoss() #损失函数:均方误差损失
# The optimizer
opt = torch.optim.Adam(net.parameters(), lr=1e-3) #制定优化器:Adam优化器;更新参数的算法称为优化器
# Keeping a record of the losses for later viewing
losses = [] #损失值记录
# The training loop
for epoch in range(n_epochs):
for x, y in train_dataloader:
# Get some data and prepare the corrupted version
x = x.to(device) # Data on the GPU
noise_amount = torch.rand(x.shape[0]).to(device) # Pick random noise amounts
noisy_x = corrupt(x, noise_amount) # Create our noisy x
# Get the model prediction:得到预测值
pred = net(noisy_x)
# Calculate the loss:计算损失并比较
loss = loss_fn(pred, x) # How close is the output to the true 'clean' x?
# Backprop and update the params:更新参数:反向传播
opt.zero_grad()
loss.backward()
opt.step()
# Store the loss for later:记录损失值
losses.append(loss.item())
# Print our the average of the loss values for this epoch:
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss:05f}')
# View the loss curve
plt.plot(losses)
plt.ylim(0, 0.1);
plt.show()损失值运行结果如下图:
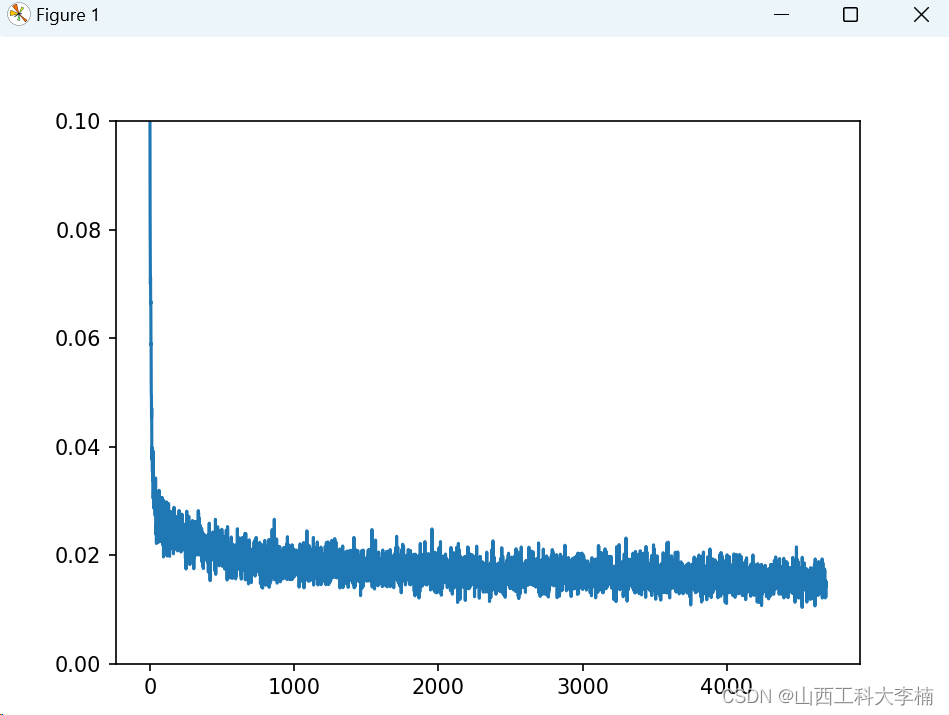

5. 扩散模型:带噪数据预测
训练好的模型可以进行预测。我们选取了数据集中的8条数据,并人为添加不同程度的噪声,使用训练好的BasicUnet模型进行预测,得到了预测结果,完成了基于BasicUNet的扩散模型算法的搭建。代码如下:
#### 带噪数据预测 ############
#取出数据集中8条数据
x, y = next(iter(train_dataloader))
x = x[:8] # Only using the first 8 for easy plotting
#对8条数据随机添加噪声:(0-1)之间增加退化量
# Corrupt with a range of amounts
amount = torch.linspace(0, 1, x.shape[0]) # Left to right -> more corruption
noised_x = corrupt(x, amount)
# Get the model predictions
with torch.no_grad(): #禁用梯度计算:训练好的模型使用禁用梯度计算提高速度
preds = net(noised_x.to(device)).detach().cpu() #阻断反向传播的,经过detach()方法后,变量仍然在GPU上,再利用.cpu()将数据移至CPU中进行后续操作
# Plot
fig, axs = plt.subplots(3, 1, figsize=(12, 7))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0].clip(0, 1), cmap='Greys')
axs[1].set_title('Corrupted data')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0].clip(0, 1), cmap='Greys')
axs[2].set_title('Network Predictions')
axs[2].imshow(torchvision.utils.make_grid(preds)[0].clip(0, 1), cmap='Greys');
plt.show()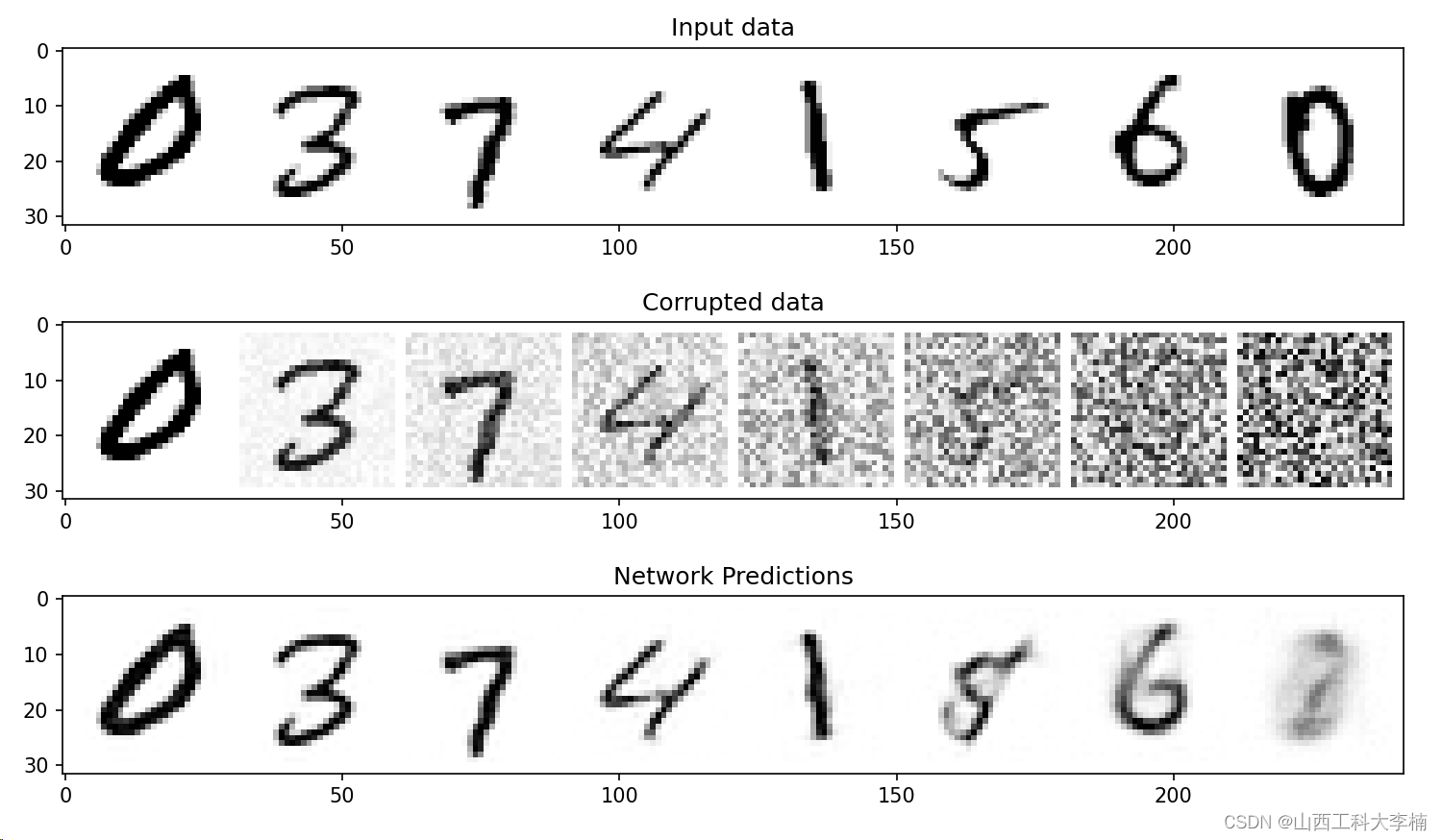















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









